 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReplacing Multi-Step Assembly of Data Preparation Pipelines with One-Step LLM Pipeline Generation for Table QA
Feb 26, 2026Table Question Answering (TQA) aims to answer natural language questions over structured tables. Large Language Models (LLMs) enable promising solutions to this problem, with operator-centric solutions that generate table manipulation pipelines in a multi-step manner offering state-of-the-art performance. However, these solutions rely on multiple LLM calls, resulting in prohibitive latencies and computational costs. We propose Operation-R1, the first framework that trains lightweight LLMs (e.g., Qwen-4B/1.7B) via a novel variant of reinforcement learning with verifiable rewards to produce high-quality data-preparation pipelines for TQA in a single inference step. To train such an LLM, we first introduce a self-supervised rewarding mechanism to automatically obtain fine-grained pipeline-wise supervision signals for LLM training. We also propose variance-aware group resampling to mitigate training instability. To further enhance robustness of pipeline generation, we develop two complementary mechanisms: operation merge, which filters spurious operations through multi-candidate consensus, and adaptive rollback, which offers runtime protection against information loss in data transformation. Experiments on two benchmark datasets show that, with the same LLM backbone, Operation-R1 achieves average absolute accuracy gains of 9.55 and 6.08 percentage points over multi-step preparation baselines, with 79\% table compression and a 2.2$\times$ reduction in monetary cost.
RelBench v2: A Large-Scale Benchmark and Repository for Relational Data
Feb 13, 2026Relational deep learning (RDL) has emerged as a powerful paradigm for learning directly on relational databases by modeling entities and their relationships across multiple interconnected tables. As this paradigm evolves toward larger models and relational foundation models, scalable and realistic benchmarks are essential for enabling systematic evaluation and progress. In this paper, we introduce RelBench v2, a major expansion of the RelBench benchmark for RDL. RelBench v2 adds four large-scale relational datasets spanning scholarly publications, enterprise resource planning, consumer platforms, and clinical records, increasing the benchmark to 11 datasets comprising over 22 million rows across 29 tables. We further introduce autocomplete tasks, a new class of predictive objectives that require models to infer missing attribute values directly within relational tables while respecting temporal constraints, expanding beyond traditional forecasting tasks constructed via SQL queries. In addition, RelBench v2 expands beyond its native datasets by integrating external benchmarks and evaluation frameworks: we translate event streams from the Temporal Graph Benchmark into relational schemas for unified relational-temporal evaluation, interface with ReDeLEx to provide uniform access to 70+ real-world databases suitable for pretraining, and incorporate 4DBInfer datasets and tasks to broaden multi-table prediction coverage. Experimental results demonstrate that RDL models consistently outperform single-table baselines across autocomplete, forecasting, and recommendation tasks, highlighting the importance of modeling relational structure explicitly.
AIstorian lets AI be a historian: A KG-powered multi-agent system for accurate biography generation
Mar 14, 2025

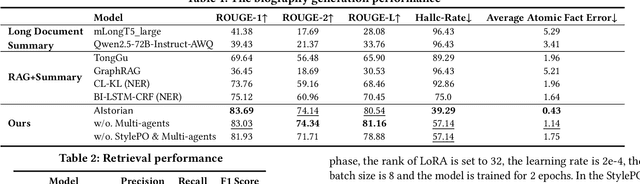

Huawei has always been committed to exploring the AI application in historical research. Biography generation, as a specialized form of abstractive summarization, plays a crucial role in historical research but faces unique challenges that existing large language models (LLMs) struggle to address. These challenges include maintaining stylistic adherence to historical writing conventions, ensuring factual fidelity, and handling fragmented information across multiple documents. We present AIstorian, a novel end-to-end agentic system featured with a knowledge graph (KG)-powered retrieval-augmented generation (RAG) and anti-hallucination multi-agents. Specifically, AIstorian introduces an in-context learning based chunking strategy and a KG-based index for accurate and efficient reference retrieval. Meanwhile, AIstorian orchestrates multi-agents to conduct on-the-fly hallucination detection and error-type-aware correction. Additionally, to teach LLMs a certain language style, we finetune LLMs based on a two-step training approach combining data augmentation-enhanced supervised fine-tuning with stylistic preference optimization. Extensive experiments on a real-life historical Jinshi dataset demonstrate that AIstorian achieves a 3.8x improvement in factual accuracy and a 47.6% reduction in hallucination rate compared to existing baselines. The data and code are available at: https://github.com/ZJU-DAILY/AIstorian.
Distribution Normalization: An "Effortless" Test-Time Augmentation for Contrastively Learned Visual-language Models
Feb 22, 2023
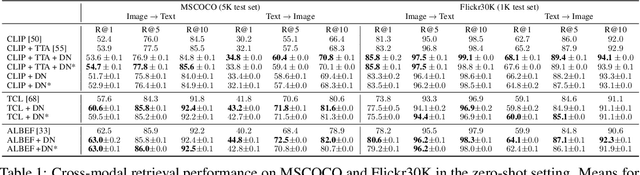
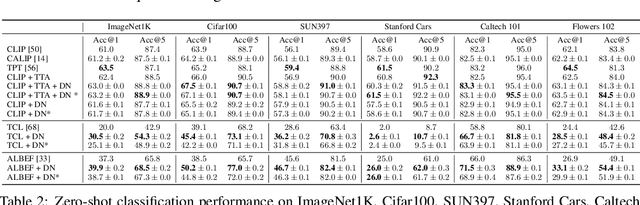

Advances in the field of visual-language contrastive learning have made it possible for many downstream applications to be carried out efficiently and accurately by simply taking the dot product between image and text representations. One of the most representative approaches proposed recently known as CLIP has quickly garnered widespread adoption due to its effectiveness. CLIP is trained with an InfoNCE loss that takes into account both positive and negative samples to help learn a much more robust representation space. This paper however reveals that the common downstream practice of taking a dot product is only a zeroth-order approximation of the optimization goal, resulting in a loss of information during test-time. Intuitively, since the model has been optimized based on the InfoNCE loss, test-time procedures should ideally also be in alignment. The question lies in how one can retrieve any semblance of negative samples information during inference. We propose Distribution Normalization (DN), where we approximate the mean representation of a batch of test samples and use such a mean to represent what would be analogous to negative samples in the InfoNCE loss. DN requires no retraining or fine-tuning and can be effortlessly applied during inference. Extensive experiments on a wide variety of downstream tasks exhibit a clear advantage of DN over the dot product.
Cross-Dataset Propensity Estimation for Debiasing Recommender Systems
Dec 22, 2022

Datasets for training recommender systems are often subject to distribution shift induced by users' and recommenders' selection biases. In this paper, we study the impact of selection bias on datasets with different quantization. We then leverage two differently quantized datasets from different source distributions to mitigate distribution shift by applying the inverse probability scoring method from causal inference. Empirically, our approach gains significant performance improvement over single-dataset methods and alternative ways of combining two datasets.