 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHC-GST: Heterophily-aware Distribution Consistency based Graph Self-training
Paper and Code
Jul 25, 2024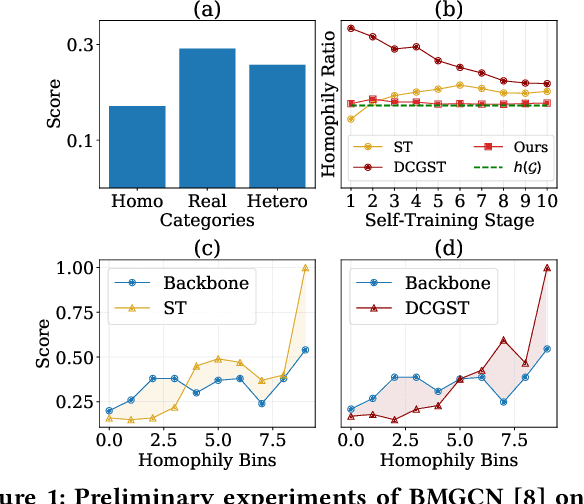
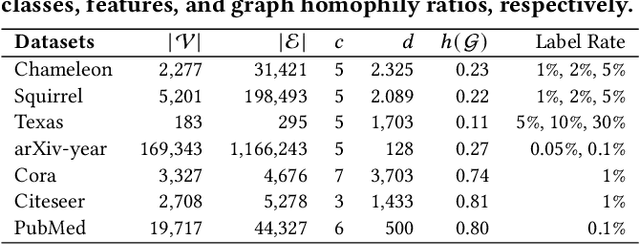
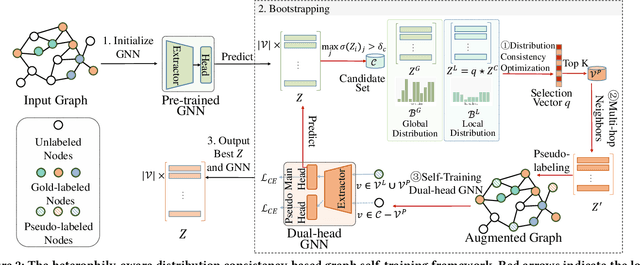
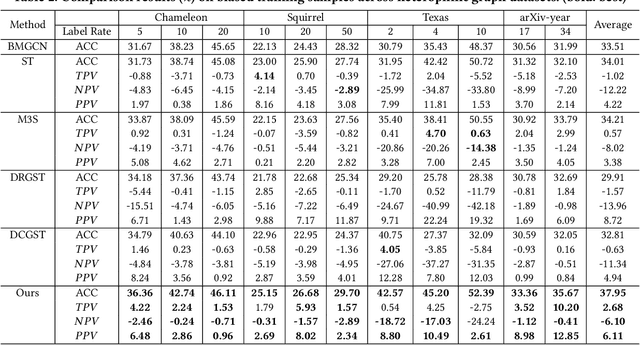
Graph self-training (GST), which selects and assigns pseudo-labels to unlabeled nodes, is popular for tackling label sparsity in graphs. However, recent study on homophily graphs show that GST methods could introduce and amplify distribution shift between training and test nodes as they tend to assign pseudo-labels to nodes they are good at. As GNNs typically perform better on homophilic nodes, there could be potential shifts towards homophilic pseudo-nodes, which is underexplored. Our preliminary experiments on heterophilic graphs verify that these methods can cause shifts in homophily ratio distributions, leading to \textit{training bias} that improves performance on homophilic nodes while degrading it on heterophilic ones. Therefore, we study a novel problem of reducing homophily ratio distribution shifts during self-training on heterophilic graphs. A key challenge is the accurate calculation of homophily ratios and their distributions without extensive labeled data. To tackle them, we propose a novel Heterophily-aware Distribution Consistency-based Graph Self-Training (HC-GST) framework, which estimates homophily ratios using soft labels and optimizes a selection vector to align pseudo-nodes with the global homophily ratio distribution. Extensive experiments on both homophilic and heterophilic graphs show that HC-GST effectively reduces training bias and enhances self-training performance.