 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHypothesis Testing for Quantifying LLM-Human Misalignment in Multiple Choice Settings
Jun 17, 2025As Large Language Models (LLMs) increasingly appear in social science research (e.g., economics and marketing), it becomes crucial to assess how well these models replicate human behavior. In this work, using hypothesis testing, we present a quantitative framework to assess the misalignment between LLM-simulated and actual human behaviors in multiple-choice survey settings. This framework allows us to determine in a principled way whether a specific language model can effectively simulate human opinions, decision-making, and general behaviors represented through multiple-choice options. We applied this framework to a popular language model for simulating people's opinions in various public surveys and found that this model is ill-suited for simulating the tested sub-populations (e.g., across different races, ages, and incomes) for contentious questions. This raises questions about the alignment of this language model with the tested populations, highlighting the need for new practices in using LLMs for social science studies beyond naive simulations of human subjects.
Differentially Private Meta-Learning
Sep 12, 2019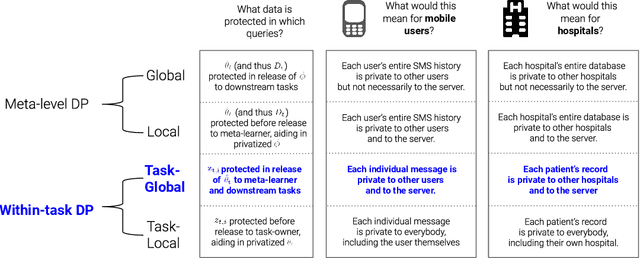

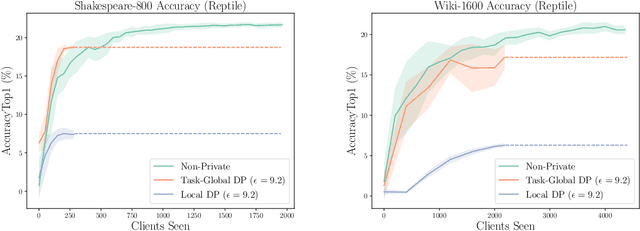

Parameter-transfer is a well-known and versatile approach for meta-learning, with applications including few-shot learning, federated learning, and reinforcement learning. However, parameter-transfer algorithms often require sharing models that have been trained on the samples from specific tasks, thus leaving the task-owners susceptible to breaches of privacy. We conduct the first formal study of privacy in this setting and formalize the notion of task-global differential privacy as a practical relaxation of more commonly studied threat models. We then propose a new differentially private algorithm for gradient-based parameter transfer that not only satisfies this privacy requirement but also retains provable transfer learning guarantees in convex settings. Empirically, we apply our analysis to the problem of federated learning with personalization and show that allowing the relaxation to task-global privacy from the more commonly studied notion of local privacy leads to dramatically increased performance in recurrent neural language modeling.
LEAF: A Benchmark for Federated Settings
Jan 09, 2019


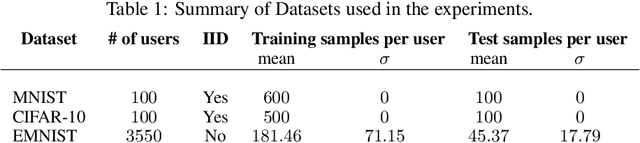
Modern federated networks, such as those comprised of wearable devices, mobile phones, or autonomous vehicles, generate massive amounts of data each day. This wealth of data can help to learn models that can improve the user experience on each device. However, learning in federated settings presents new challenges at all stages of the machine learning pipeline. As the machine learning community begins to tackle these challenges, we are at a critical time to ensure that developments made in this area are grounded in real-world assumptions. To this end, we propose LEAF, a modular benchmarking framework for learning in federated settings. LEAF includes a suite of open-source federated datasets, a rigorous evaluation framework, and a set of reference implementations, all geared toward capturing the obstacles and intricacies of practical federated environments.
Expanding the Reach of Federated Learning by Reducing Client Resource Requirements
Jan 08, 2019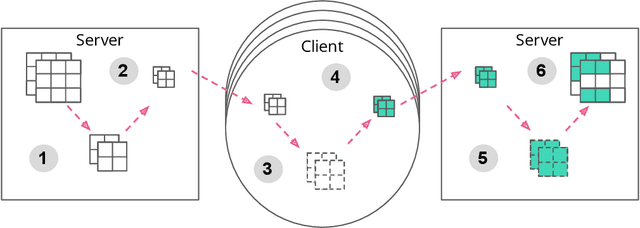
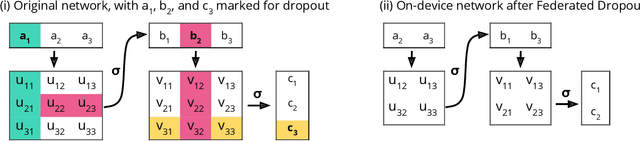

Communication on heterogeneous edge networks is a fundamental bottleneck in Federated Learning (FL), restricting both model capacity and user participation. To address this issue, we introduce two novel strategies to reduce communication costs: (1) the use of lossy compression on the global model sent server-to-client; and (2) Federated Dropout, which allows users to efficiently train locally on smaller subsets of the global model and also provides a reduction in both client-to-server communication and local computation. We empirically show that these strategies, combined with existing compression approaches for client-to-server communication, collectively provide up to a $14\times$ reduction in server-to-client communication, a $1.7\times$ reduction in local computation, and a $28\times$ reduction in upload communication, all without degrading the quality of the final model. We thus comprehensively reduce FL's impact on client device resources, allowing higher capacity models to be trained, and a more diverse set of users to be reached.