 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgent-as-Tool: A Study on the Hierarchical Decision Making with Reinforcement Learning
Jul 02, 2025



Large Language Models (LLMs) have emerged as one of the most significant technological advancements in artificial intelligence in recent years. Their ability to understand, generate, and reason with natural language has transformed how we interact with AI systems. With the development of LLM-based agents and reinforcement-learning-based reasoning models, the study of applying reinforcement learning in agent frameworks has become a new research focus. However, all previous studies face the challenge of deciding the tool calling process and the reasoning process simultaneously, and the chain of reasoning was solely relied on the unprocessed raw result with redundant information and symbols unrelated to the task from the tool, which impose a heavy burden on the model's capability to reason. Therefore, in our research, we proposed a hierarchical framework Agent-as-tool that detach the tool calling process and the reasoning process, which enables the model to focus on the verbally reasoning process while the tool calling process is handled by another agent. Our work had achieved comparable results with only a slight reinforcement fine-tuning on 180 samples, and had achieved exceptionally well performance in Bamboogle with 63.2% of exact match and 75.2% in cover exact match, exceeding Search-R1 by 4.8% in exact match and 3.2% in cover exact match.
Multimodal Modeling of CRISPR-Cas12 Activity Using Foundation Models and Chromatin Accessibility Data
Jun 12, 2025Predicting guide RNA (gRNA) activity is critical for effective CRISPR-Cas12 genome editing but remains challenging due to limited data, variation across protospacer adjacent motifs (PAMs-short sequence requirements for Cas binding), and reliance on large-scale training. We investigate whether pre-trained biological foundation model originally trained on transcriptomic data can improve gRNA activity estimation even without domain-specific pre-training. Using embeddings from existing RNA foundation model as input to lightweight regressor, we show substantial gains over traditional baselines. We also integrate chromatin accessibility data to capture regulatory context, improving performance further. Our results highlight the effectiveness of pre-trained foundation models and chromatin accessibility data for gRNA activity prediction.
AIstorian lets AI be a historian: A KG-powered multi-agent system for accurate biography generation
Mar 14, 2025Huawei has always been committed to exploring the AI application in historical research. Biography generation, as a specialized form of abstractive summarization, plays a crucial role in historical research but faces unique challenges that existing large language models (LLMs) struggle to address. These challenges include maintaining stylistic adherence to historical writing conventions, ensuring factual fidelity, and handling fragmented information across multiple documents. We present AIstorian, a novel end-to-end agentic system featured with a knowledge graph (KG)-powered retrieval-augmented generation (RAG) and anti-hallucination multi-agents. Specifically, AIstorian introduces an in-context learning based chunking strategy and a KG-based index for accurate and efficient reference retrieval. Meanwhile, AIstorian orchestrates multi-agents to conduct on-the-fly hallucination detection and error-type-aware correction. Additionally, to teach LLMs a certain language style, we finetune LLMs based on a two-step training approach combining data augmentation-enhanced supervised fine-tuning with stylistic preference optimization. Extensive experiments on a real-life historical Jinshi dataset demonstrate that AIstorian achieves a 3.8x improvement in factual accuracy and a 47.6% reduction in hallucination rate compared to existing baselines. The data and code are available at: https://github.com/ZJU-DAILY/AIstorian.
Assessing the Performance of Deep Learning Algorithms for Newsvendor Problem
Jun 09, 2017


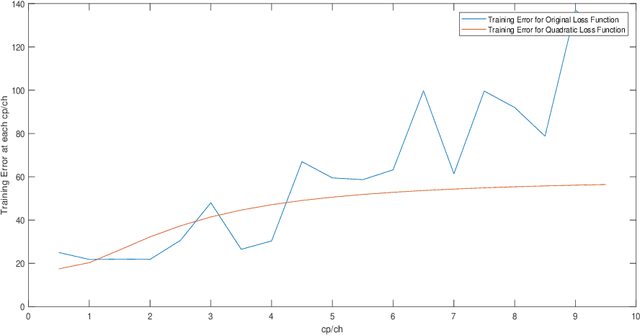
In retailer management, the Newsvendor problem has widely attracted attention as one of basic inventory models. In the traditional approach to solving this problem, it relies on the probability distribution of the demand. In theory, if the probability distribution is known, the problem can be considered as fully solved. However, in any real world scenario, it is almost impossible to even approximate or estimate a better probability distribution for the demand. In recent years, researchers start adopting machine learning approach to learn a demand prediction model by using other feature information. In this paper, we propose a supervised learning that optimizes the demand quantities for products based on feature information. We demonstrate that the original Newsvendor loss function as the training objective outperforms the recently suggested quadratic loss function. The new algorithm has been assessed on both the synthetic data and real-world data, demonstrating better performance.