 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering Latent Pathological Signatures in Pulmonary CT via Cross-Window Knowledge Distillation
May 12, 2026Multi-window CT imaging captures complementary pathological information across anatomical structures of differing densities, yet existing deep learning methods fuse representations only at later stages, missing cross-density interactions. We propose a cross-window knowledge distillation framework in which student encoders learn latent clinical priors from a teacher trained on the most informative window. Evaluated retrospectively on three cohorts - COPD-CT-DF (n=719), RSNA PE (n=1,433), and an in-house CTEPD dataset (n=161) - distillation improved per-window AUC by 10.1-16.5 percentage points on COPD-CT-DF (0.75-0.81 to 0.90-0.94; all P<0.001), with ensemble AUC reaching 0.9960. Similar gains were observed on RSNA PE (0.80-0.83 to 0.90-0.92) and CTEPD (AUC 0.7481 vs. 0.6264). Cross-window distillation internalises pathological signatures invisible to supervised approaches, offering a generalisable solution for multi-window pulmonary CT analysis.
Differentially Private Model Merging
Apr 22, 2026In machine learning applications, privacy requirements during inference or deployment time could change constantly due to varying policies, regulations, or user experience. In this work, we aim to generate a magnitude of models to satisfy any target differential privacy (DP) requirement without additional training steps, given a set of existing models trained on the same dataset with different privacy/utility tradeoffs. We propose two post processing techniques, namely random selection and linear combination, to output a final private model for any target privacy parameter. We provide privacy accounting of these approaches from the lens of R'enyi DP and privacy loss distributions for general problems. In a case study on private mean estimation, we fully characterize the privacy/utility results and theoretically establish the superiority of linear combination over random selection. Empirically, we validate our approach and analyses on several models and both synthetic and real-world datasets.
Amber-Image: Efficient Compression of Large-Scale Diffusion Transformers
Feb 19, 2026Diffusion Transformer (DiT) architectures have significantly advanced Text-to-Image (T2I) generation but suffer from prohibitive computational costs and deployment barriers. To address these challenges, we propose an efficient compression framework that transforms the 60-layer dual-stream MMDiT-based Qwen-Image into lightweight models without training from scratch. Leveraging this framework, we introduce Amber-Image, a series of streamlined T2I models. We first derive Amber-Image-10B using a timestep-sensitive depth pruning strategy, where retained layers are reinitialized via local weight averaging and optimized through layer-wise distillation and full-parameter fine-tuning. Building on this, we develop Amber-Image-6B by introducing a hybrid-stream architecture that converts deep-layer dual streams into a single stream initialized from the image branch, further refined via progressive distillation and lightweight fine-tuning. Our approach reduces parameters by 70% and eliminates the need for large-scale data engineering. Notably, the entire compression and training pipeline-from the 10B to the 6B variant-requires fewer than 2,000 GPU hours, demonstrating exceptional cost-efficiency compared to training from scratch. Extensive evaluations on benchmarks like DPG-Bench and LongText-Bench show that Amber-Image achieves high-fidelity synthesis and superior text rendering, matching much larger models.
Tele-Omni: a Unified Multimodal Framework for Video Generation and Editing
Feb 10, 2026Recent advances in diffusion-based video generation have substantially improved visual fidelity and temporal coherence. However, most existing approaches remain task-specific and rely primarily on textual instructions, limiting their ability to handle multimodal inputs, contextual references, and diverse video generation and editing scenarios within a unified framework. Moreover, many video editing methods depend on carefully engineered pipelines tailored to individual operations, which hinders scalability and composability. In this paper, we propose Tele-Omni, a unified multimodal framework for video generation and editing that follows multimodal instructions, including text, images, and reference videos, within a single model. Tele-Omni leverages pretrained multimodal large language models to parse heterogeneous instructions and infer structured generation or editing intents, while diffusion-based generators perform high-quality video synthesis conditioned on these structured signals. To enable joint training across heterogeneous video tasks, we introduce a task-aware data processing pipeline that unifies multimodal inputs into a structured instruction format while preserving task-specific constraints. Tele-Omni supports a wide range of video-centric tasks, including text-to-video generation, image-to-video generation, first-last-frame video generation, in-context video generation, and in-context video editing. By decoupling instruction parsing from video synthesis and combining it with task-aware data design, Tele-Omni achieves flexible multimodal control while maintaining strong temporal coherence and visual consistency. Experimental results demonstrate that Tele-Omni achieves competitive performance across multiple tasks.
Evolving Without Ending: Unifying Multimodal Incremental Learning for Continual Panoptic Perception
Jan 22, 2026Continual learning (CL) is a great endeavour in developing intelligent perception AI systems. However, the pioneer research has predominantly focus on single-task CL, which restricts the potential in multi-task and multimodal scenarios. Beyond the well-known issue of catastrophic forgetting, the multi-task CL also brings semantic obfuscation across multimodal alignment, leading to severe model degradation during incremental training steps. In this paper, we extend CL to continual panoptic perception (CPP), integrating multimodal and multi-task CL to enhance comprehensive image perception through pixel-level, instance-level, and image-level joint interpretation. We formalize the CL task in multimodal scenarios and propose an end-to-end continual panoptic perception model. Concretely, CPP model features a collaborative cross-modal encoder (CCE) for multimodal embedding. We also propose a malleable knowledge inheritance module via contrastive feature distillation and instance distillation, addressing catastrophic forgetting from task-interactive boosting manner. Furthermore, we propose a cross-modal consistency constraint and develop CPP+, ensuring multimodal semantic alignment for model updating under multi-task incremental scenarios. Additionally, our proposed model incorporates an asymmetric pseudo-labeling manner, enabling model evolving without exemplar replay. Extensive experiments on multimodal datasets and diverse CL tasks demonstrate the superiority of the proposed model, particularly in fine-grained CL tasks.
TeleWorld: Towards Dynamic Multimodal Synthesis with a 4D World Model
Dec 31, 2025World models aim to endow AI systems with the ability to represent, generate, and interact with dynamic environments in a coherent and temporally consistent manner. While recent video generation models have demonstrated impressive visual quality, they remain limited in real-time interaction, long-horizon consistency, and persistent memory of dynamic scenes, hindering their evolution into practical world models. In this report, we present TeleWorld, a real-time multimodal 4D world modeling framework that unifies video generation, dynamic scene reconstruction, and long-term world memory within a closed-loop system. TeleWorld introduces a novel generation-reconstruction-guidance paradigm, where generated video streams are continuously reconstructed into a dynamic 4D spatio-temporal representation, which in turn guides subsequent generation to maintain spatial, temporal, and physical consistency. To support long-horizon generation with low latency, we employ an autoregressive diffusion-based video model enhanced with Macro-from-Micro Planning (MMPL)--a hierarchical planning method that reduces error accumulation from frame-level to segment-level-alongside efficient Distribution Matching Distillation (DMD), enabling real-time synthesis under practical computational budgets. Our approach achieves seamless integration of dynamic object modeling and static scene representation within a unified 4D framework, advancing world models toward practical, interactive, and computationally accessible systems. Extensive experiments demonstrate that TeleWorld achieves strong performance in both static and dynamic world understanding, long-term consistency, and real-time generation efficiency, positioning it as a practical step toward interactive, memory-enabled world models for multimodal generation and embodied intelligence.
Hold Onto That Thought: Assessing KV Cache Compression On Reasoning
Dec 12, 2025Large language models (LLMs) have demonstrated remarkable performance on long-context tasks, but are often bottlenecked by memory constraints. Namely, the KV cache, which is used to significantly speed up attention computations, grows linearly with context length. A suite of compression algorithms has been introduced to alleviate cache growth by evicting unimportant tokens. However, several popular strategies are targeted towards the prefill phase, i.e., processing long prompt context, and their performance is rarely assessed on reasoning tasks requiring long decoding. In particular, short but complex prompts, such as those in benchmarks like GSM8K and MATH500, often benefit from multi-step reasoning and self-reflection, resulting in thinking sequences thousands of tokens long. In this work, we benchmark the performance of several popular compression strategies on long-reasoning tasks. For the non-reasoning Llama-3.1-8B-Instruct, we determine that no singular strategy fits all, and that performance is heavily influenced by dataset type. However, we discover that H2O and our decoding-enabled variant of SnapKV are dominant strategies for reasoning models, indicating the utility of heavy-hitter tracking for reasoning traces. We also find that eviction strategies at low budgets can produce longer reasoning traces, revealing a tradeoff between cache size and inference costs.
Private Zeroth-Order Optimization with Public Data
Nov 13, 2025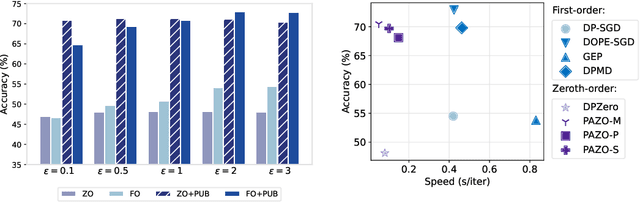

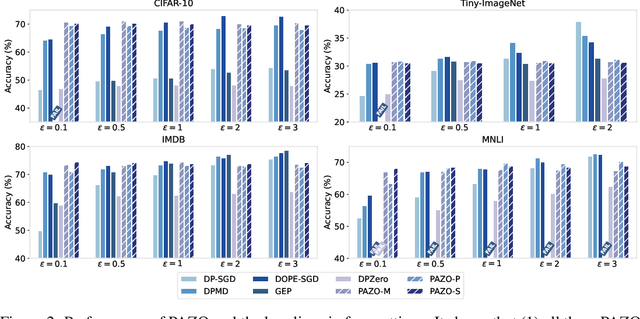
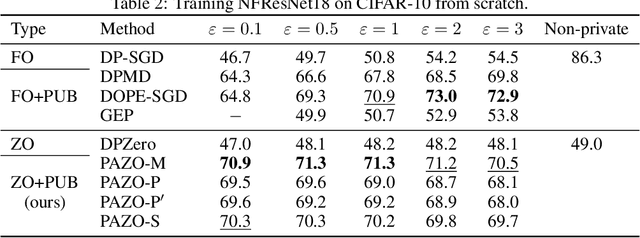
One of the major bottlenecks for deploying popular first-order differentially private (DP) machine learning algorithms (e.g., DP-SGD) lies in their high computation and memory cost, despite the existence of optimized implementations. Zeroth-order methods have promise in mitigating the overhead, as they leverage function evaluations to approximate the gradients, hence significantly easier to privatize. While recent works have explored zeroth-order approaches in both private and non-private settings, they still suffer from relatively low utilities compared with DP-SGD, and have only been evaluated in limited application domains. In this work, we propose to leverage public information to guide and improve gradient approximation of private zeroth-order algorithms. We explore a suite of public-data-assisted zeroth-order optimizers (PAZO) with minimal overhead. We provide theoretical analyses of the PAZO framework under an assumption of the similarity between public and private data. Empirically, we demonstrate that PAZO achieves superior privacy/utility tradeoffs across vision and text tasks in both pre-training and fine-tuning settings, outperforming the best first-order baselines (with public data) especially in highly private regimes, while offering up to $16\times$ runtime speedup.
Differentially Private Federated Clustering with Random Rebalancing
Aug 08, 2025Federated clustering aims to group similar clients into clusters and produce one model for each cluster. Such a personalization approach typically improves model performance compared with training a single model to serve all clients, but can be more vulnerable to privacy leakage. Directly applying client-level differentially private (DP) mechanisms to federated clustering could degrade the utilities significantly. We identify that such deficiencies are mainly due to the difficulties of averaging privacy noise within each cluster (following standard privacy mechanisms), as the number of clients assigned to the same clusters is uncontrolled. To this end, we propose a simple and effective technique, named RR-Cluster, that can be viewed as a light-weight add-on to many federated clustering algorithms. RR-Cluster achieves reduced privacy noise via randomly rebalancing cluster assignments, guaranteeing a minimum number of clients assigned to each cluster. We analyze the tradeoffs between decreased privacy noise variance and potentially increased bias from incorrect assignments and provide convergence bounds for RR-Clsuter. Empirically, we demonstrate the RR-Cluster plugged into strong federated clustering algorithms results in significantly improved privacy/utility tradeoffs across both synthetic and real-world datasets.
Stochastic Alignments: Matching an Observed Trace to Stochastic Process Models
Jul 09, 2025Process mining leverages event data extracted from IT systems to generate insights into the business processes of organizations. Such insights benefit from explicitly considering the frequency of behavior in business processes, which is captured by stochastic process models. Given an observed trace and a stochastic process model, conventional alignment-based conformance checking techniques face a fundamental limitation: They prioritize matching the trace to a model path with minimal deviations, which may, however, lead to selecting an unlikely path. In this paper, we study the problem of matching an observed trace to a stochastic process model by identifying a likely model path with a low edit distance to the trace. We phrase this as an optimization problem and develop a heuristic-guided path-finding algorithm to solve it. Our open-source implementation demonstrates the feasibility of the approach and shows that it can provide new, useful diagnostic insights for analysts.