 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Modeling of CRISPR-Cas12 Activity Using Foundation Models and Chromatin Accessibility Data
Jun 12, 2025Predicting guide RNA (gRNA) activity is critical for effective CRISPR-Cas12 genome editing but remains challenging due to limited data, variation across protospacer adjacent motifs (PAMs-short sequence requirements for Cas binding), and reliance on large-scale training. We investigate whether pre-trained biological foundation model originally trained on transcriptomic data can improve gRNA activity estimation even without domain-specific pre-training. Using embeddings from existing RNA foundation model as input to lightweight regressor, we show substantial gains over traditional baselines. We also integrate chromatin accessibility data to capture regulatory context, improving performance further. Our results highlight the effectiveness of pre-trained foundation models and chromatin accessibility data for gRNA activity prediction.
Geometric Hyena Networks for Large-scale Equivariant Learning
May 28, 2025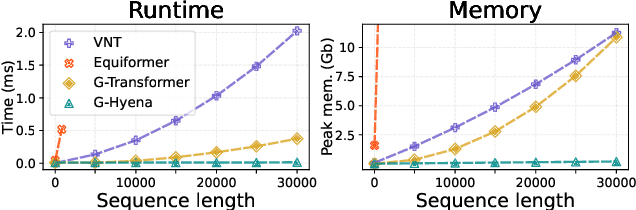
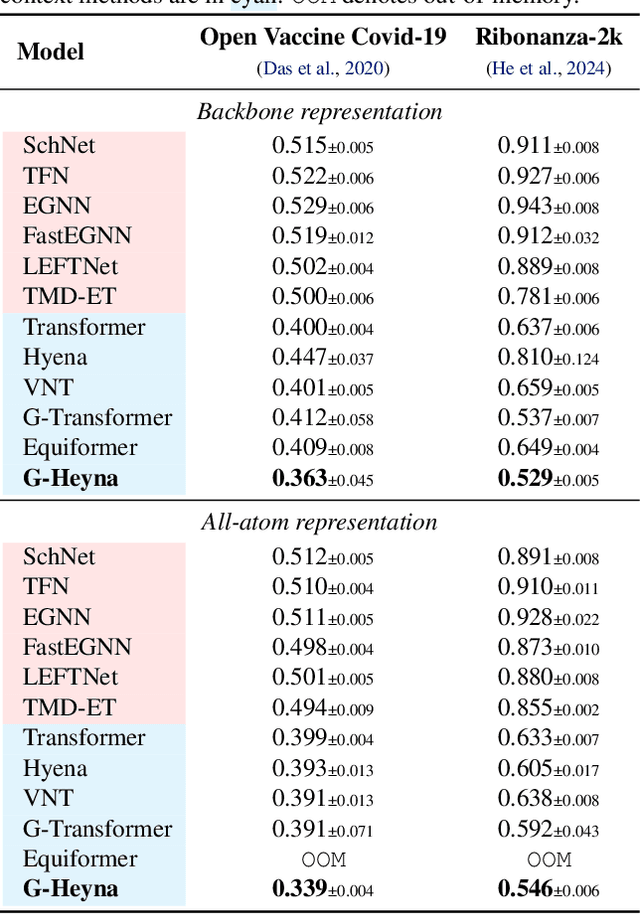
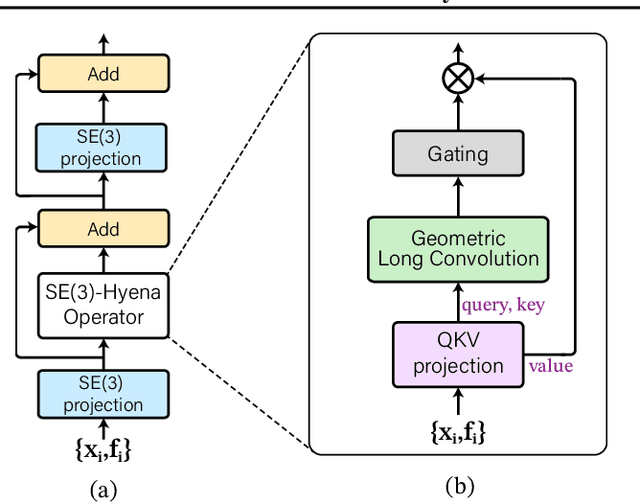
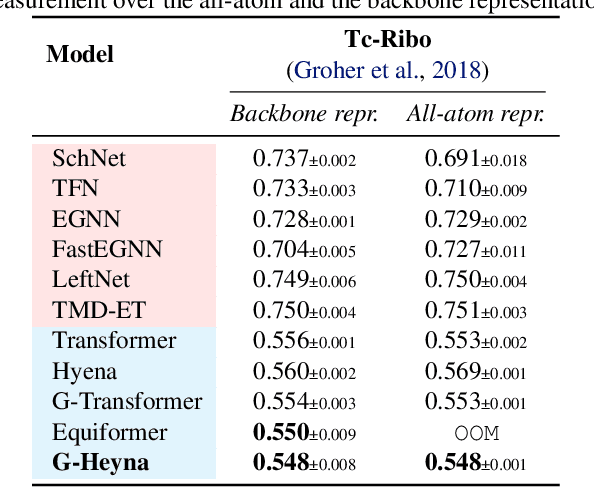
Processing global geometric context while preserving equivariance is crucial when modeling biological, chemical, and physical systems. Yet, this is challenging due to the computational demands of equivariance and global context at scale. Standard methods such as equivariant self-attention suffer from quadratic complexity, while local methods such as distance-based message passing sacrifice global information. Inspired by the recent success of state-space and long-convolutional models, we introduce Geometric Hyena, the first equivariant long-convolutional model for geometric systems. Geometric Hyena captures global geometric context at sub-quadratic complexity while maintaining equivariance to rotations and translations. Evaluated on all-atom property prediction of large RNA molecules and full protein molecular dynamics, Geometric Hyena outperforms existing equivariant models while requiring significantly less memory and compute that equivariant self-attention. Notably, our model processes the geometric context of 30k tokens 20x faster than the equivariant transformer and allows 72x longer context within the same budget.
InfoSEM: A Deep Generative Model with Informative Priors for Gene Regulatory Network Inference
Mar 06, 2025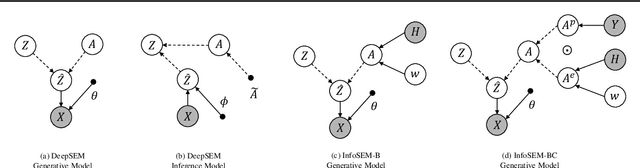
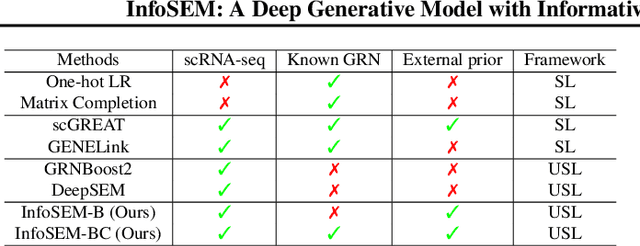
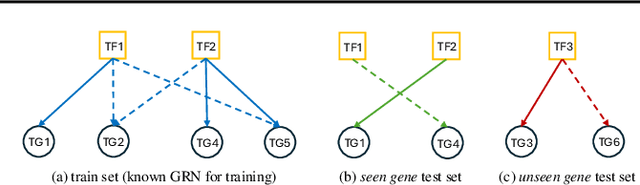
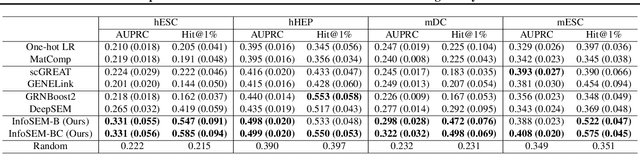
Inferring Gene Regulatory Networks (GRNs) from gene expression data is crucial for understanding biological processes. While supervised models are reported to achieve high performance for this task, they rely on costly ground truth (GT) labels and risk learning gene-specific biases, such as class imbalances of GT interactions, rather than true regulatory mechanisms. To address these issues, we introduce InfoSEM, an unsupervised generative model that leverages textual gene embeddings as informative priors, improving GRN inference without GT labels. InfoSEM can also integrate GT labels as an additional prior when available, avoiding biases and further enhancing performance. Additionally, we propose a biologically motivated benchmarking framework that better reflects real-world applications such as biomarker discovery and reveals learned biases of existing supervised methods. InfoSEM outperforms existing models by 38.5% across four datasets using textual embeddings prior and further boosts performance by 11.1% when integrating labeled data as priors.
HELM: Hierarchical Encoding for mRNA Language Modeling
Oct 16, 2024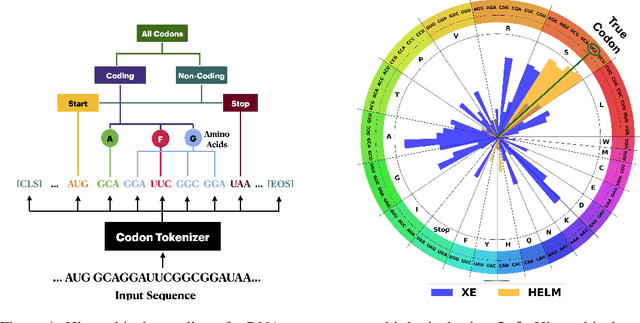
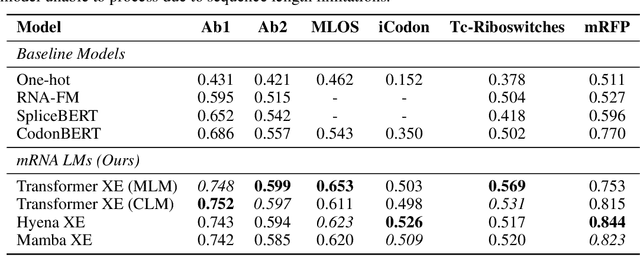
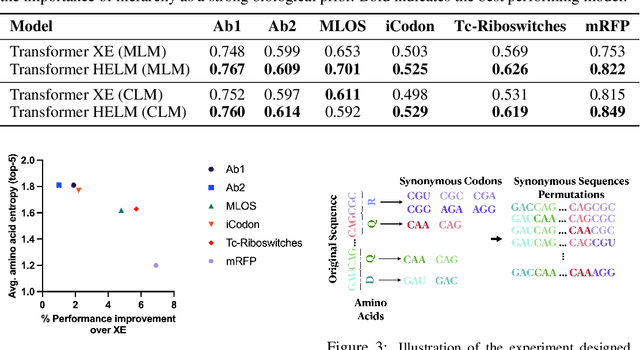
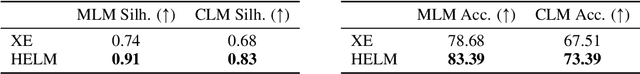
Messenger RNA (mRNA) plays a crucial role in protein synthesis, with its codon structure directly impacting biological properties. While Language Models (LMs) have shown promise in analyzing biological sequences, existing approaches fail to account for the hierarchical nature of mRNA's codon structure. We introduce Hierarchical Encoding for mRNA Language Modeling (HELM), a novel pre-training strategy that incorporates codon-level hierarchical structure into language model training. HELM modulates the loss function based on codon synonymity, aligning the model's learning process with the biological reality of mRNA sequences. We evaluate HELM on diverse mRNA datasets and tasks, demonstrating that HELM outperforms standard language model pre-training as well as existing foundation model baselines on six diverse downstream property prediction tasks and an antibody region annotation tasks on average by around 8\%. Additionally, HELM enhances the generative capabilities of language model, producing diverse mRNA sequences that better align with the underlying true data distribution compared to non-hierarchical baselines.
Beyond Sequence: Impact of Geometric Context for RNA Property Prediction
Oct 15, 2024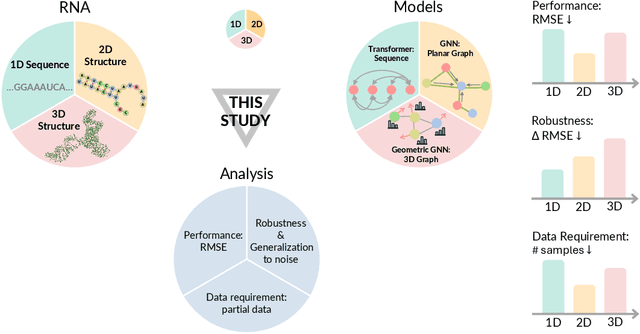
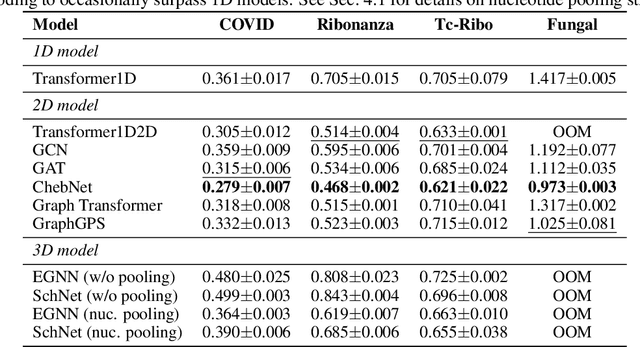
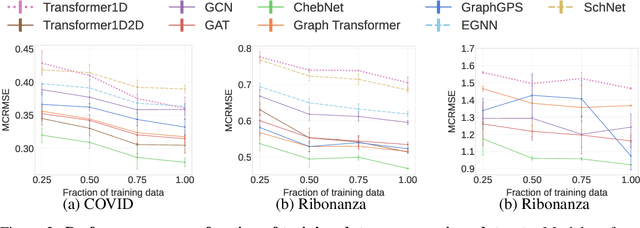

Accurate prediction of RNA properties, such as stability and interactions, is crucial for advancing our understanding of biological processes and developing RNA-based therapeutics. RNA structures can be represented as 1D sequences, 2D topological graphs, or 3D all-atom models, each offering different insights into its function. Existing works predominantly focus on 1D sequence-based models, which overlook the geometric context provided by 2D and 3D geometries. This study presents the first systematic evaluation of incorporating explicit 2D and 3D geometric information into RNA property prediction, considering not only performance but also real-world challenges such as limited data availability, partial labeling, sequencing noise, and computational efficiency. To this end, we introduce a newly curated set of RNA datasets with enhanced 2D and 3D structural annotations, providing a resource for model evaluation on RNA data. Our findings reveal that models with explicit geometry encoding generally outperform sequence-based models, with an average prediction RMSE reduction of around 12% across all various RNA tasks and excelling in low-data and partial labeling regimes, underscoring the value of explicitly incorporating geometric context. On the other hand, geometry-unaware sequence-based models are more robust under sequencing noise but often require around 2-5x training data to match the performance of geometry-aware models. Our study offers further insights into the trade-offs between different RNA representations in practical applications and addresses a significant gap in evaluating deep learning models for RNA tasks.
SE(3)-Hyena Operator for Scalable Equivariant Learning
Jul 01, 2024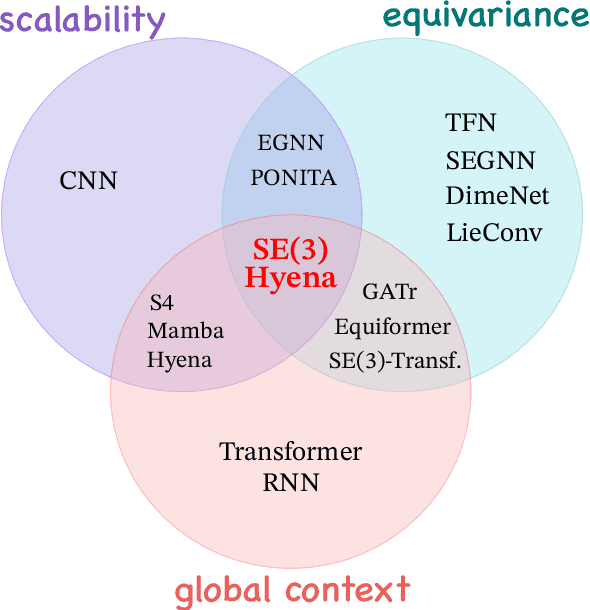
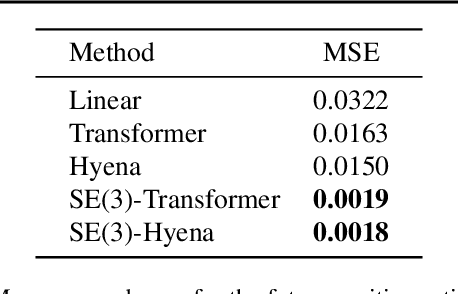
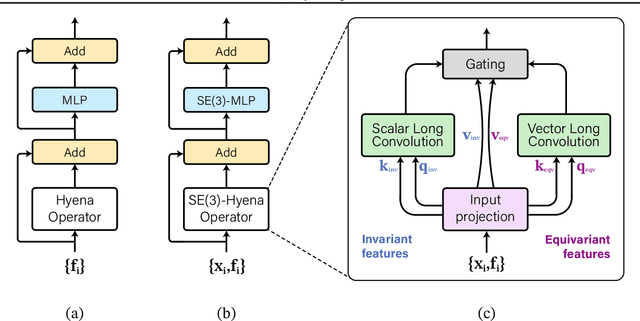
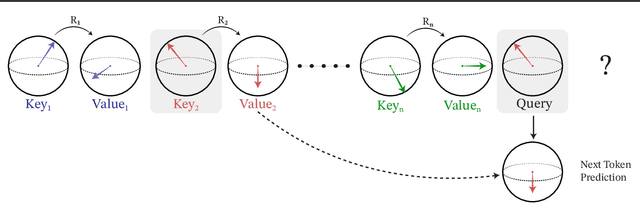
Modeling global geometric context while maintaining equivariance is crucial for accurate predictions in many fields such as biology, chemistry, or vision. Yet, this is challenging due to the computational demands of processing high-dimensional data at scale. Existing approaches such as equivariant self-attention or distance-based message passing, suffer from quadratic complexity with respect to sequence length, while localized methods sacrifice global information. Inspired by the recent success of state-space and long-convolutional models, in this work, we introduce SE(3)-Hyena operator, an equivariant long-convolutional model based on the Hyena operator. The SE(3)-Hyena captures global geometric context at sub-quadratic complexity while maintaining equivariance to rotations and translations. Evaluated on equivariant associative recall and n-body modeling, SE(3)-Hyena matches or outperforms equivariant self-attention while requiring significantly less memory and computational resources for long sequences. Our model processes the geometric context of 20k tokens x3.5 times faster than the equivariant transformer and allows x175 longer a context within the same memory budget.
On genuine invariance learning without weight-tying
Aug 07, 2023



In this paper, we investigate properties and limitations of invariance learned by neural networks from the data compared to the genuine invariance achieved through invariant weight-tying. To do so, we adopt a group theoretical perspective and analyze invariance learning in neural networks without weight-tying constraints. We demonstrate that even when a network learns to correctly classify samples on a group orbit, the underlying decision-making in such a model does not attain genuine invariance. Instead, learned invariance is strongly conditioned on the input data, rendering it unreliable if the input distribution shifts. We next demonstrate how to guide invariance learning toward genuine invariance by regularizing the invariance of a model at the training. To this end, we propose several metrics to quantify learned invariance: (i) predictive distribution invariance, (ii) logit invariance, and (iii) saliency invariance similarity. We show that the invariance learned with the invariance error regularization closely reassembles the genuine invariance of weight-tying models and reliably holds even under a severe input distribution shift. Closer analysis of the learned invariance also reveals the spectral decay phenomenon, when a network chooses to achieve the invariance to a specific transformation group by reducing the sensitivity to any input perturbation.
Learning to Summarize Videos by Contrasting Clips
Jan 13, 2023


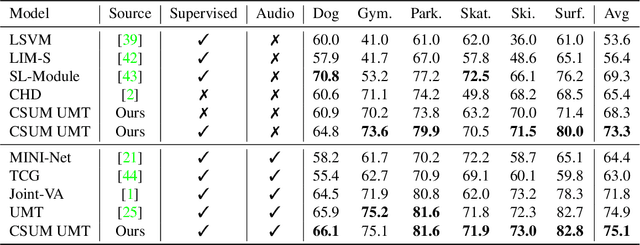
Video summarization aims at choosing parts of a video that narrate a story as close as possible to the original one. Most of the existing video summarization approaches focus on hand-crafted labels. As the number of videos grows exponentially, there emerges an increasing need for methods that can learn meaningful summarizations without labeled annotations. In this paper, we aim to maximally exploit unsupervised video summarization while concentrating the supervision to a few, personalized labels as an add-on. To do so, we formulate the key requirements for the informative video summarization. Then, we propose contrastive learning as the answer to both questions. To further boost Contrastive video Summarization (CSUM), we propose to contrast top-k features instead of a mean video feature as employed by the existing method, which we implement with a differentiable top-k feature selector. Our experiments on several benchmarks demonstrate, that our approach allows for meaningful and diverse summaries when no labeled data is provided.
LieGG: Studying Learned Lie Group Generators
Oct 09, 2022



Symmetries built into a neural network have appeared to be very beneficial for a wide range of tasks as it saves the data to learn them. We depart from the position that when symmetries are not built into a model a priori, it is advantageous for robust networks to learn symmetries directly from the data to fit a task function. In this paper, we present a method to extract symmetries learned by a neural network and to evaluate the degree to which a network is invariant to them. With our method, we are able to explicitly retrieve learned invariances in a form of the generators of corresponding Lie-groups without prior knowledge of symmetries in the data. We use the proposed method to study how symmetrical properties depend on a neural network's parameterization and configuration. We found that the ability of a network to learn symmetries generalizes over a range of architectures. However, the quality of learned symmetries depends on the depth and the number of parameters.
Contrasting quadratic assignments for set-based representation learning
May 31, 2022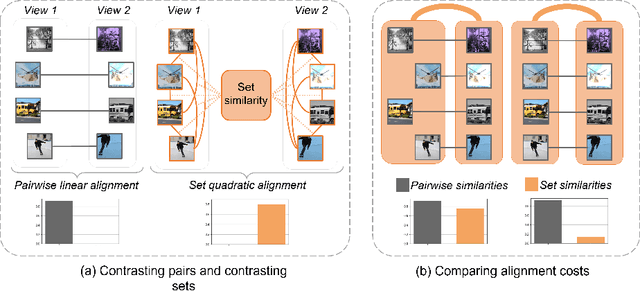

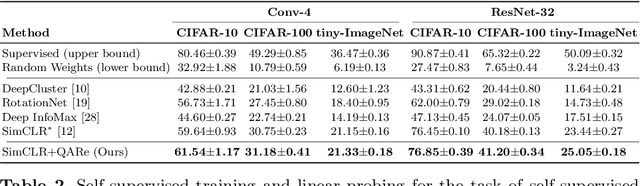
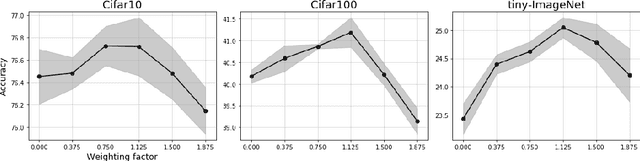
The standard approach to contrastive learning is to maximize the agreement between different views of the data. The views are ordered in pairs, such that they are either positive, encoding different views of the same object, or negative, corresponding to views of different objects. The supervisory signal comes from maximizing the total similarity over positive pairs, while the negative pairs are needed to avoid collapse. In this work, we note that the approach of considering individual pairs cannot account for both intra-set and inter-set similarities when the sets are formed from the views of the data. It thus limits the information content of the supervisory signal available to train representations. We propose to go beyond contrasting individual pairs of objects by focusing on contrasting objects as sets. For this, we use combinatorial quadratic assignment theory designed to evaluate set and graph similarities and derive set-contrastive objective as a regularizer for contrastive learning methods. We conduct experiments and demonstrate that our method improves learned representations for the tasks of metric learning and self-supervised classification.