 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Stochasticity in Deep Research Agents
Feb 26, 2026Deep Research Agents (DRAs) are promising agentic systems that gather and synthesize information to support research across domains such as financial decision-making, medical analysis, and scientific discovery. Despite recent improvements in research quality (e.g., outcome accuracy when ground truth is available), DRA system design often overlooks a critical barrier to real-world deployment: stochasticity. Under identical queries, repeated executions of DRAs can exhibit substantial variability in terms of research outcome, findings, and citations. In this paper, we formalize the study of stochasticity in DRAs by modeling them as information acquisition Markov Decision Processes. We introduce an evaluation framework that quantifies variance in the system and identify three sources of it: information acquisition, information compression, and inference. Through controlled experiments, we investigate how stochasticity from these modules across different decision steps influences the variance of DRA outputs. Our results show that reducing stochasticity can improve research output quality, with inference and early-stage stochasticity contributing the most to DRA output variance. Based on these findings, we propose strategies for mitigating stochasticity while maintaining output quality via structured output and ensemble-based query generation. Our experiments on DeepSearchQA show that our proposed mitigation methods reduce average stochasticity by 22% while maintaining high research quality.
Learning Robust Reasoning through Guided Adversarial Self-Play
Jan 30, 2026Reinforcement learning from verifiable rewards (RLVR) produces strong reasoning models, yet they can fail catastrophically when the conditioning context is fallible (e.g., corrupted chain-of-thought, misleading partial solutions, or mild input perturbations), since standard RLVR optimizes final-answer correctness only under clean conditioning. We introduce GASP (Guided Adversarial Self-Play), a robustification method that explicitly trains detect-and-repair capabilities using only outcome verification. Without human labels or external teachers, GASP forms an adversarial self-play game within a single model: a polluter learns to induce failure via locally coherent corruptions, while an agent learns to diagnose and recover under the same corrupted conditioning. To address the scarcity of successful recoveries early in training, we propose in-distribution repair guidance, an imitation term on self-generated repairs that increases recovery probability while preserving previously acquired capabilities. Across four open-weight models (1.5B--8B), GASP transforms strong-but-brittle reasoners into robust ones that withstand misleading and perturbed context while often improving clean accuracy. Further analysis shows that adversarial corruptions induce an effective curriculum, and in-distribution guidance enables rapid recovery learning with minimal representational drift.
Position: Thematic Analysis of Unstructured Clinical Transcripts with Large Language Models
Sep 18, 2025This position paper examines how large language models (LLMs) can support thematic analysis of unstructured clinical transcripts, a widely used but resource-intensive method for uncovering patterns in patient and provider narratives. We conducted a systematic review of recent studies applying LLMs to thematic analysis, complemented by an interview with a practicing clinician. Our findings reveal that current approaches remain fragmented across multiple dimensions including types of thematic analysis, datasets, prompting strategies and models used, most notably in evaluation. Existing evaluation methods vary widely (from qualitative expert review to automatic similarity metrics), hindering progress and preventing meaningful benchmarking across studies. We argue that establishing standardized evaluation practices is critical for advancing the field. To this end, we propose an evaluation framework centered on three dimensions: validity, reliability, and interpretability.
ExPO: Unlocking Hard Reasoning with Self-Explanation-Guided Reinforcement Learning
Jul 03, 2025Recent advances in large language models have been driven by reinforcement learning (RL)-style post-training, which improves reasoning by optimizing model outputs based on reward or preference signals. GRPO-style approaches implement this by using self-generated samples labeled by an outcome-based verifier. However, these methods depend heavily on the model's initial ability to produce positive samples. They primarily refine what the model already knows (distribution sharpening) rather than enabling the model to solve problems where it initially fails. This limitation is especially problematic in early-stage RL training and on challenging reasoning tasks, where positive samples are unlikely to be generated. To unlock reasoning ability in such settings, the model must explore new reasoning trajectories beyond its current output distribution. Such exploration requires access to sufficiently good positive samples to guide the learning. While expert demonstrations seem like a natural solution, we find that they are often ineffective in RL post-training. Instead, we identify two key properties of effective positive samples: they should (1) be likely under the current policy, and (2) increase the model's likelihood of predicting the correct answer. Based on these insights, we propose $\textbf{Self-Explanation Policy Optimization (ExPO)}$-a simple and modular framework that generates such samples by conditioning on the ground-truth answer. ExPO enables efficient exploration and guides the model to produce reasoning trajectories more aligned with its policy than expert-written CoTs, while ensuring higher quality than its own (incorrect) samples. Experiments show that ExPO improves both learning efficiency and final performance on reasoning benchmarks, surpassing expert-demonstration-based methods in challenging settings such as MATH level-5, where the model initially struggles the most.
AgentDistill: Training-Free Agent Distillation with Generalizable MCP Boxes
Jun 17, 2025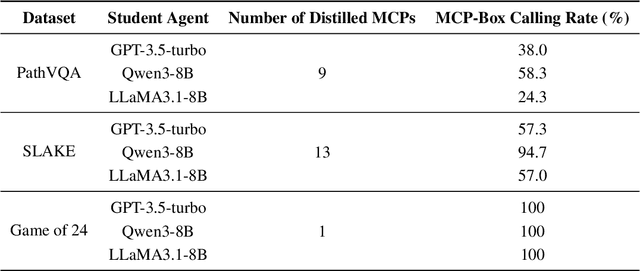
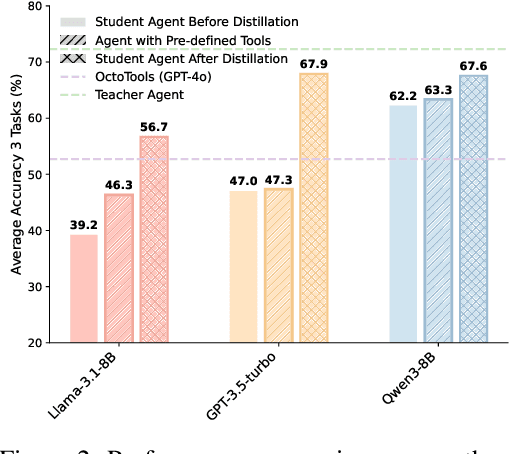
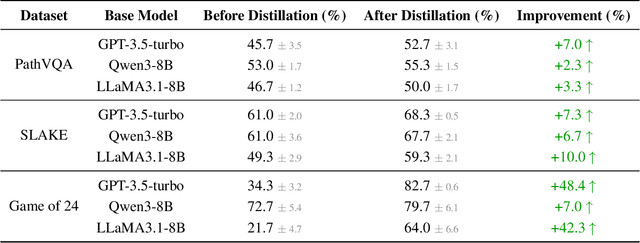
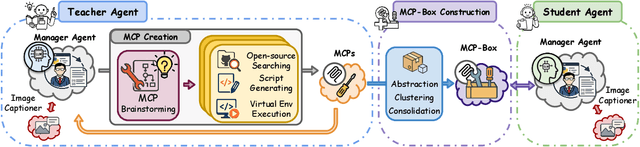
While knowledge distillation has become a mature field for compressing large language models (LLMs) into smaller ones by aligning their outputs or internal representations, the distillation of LLM-based agents, which involve planning, memory, and tool use, remains relatively underexplored. Existing agent distillation methods typically replay full teacher trajectories or imitate step-by-step teacher tool usage, but they often struggle to train student agents to dynamically plan and act in novel environments. We propose AgentDistill, a novel, training-free agent distillation framework that enables efficient and scalable knowledge transfer via direct reuse of Model-Context-Protocols (MCPs), which are structured and reusable task-solving modules autonomously generated by teacher agents. The reuse of these distilled MCPs enables student agents to generalize their capabilities across domains and solve new problems with minimal supervision or human intervention. Experiments on biomedical and mathematical benchmarks demonstrate that our distilled student agents, built on small language models, can achieve performance comparable to advanced systems using large LLMs such as OctoTools (GPT-4o), highlighting the effectiveness of our framework in building scalable and cost-efficient intelligent agents.
Hypothesis Testing for Quantifying LLM-Human Misalignment in Multiple Choice Settings
Jun 17, 2025As Large Language Models (LLMs) increasingly appear in social science research (e.g., economics and marketing), it becomes crucial to assess how well these models replicate human behavior. In this work, using hypothesis testing, we present a quantitative framework to assess the misalignment between LLM-simulated and actual human behaviors in multiple-choice survey settings. This framework allows us to determine in a principled way whether a specific language model can effectively simulate human opinions, decision-making, and general behaviors represented through multiple-choice options. We applied this framework to a popular language model for simulating people's opinions in various public surveys and found that this model is ill-suited for simulating the tested sub-populations (e.g., across different races, ages, and incomes) for contentious questions. This raises questions about the alignment of this language model with the tested populations, highlighting the need for new practices in using LLMs for social science studies beyond naive simulations of human subjects.
Learning Composable Chains-of-Thought
May 28, 2025A common approach for teaching large language models (LLMs) to reason is to train on chain-of-thought (CoT) traces of in-distribution reasoning problems, but such annotated data is costly to obtain for every problem of interest. We want reasoning models to generalize beyond their training distribution, and ideally to generalize compositionally: combine atomic reasoning skills to solve harder, unseen reasoning tasks. We take a step towards compositional generalization of reasoning skills when addressing a target compositional task that has no labeled CoT data. We find that simply training models on CoT data of atomic tasks leads to limited generalization, but minimally modifying CoT formats of constituent atomic tasks to be composable can lead to improvements. We can train "atomic CoT" models on the atomic tasks with Composable CoT data and combine them with multitask learning or model merging for better zero-shot performance on the target compositional task. Such a combined model can be further bootstrapped on a small amount of compositional data using rejection sampling fine-tuning (RFT). Results on string operations and natural language skill compositions show that training LLMs on Composable CoT outperforms multitask learning and continued fine-tuning baselines within a given training data budget.
Teaching with Lies: Curriculum DPO on Synthetic Negatives for Hallucination Detection
May 23, 2025



Aligning large language models (LLMs) to accurately detect hallucinations remains a significant challenge due to the sophisticated nature of hallucinated text. Recognizing that hallucinated samples typically exhibit higher deceptive quality than traditional negative samples, we use these carefully engineered hallucinations as negative examples in the DPO alignment procedure. Our method incorporates a curriculum learning strategy, gradually transitioning the training from easier samples, identified based on the greatest reduction in probability scores from independent fact checking models, to progressively harder ones. This structured difficulty scaling ensures stable and incremental learning. Experimental evaluation demonstrates that our HaluCheck models, trained with curriculum DPO approach and high quality negative samples, significantly improves model performance across various metrics, achieving improvements of upto 24% on difficult benchmarks like MedHallu and HaluEval. Additionally, HaluCheck models demonstrate robustness in zero-shot settings, significantly outperforming larger state-of-the-art models across various benchmarks.
EquivaMap: Leveraging LLMs for Automatic Equivalence Checking of Optimization Formulations
Feb 20, 2025



A fundamental problem in combinatorial optimization is identifying equivalent formulations, which can lead to more efficient solution strategies and deeper insights into a problem's computational complexity. The need to automatically identify equivalence between problem formulations has grown as optimization copilots--systems that generate problem formulations from natural language descriptions--have proliferated. However, existing approaches to checking formulation equivalence lack grounding, relying on simple heuristics which are insufficient for rigorous validation. Inspired by Karp reductions, in this work we introduce quasi-Karp equivalence, a formal criterion for determining when two optimization formulations are equivalent based on the existence of a mapping between their decision variables. We propose EquivaMap, a framework that leverages large language models to automatically discover such mappings, enabling scalable and reliable equivalence verification. To evaluate our approach, we construct the first open-source dataset of equivalent optimization formulations, generated by applying transformations such as adding slack variables or valid inequalities to existing formulations. Empirically, EquivaMap significantly outperforms existing methods, achieving substantial improvements in correctly identifying formulation equivalence.
A Common Pitfall of Margin-based Language Model Alignment: Gradient Entanglement
Oct 17, 2024Reinforcement Learning from Human Feedback (RLHF) has become the predominant approach for language model (LM) alignment. At its core, RLHF uses a margin-based loss for preference optimization, specifying ideal LM behavior only by the difference between preferred and dispreferred responses. In this paper, we identify a common pitfall of margin-based methods -- the under-specification of ideal LM behavior on preferred and dispreferred responses individually, which leads to two unintended consequences as the margin increases: (1) The probability of dispreferred (e.g., unsafe) responses may increase, resulting in potential safety alignment failures. (2) The probability of preferred responses may decrease, even when those responses are ideal. We demystify the reasons behind these problematic behaviors: margin-based losses couple the change in the preferred probability to the gradient of the dispreferred one, and vice versa, often preventing the preferred probability from increasing while the dispreferred one decreases, and thus causing a synchronized increase or decrease in both probabilities. We term this effect, inherent in margin-based objectives, gradient entanglement. Formally, we derive conditions for general margin-based alignment objectives under which gradient entanglement becomes concerning: the inner product of the gradients of preferred and dispreferred log-probabilities is large relative to the individual gradient norms. We theoretically investigate why such inner products can be large when aligning language models and empirically validate our findings. Empirical implications of our framework extend to explaining important differences in the training dynamics of various preference optimization algorithms, and suggesting potential algorithm designs to mitigate the under-specification issue of margin-based methods and thereby improving language model alignment.