 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-Layer Linear Auto-Regressive Models Estimate Latent States
Jun 10, 2026Auto-regressive models have emerged as powerful tools for sequential data, from language to video. Understanding how and why these models learn latent representations remains an open theoretical question. In this work, we demonstrate that when trained by empirical risk minimization on data from partially observed linear dynamical systems, two-layer linear auto-regressive models naturally learn to approximate Kalman filtering. In particular, we show that the learned hidden representation coincides, up to a similarity transformation, with the state estimates produced by the optimal (Kalman) filter, even though the model has no explicit knowledge of the underlying dynamics or state. The result follows from three main insights. First, we establish that the Kalman filter is well approximated by an auto-regressive model with bounded truncation error. Second, we show that despite non-convexity, the two-layer optimization landscape is benign, i.e., all stationary points are either strict saddles or global minima. Finally, as our main contributions, we provide finite-sample guarantees on prediction error, parameter estimation error, and latent state recovery. Numerical simulations support the theoretical results and demonstrate that the latent representations of auto-regressive models recover state estimates.
Credit-assigned Policy Gradient for Early Stage Retrieval in Two-stage Ranking
May 25, 2026Large-scale search, recommendation, and retrieval-augmented generation (RAG) systems typically employ a two-stage architecture: an early-stage ranker (ESR) generates a candidate set, which is subsequently re-ranked by a late-stage ranker (LSR). While there are many reinforcement learning (RL) methods for training the LSR, end-to-end training of the ESR has proven challenging. In particular, naive application of "vanilla" policy gradient (V-PG) is not scalable for candidate-set sizes relevant for practical use due to exploding variance. This issue arises because V-PG propagates the gradient to the joint probability of the candidate sets, ignoring the contribution of each specific item in the candidate set to the reward. To mitigate this issue, we propose a novel "credit-assigned" policy gradient (CA-PG), which computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e. marginalizing over all candidate sets that contain it. Our theoretical analysis reveals that CA-PG significantly reduces the variance of V-PG by marginalizing over the specific composition of the candidate set, while preserving the ability to learn the correct ranking of items under a reasonably aligned LSR policy. Experiments on both synthetic and real-world data demonstrate that CA-PG improves the convergence speed and training stability for ESRs utilizing the canonical Plackett-Luce model, especially when the candidate-set size is large.
Dual Control of Linear Systems from Bilinear Observations with Belief Space Model Predictive Control
Apr 27, 2026We study finite-horizon quadratic control of linear systems with bilinear observations, in which the control input affects not only the state dynamics but also the partial observations of the state. In this setting, the separation principle can fail because control inputs influence the future quality of state estimates. State estimation requires an input-dependent Kalman filter whose gain and error covariance evolve as functions of the control inputs. To address this challenge, we propose a belief-space model predictive control ($\texttt{B-MPC}$) method that plans directly over both the estimated state and its error covariance. In particular, $\texttt{B-MPC}$ plans with a deterministic surrogate of the belief evolution defined by the input-dependent Kalman filter. Through numerical experiments in two synthetic settings, we show that $\texttt{B-MPC}$ can outperform both the separation-principle controller and its MPC variant in favorable regimes, and that these gains are accompanied by lower estimation covariance and more uncertainty-aware action choices.
Dynamics of Learning under User Choice: Overspecialization and Peer-Model Probing
Feb 27, 2026In many economically relevant contexts where machine learning is deployed, multiple platforms obtain data from the same pool of users, each of whom selects the platform that best serves them. Prior work in this setting focuses exclusively on the "local" losses of learners on the distribution of data that they observe. We find that there exist instances where learners who use existing algorithms almost surely converge to models with arbitrarily poor global performance, even when models with low full-population loss exist. This happens through a feedback-induced mechanism, which we call the overspecialization trap: as learners optimize for users who already prefer them, they become less attractive to users outside this base, which further restricts the data they observe. Inspired by the recent use of knowledge distillation in modern ML, we propose an algorithm that allows learners to "probe" the predictions of peer models, enabling them to learn about users who do not select them. Our analysis characterizes when probing succeeds: this procedure converges almost surely to a stationary point with bounded full-population risk when probing sources are sufficiently informative, e.g., a known market leader or a majority of peers with good global performance. We verify our findings with semi-synthetic experiments on the MovieLens, Census, and Amazon Sentiment datasets.
A Human-in-the-Loop Confidence-Aware Failure Recovery Framework for Modular Robot Policies
Feb 10, 2026Robots operating in unstructured human environments inevitably encounter failures, especially in robot caregiving scenarios. While humans can often help robots recover, excessive or poorly targeted queries impose unnecessary cognitive and physical workload on the human partner. We present a human-in-the-loop failure-recovery framework for modular robotic policies, where a policy is composed of distinct modules such as perception, planning, and control, any of which may fail and often require different forms of human feedback. Our framework integrates calibrated estimates of module-level uncertainty with models of human intervention cost to decide which module to query and when to query the human. It separates these two decisions: a module selector identifies the module most likely responsible for failure, and a querying algorithm determines whether to solicit human input or act autonomously. We evaluate several module-selection strategies and querying algorithms in controlled synthetic experiments, revealing trade-offs between recovery efficiency, robustness to system and user variables, and user workload. Finally, we deploy the framework on a robot-assisted bite acquisition system and demonstrate, in studies involving individuals with both emulated and real mobility limitations, that it improves recovery success while reducing the workload imposed on users. Our results highlight how explicitly reasoning about both robot uncertainty and human effort can enable more efficient and user-centered failure recovery in collaborative robots. Supplementary materials and videos can be found at: http://emprise.cs.cornell.edu/modularhil
Do LLMs Favor LLMs? Quantifying Interaction Effects in Peer Review
Jan 28, 2026There are increasing indications that LLMs are not only used for producing scientific papers, but also as part of the peer review process. In this work, we provide the first comprehensive analysis of LLM use across the peer review pipeline, with particular attention to interaction effects: not just whether LLM-assisted papers or LLM-assisted reviews are different in isolation, but whether LLM-assisted reviews evaluate LLM-assisted papers differently. In particular, we analyze over 125,000 paper-review pairs from ICLR, NeurIPS, and ICML. We initially observe what appears to be a systematic interaction effect: LLM-assisted reviews seem especially kind to LLM-assisted papers compared to papers with minimal LLM use. However, controlling for paper quality reveals a different story: LLM-assisted reviews are simply more lenient toward lower quality papers in general, and the over-representation of LLM-assisted papers among weaker submissions creates a spurious interaction effect rather than genuine preferential treatment of LLM-generated content. By augmenting our observational findings with reviews that are fully LLM-generated, we find that fully LLM-generated reviews exhibit severe rating compression that fails to discriminate paper quality, while human reviewers using LLMs substantially reduce this leniency. Finally, examining metareviews, we find that LLM-assisted metareviews are more likely to render accept decisions than human metareviews given equivalent reviewer scores, though fully LLM-generated metareviews tend to be harsher. This suggests that meta-reviewers do not merely outsource the decision-making to the LLM. These findings provide important input for developing policies that govern the use of LLMs during peer review, and they more generally indicate how LLMs interact with existing decision-making processes.
High-Altitude Balloon Station-Keeping with First Order Model Predictive Control
Nov 11, 2025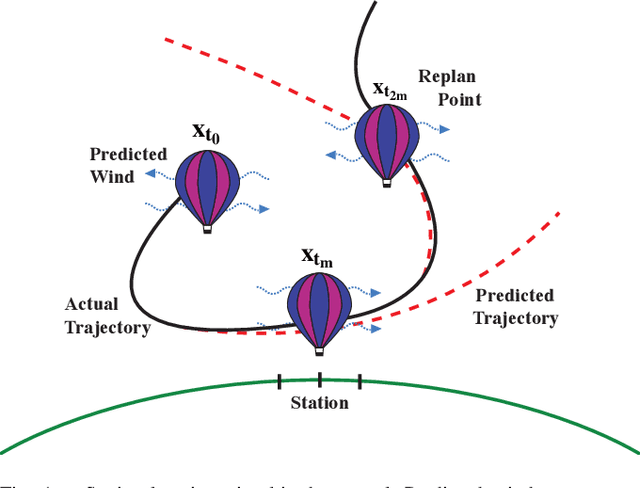
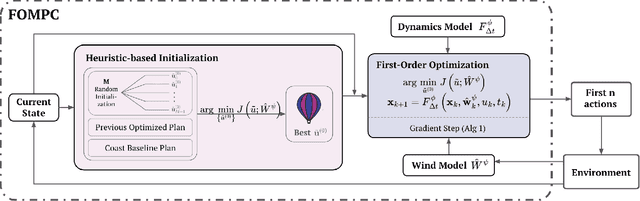
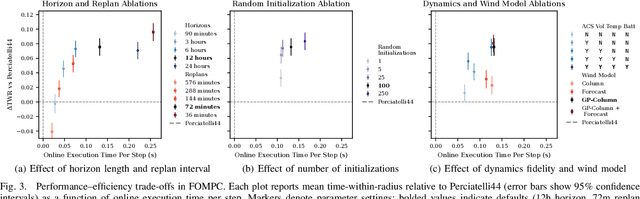
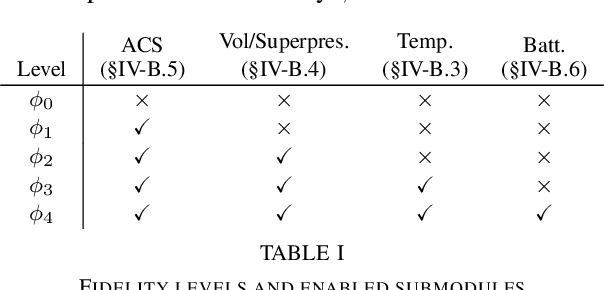
High-altitude balloons (HABs) are common in scientific research due to their wide range of applications and low cost. Because of their nonlinear, underactuated dynamics and the partial observability of wind fields, prior work has largely relied on model-free reinforcement learning (RL) methods to design near-optimal control schemes for station-keeping. These methods often compare only against hand-crafted heuristics, dismissing model-based approaches as impractical given the system complexity and uncertain wind forecasts. We revisit this assumption about the efficacy of model-based control for station-keeping by developing First-Order Model Predictive Control (FOMPC). By implementing the wind and balloon dynamics as differentiable functions in JAX, we enable gradient-based trajectory optimization for online planning. FOMPC outperforms a state-of-the-art RL policy, achieving a 24% improvement in time-within-radius (TWR) without requiring offline training, though at the cost of greater online computation per control step. Through systematic ablations of modeling assumptions and control factors, we show that online planning is effective across many configurations, including under simplified wind and dynamics models.
Benchmark Datasets for Lead-Lag Forecasting on Social Platforms
Nov 05, 2025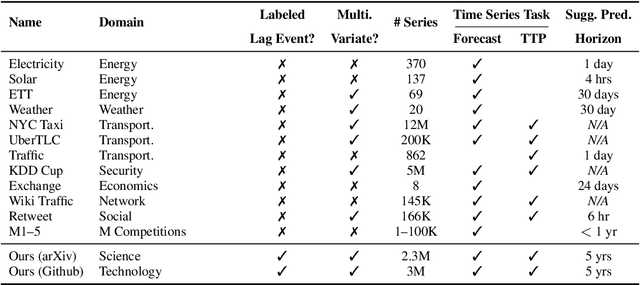
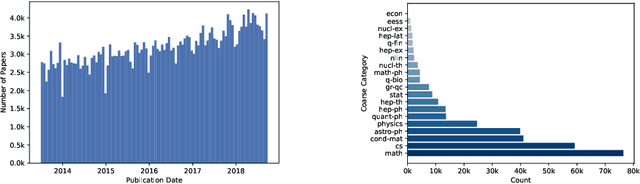
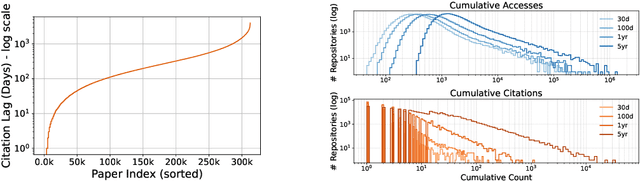
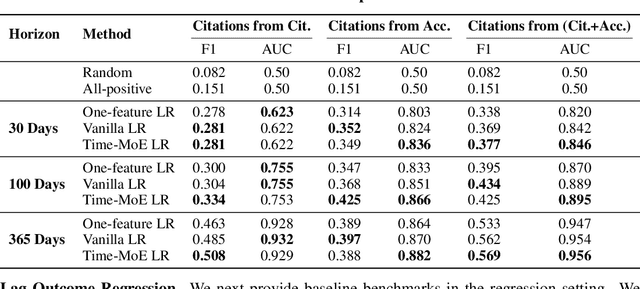
Social and collaborative platforms emit multivariate time-series traces in which early interactions-such as views, likes, or downloads-are followed, sometimes months or years later, by higher impact like citations, sales, or reviews. We formalize this setting as Lead-Lag Forecasting (LLF): given an early usage channel (the lead), predict a correlated but temporally shifted outcome channel (the lag). Despite the ubiquity of such patterns, LLF has not been treated as a unified forecasting problem within the time-series community, largely due to the absence of standardized datasets. To anchor research in LLF, here we present two high-volume benchmark datasets-arXiv (accesses -> citations of 2.3M papers) and GitHub (pushes/stars -> forks of 3M repositories)-and outline additional domains with analogous lead-lag dynamics, including Wikipedia (page views -> edits), Spotify (streams -> concert attendance), e-commerce (click-throughs -> purchases), and LinkedIn profile (views -> messages). Our datasets provide ideal testbeds for lead-lag forecasting, by capturing long-horizon dynamics across years, spanning the full spectrum of outcomes, and avoiding survivorship bias in sampling. We documented all technical details of data curation and cleaning, verified the presence of lead-lag dynamics through statistical and classification tests, and benchmarked parametric and non-parametric baselines for regression. Our study establishes LLF as a novel forecasting paradigm and lays an empirical foundation for its systematic exploration in social and usage data. Our data portal with downloads and documentation is available at https://lead-lag-forecasting.github.io/.
Datasets for Navigating Sensitive Topics in Recommendation Systems
Sep 08, 2025Personalized AI systems, from recommendation systems to chatbots, are a prevalent method for distributing content to users based on their learned preferences. However, there is growing concern about the adverse effects of these systems, including their potential tendency to expose users to sensitive or harmful material, negatively impacting overall well-being. To address this concern quantitatively, it is necessary to create datasets with relevant sensitivity labels for content, enabling researchers to evaluate personalized systems beyond mere engagement metrics. To this end, we introduce two novel datasets that include a taxonomy of sensitivity labels alongside user-content ratings: one that integrates MovieLens rating data with content warnings from the Does the Dog Die? community ratings website, and another that combines fan-fiction interaction data and user-generated warnings from Archive of Our Own.
Pre-trained Large Language Models Learn Hidden Markov Models In-context
Jun 08, 2025Hidden Markov Models (HMMs) are foundational tools for modeling sequential data with latent Markovian structure, yet fitting them to real-world data remains computationally challenging. In this work, we show that pre-trained large language models (LLMs) can effectively model data generated by HMMs via in-context learning (ICL)$\unicode{x2013}$their ability to infer patterns from examples within a prompt. On a diverse set of synthetic HMMs, LLMs achieve predictive accuracy approaching the theoretical optimum. We uncover novel scaling trends influenced by HMM properties, and offer theoretical conjectures for these empirical observations. We also provide practical guidelines for scientists on using ICL as a diagnostic tool for complex data. On real-world animal decision-making tasks, ICL achieves competitive performance with models designed by human experts. To our knowledge, this is the first demonstration that ICL can learn and predict HMM-generated sequences$\unicode{x2013}$an advance that deepens our understanding of in-context learning in LLMs and establishes its potential as a powerful tool for uncovering hidden structure in complex scientific data.