 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAPEX: Learning Adaptive Priorities for Multi-Objective Alignment in Vision-Language Generation
Jan 10, 2026Multi-objective alignment for text-to-image generation is commonly implemented via static linear scalarization, but fixed weights often fail under heterogeneous rewards, leading to optimization imbalance where models overfit high-variance, high-responsiveness objectives (e.g., OCR) while under-optimizing perceptual goals. We identify two mechanistic causes: variance hijacking, where reward dispersion induces implicit reweighting that dominates the normalized training signal, and gradient conflicts, where competing objectives produce opposing update directions and trigger seesaw-like oscillations. We propose APEX (Adaptive Priority-based Efficient X-objective Alignment), which stabilizes heterogeneous rewards with Dual-Stage Adaptive Normalization and dynamically schedules objectives via P^3 Adaptive Priorities that combine learning potential, conflict penalty, and progress need. On Stable Diffusion 3.5, APEX achieves improved Pareto trade-offs across four heterogeneous objectives, with balanced gains of +1.31 PickScore, +0.35 DeQA, and +0.53 Aesthetics while maintaining competitive OCR accuracy, mitigating the instability of multi-objective alignment.
Geometric Hyena Networks for Large-scale Equivariant Learning
May 28, 2025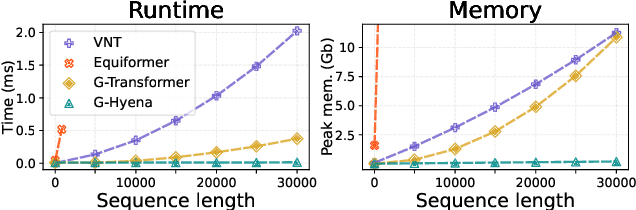
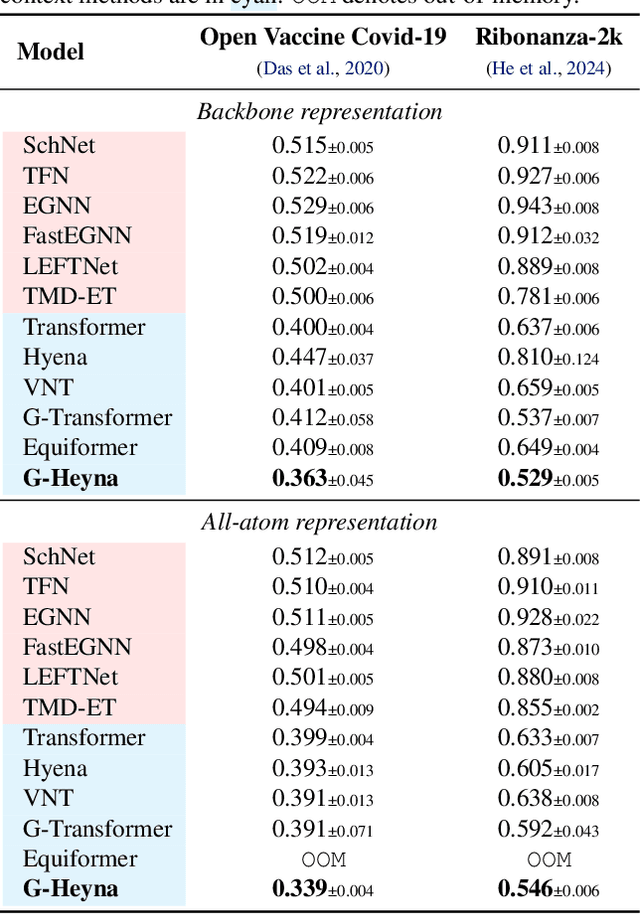
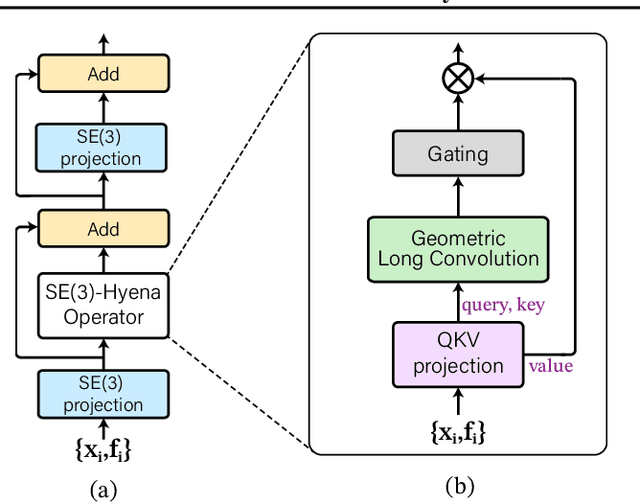
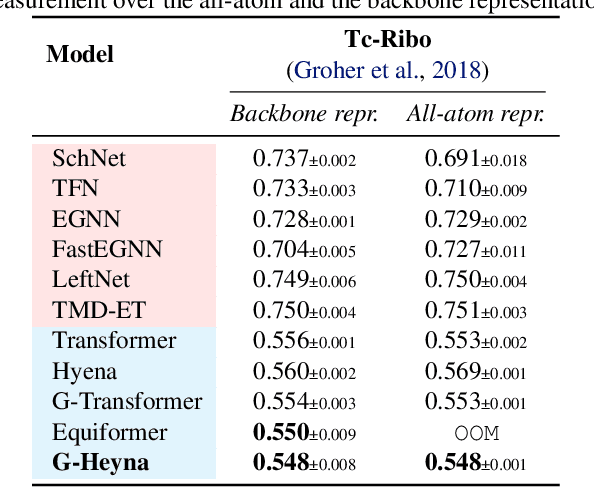
Processing global geometric context while preserving equivariance is crucial when modeling biological, chemical, and physical systems. Yet, this is challenging due to the computational demands of equivariance and global context at scale. Standard methods such as equivariant self-attention suffer from quadratic complexity, while local methods such as distance-based message passing sacrifice global information. Inspired by the recent success of state-space and long-convolutional models, we introduce Geometric Hyena, the first equivariant long-convolutional model for geometric systems. Geometric Hyena captures global geometric context at sub-quadratic complexity while maintaining equivariance to rotations and translations. Evaluated on all-atom property prediction of large RNA molecules and full protein molecular dynamics, Geometric Hyena outperforms existing equivariant models while requiring significantly less memory and compute that equivariant self-attention. Notably, our model processes the geometric context of 30k tokens 20x faster than the equivariant transformer and allows 72x longer context within the same budget.
LanP: Rethinking the Impact of Language Priors in Large Vision-Language Models
Feb 17, 2025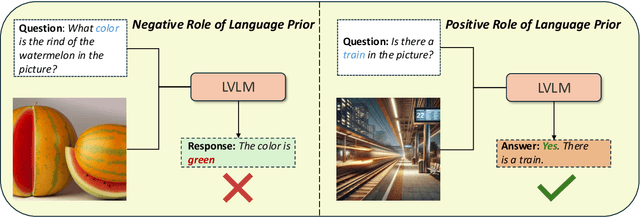
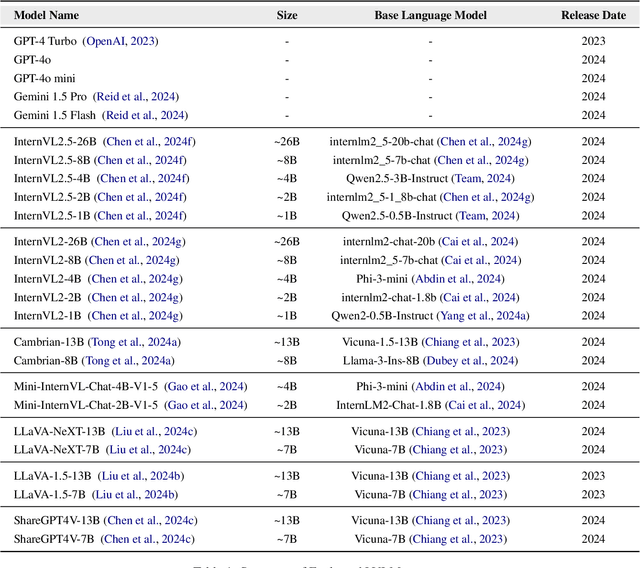
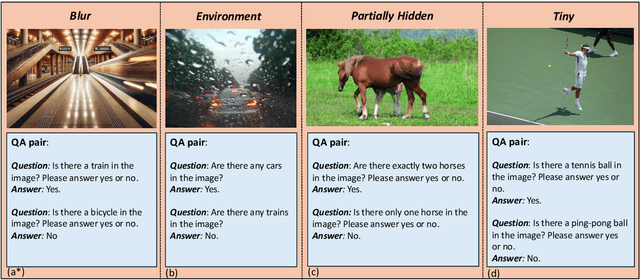
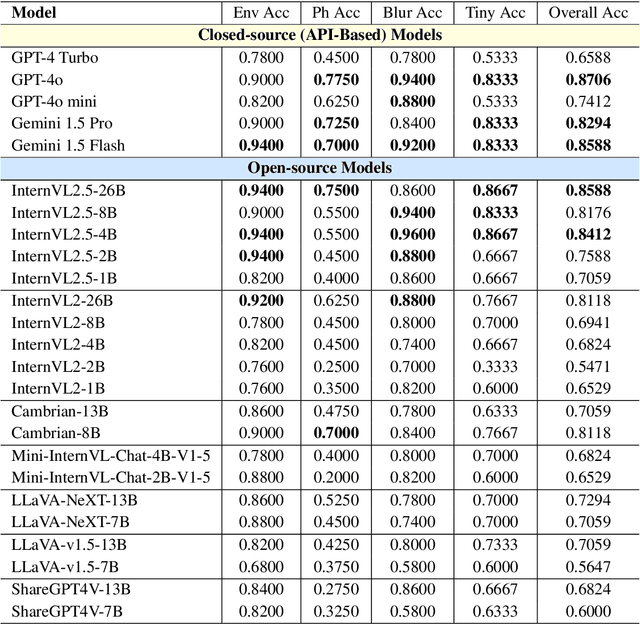
Large Vision-Language Models (LVLMs) have shown impressive performance in various tasks. However, LVLMs suffer from hallucination, which hinders their adoption in the real world. Existing studies emphasized that the strong language priors of LVLMs can overpower visual information, causing hallucinations. However, the positive role of language priors is the key to a powerful LVLM. If the language priors are too weak, LVLMs will struggle to leverage rich parameter knowledge and instruction understanding abilities to complete tasks in challenging visual scenarios where visual information alone is insufficient. Therefore, we propose a benchmark called LanP to rethink the impact of Language Priors in LVLMs. It is designed to investigate how strong language priors are in current LVLMs. LanP consists of 170 images and 340 corresponding well-designed questions. Extensive experiments on 25 popular LVLMs reveal that many LVLMs' language priors are not strong enough to effectively aid question answering when objects are partially hidden. Many models, including GPT-4 Turbo, exhibit an accuracy below 0.5 in such a scenario.
Aesthetic Matters in Music Perception for Image Stylization: A Emotion-driven Music-to-Visual Manipulation
Jan 03, 2025



Emotional information is essential for enhancing human-computer interaction and deepening image understanding. However, while deep learning has advanced image recognition, the intuitive understanding and precise control of emotional expression in images remain challenging. Similarly, music research largely focuses on theoretical aspects, with limited exploration of its emotional dimensions and their integration with visual arts. To address these gaps, we introduce EmoMV, an emotion-driven music-to-visual manipulation method that manipulates images based on musical emotions. EmoMV combines bottom-up processing of music elements-such as pitch and rhythm-with top-down application of these emotions to visual aspects like color and lighting. We evaluate EmoMV using a multi-scale framework that includes image quality metrics, aesthetic assessments, and EEG measurements to capture real-time emotional responses. Our results demonstrate that EmoMV effectively translates music's emotional content into visually compelling images, advancing multimodal emotional integration and opening new avenues for creative industries and interactive technologies.
Stealing Training Graphs from Graph Neural Networks
Nov 17, 2024


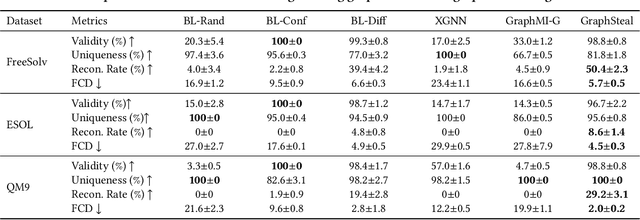
Graph Neural Networks (GNNs) have shown promising results in modeling graphs in various tasks. The training of GNNs, especially on specialized tasks such as bioinformatics, demands extensive expert annotations, which are expensive and usually contain sensitive information of data providers. The trained GNN models are often shared for deployment in the real world. As neural networks can memorize the training samples, the model parameters of GNNs have a high risk of leaking private training data. Our theoretical analysis shows the strong connections between trained GNN parameters and the training graphs used, confirming the training graph leakage issue. However, explorations into training data leakage from trained GNNs are rather limited. Therefore, we investigate a novel problem of stealing graphs from trained GNNs. To obtain high-quality graphs that resemble the target training set, a graph diffusion model with diffusion noise optimization is deployed as a graph generator. Furthermore, we propose a selection method that effectively leverages GNN model parameters to identify training graphs from samples generated by the graph diffusion model. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed framework in stealing training graphs from the trained GNN.
A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness
Nov 04, 2024Large language models (LLM) have demonstrated emergent abilities in text generation, question answering, and reasoning, facilitating various tasks and domains. Despite their proficiency in various tasks, LLMs like LaPM 540B and Llama-3.1 405B face limitations due to large parameter sizes and computational demands, often requiring cloud API use which raises privacy concerns, limits real-time applications on edge devices, and increases fine-tuning costs. Additionally, LLMs often underperform in specialized domains such as healthcare and law due to insufficient domain-specific knowledge, necessitating specialized models. Therefore, Small Language Models (SLMs) are increasingly favored for their low inference latency, cost-effectiveness, efficient development, and easy customization and adaptability. These models are particularly well-suited for resource-limited environments and domain knowledge acquisition, addressing LLMs' challenges and proving ideal for applications that require localized data handling for privacy, minimal inference latency for efficiency, and domain knowledge acquisition through lightweight fine-tuning. The rising demand for SLMs has spurred extensive research and development. However, a comprehensive survey investigating issues related to the definition, acquisition, application, enhancement, and reliability of SLM remains lacking, prompting us to conduct a detailed survey on these topics. The definition of SLMs varies widely, thus to standardize, we propose defining SLMs by their capability to perform specialized tasks and suitability for resource-constrained settings, setting boundaries based on the minimal size for emergent abilities and the maximum size sustainable under resource constraints. For other aspects, we provide a taxonomy of relevant models/methods and develop general frameworks for each category to enhance and utilize SLMs effectively.
Beyond Sequence: Impact of Geometric Context for RNA Property Prediction
Oct 15, 2024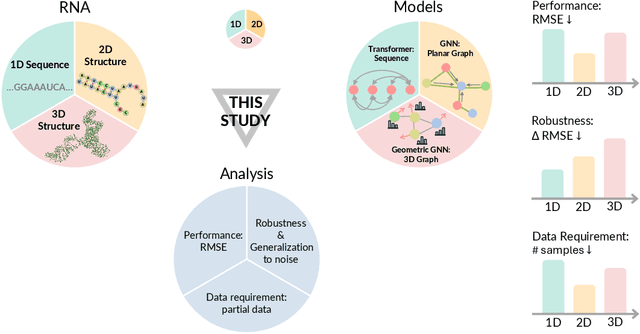
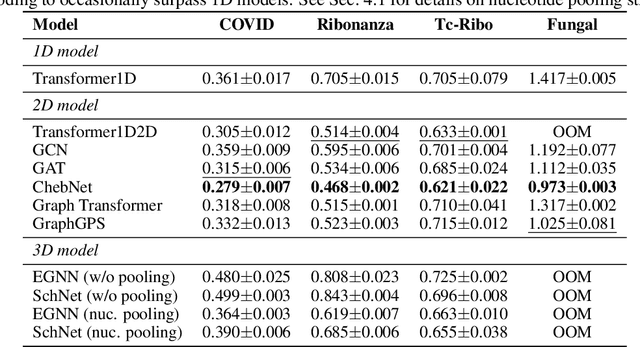
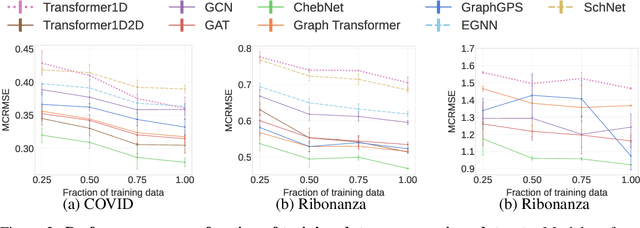

Accurate prediction of RNA properties, such as stability and interactions, is crucial for advancing our understanding of biological processes and developing RNA-based therapeutics. RNA structures can be represented as 1D sequences, 2D topological graphs, or 3D all-atom models, each offering different insights into its function. Existing works predominantly focus on 1D sequence-based models, which overlook the geometric context provided by 2D and 3D geometries. This study presents the first systematic evaluation of incorporating explicit 2D and 3D geometric information into RNA property prediction, considering not only performance but also real-world challenges such as limited data availability, partial labeling, sequencing noise, and computational efficiency. To this end, we introduce a newly curated set of RNA datasets with enhanced 2D and 3D structural annotations, providing a resource for model evaluation on RNA data. Our findings reveal that models with explicit geometry encoding generally outperform sequence-based models, with an average prediction RMSE reduction of around 12% across all various RNA tasks and excelling in low-data and partial labeling regimes, underscoring the value of explicitly incorporating geometric context. On the other hand, geometry-unaware sequence-based models are more robust under sequencing noise but often require around 2-5x training data to match the performance of geometry-aware models. Our study offers further insights into the trade-offs between different RNA representations in practical applications and addresses a significant gap in evaluating deep learning models for RNA tasks.
Multi-Type Preference Learning: Empowering Preference-Based Reinforcement Learning with Equal Preferences
Sep 11, 2024

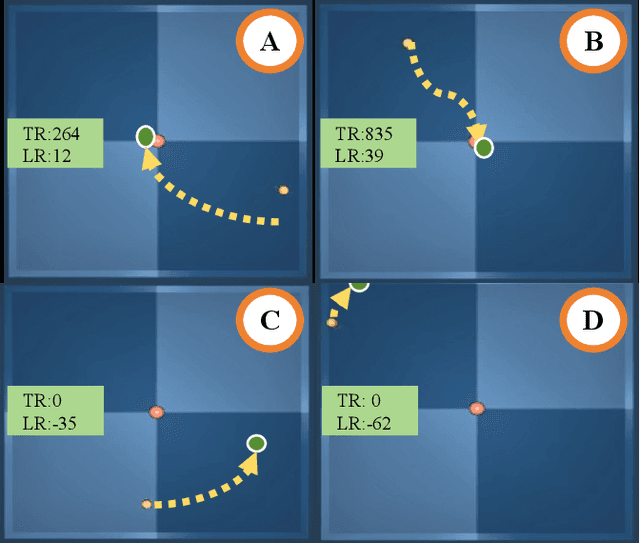
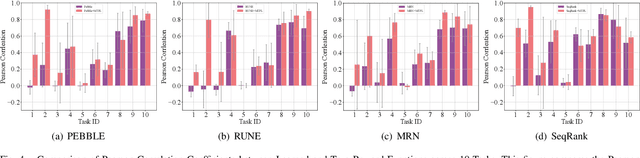
Preference-Based reinforcement learning (PBRL) learns directly from the preferences of human teachers regarding agent behaviors without needing meticulously designed reward functions. However, existing PBRL methods often learn primarily from explicit preferences, neglecting the possibility that teachers may choose equal preferences. This neglect may hinder the understanding of the agent regarding the task perspective of the teacher, leading to the loss of important information. To address this issue, we introduce the Equal Preference Learning Task, which optimizes the neural network by promoting similar reward predictions when the behaviors of two agents are labeled as equal preferences. Building on this task, we propose a novel PBRL method, Multi-Type Preference Learning (MTPL), which allows simultaneous learning from equal preferences while leveraging existing methods for learning from explicit preferences. To validate our approach, we design experiments applying MTPL to four existing state-of-the-art baselines across ten locomotion and robotic manipulation tasks in the DeepMind Control Suite. The experimental results indicate that simultaneous learning from both equal and explicit preferences enables the PBRL method to more comprehensively understand the feedback from teachers, thereby enhancing feedback efficiency.
HC-GST: Heterophily-aware Distribution Consistency based Graph Self-training
Jul 25, 2024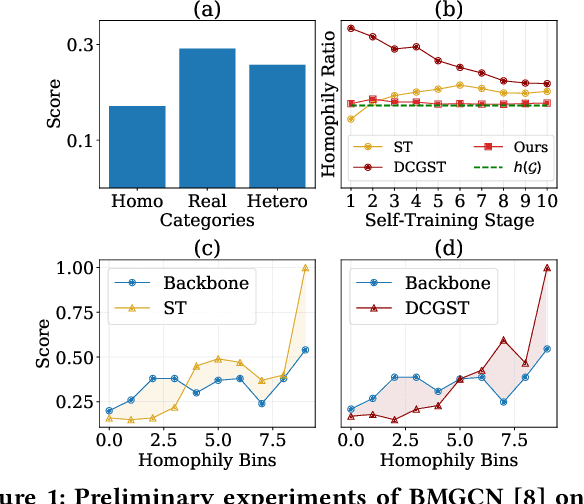
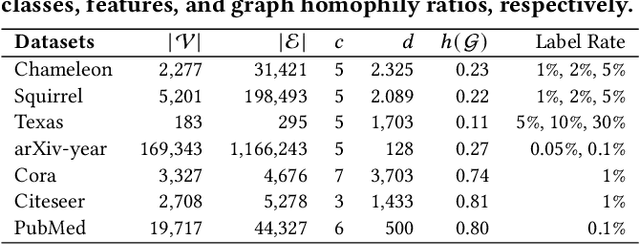
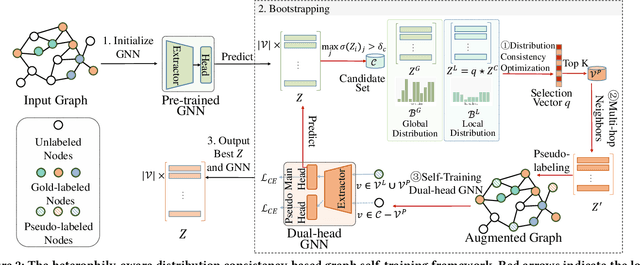
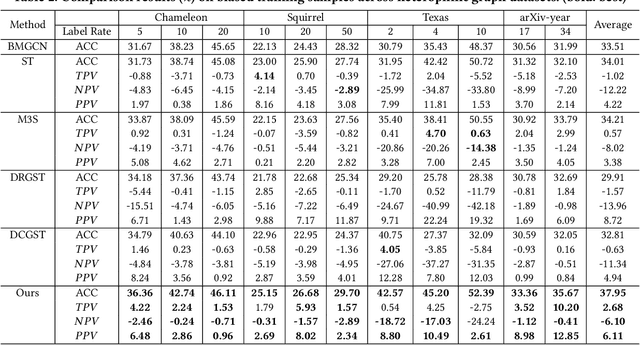
Graph self-training (GST), which selects and assigns pseudo-labels to unlabeled nodes, is popular for tackling label sparsity in graphs. However, recent study on homophily graphs show that GST methods could introduce and amplify distribution shift between training and test nodes as they tend to assign pseudo-labels to nodes they are good at. As GNNs typically perform better on homophilic nodes, there could be potential shifts towards homophilic pseudo-nodes, which is underexplored. Our preliminary experiments on heterophilic graphs verify that these methods can cause shifts in homophily ratio distributions, leading to \textit{training bias} that improves performance on homophilic nodes while degrading it on heterophilic ones. Therefore, we study a novel problem of reducing homophily ratio distribution shifts during self-training on heterophilic graphs. A key challenge is the accurate calculation of homophily ratios and their distributions without extensive labeled data. To tackle them, we propose a novel Heterophily-aware Distribution Consistency-based Graph Self-Training (HC-GST) framework, which estimates homophily ratios using soft labels and optimizes a selection vector to align pseudo-nodes with the global homophily ratio distribution. Extensive experiments on both homophilic and heterophilic graphs show that HC-GST effectively reduces training bias and enhances self-training performance.
Enhancing Data-Limited Graph Neural Networks by Actively Distilling Knowledge from Large Language Models
Jul 19, 2024Graphs have emerged as critical data structures for content analysis in various domains, such as social network analysis, bioinformatics, and recommendation systems. Node classification, a fundamental task in this context, is typically tackled using graph neural networks (GNNs). Unfortunately, conventional GNNs still face challenges in scenarios with few labeled nodes, despite the prevalence of few-shot node classification tasks in real-world applications. To address this challenge, various approaches have been proposed, including graph meta-learning, transfer learning, and methods based on Large Language Models (LLMs). However, traditional meta-learning and transfer learning methods often require prior knowledge from base classes or fail to exploit the potential advantages of unlabeled nodes. Meanwhile, LLM-based methods may overlook the zero-shot capabilities of LLMs and rely heavily on the quality of generated contexts. In this paper, we propose a novel approach that integrates LLMs and GNNs, leveraging the zero-shot inference and reasoning capabilities of LLMs and employing a Graph-LLM-based active learning paradigm to enhance GNNs' performance. Extensive experiments demonstrate the effectiveness of our model in improving node classification accuracy with considerably limited labeled data, surpassing state-of-the-art baselines by significant margins.