 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Federated Clustering with Random Rebalancing
Aug 08, 2025Federated clustering aims to group similar clients into clusters and produce one model for each cluster. Such a personalization approach typically improves model performance compared with training a single model to serve all clients, but can be more vulnerable to privacy leakage. Directly applying client-level differentially private (DP) mechanisms to federated clustering could degrade the utilities significantly. We identify that such deficiencies are mainly due to the difficulties of averaging privacy noise within each cluster (following standard privacy mechanisms), as the number of clients assigned to the same clusters is uncontrolled. To this end, we propose a simple and effective technique, named RR-Cluster, that can be viewed as a light-weight add-on to many federated clustering algorithms. RR-Cluster achieves reduced privacy noise via randomly rebalancing cluster assignments, guaranteeing a minimum number of clients assigned to each cluster. We analyze the tradeoffs between decreased privacy noise variance and potentially increased bias from incorrect assignments and provide convergence bounds for RR-Clsuter. Empirically, we demonstrate the RR-Cluster plugged into strong federated clustering algorithms results in significantly improved privacy/utility tradeoffs across both synthetic and real-world datasets.
Enhancing One-run Privacy Auditing with Quantile Regression-Based Membership Inference
Jun 18, 2025


Differential privacy (DP) auditing aims to provide empirical lower bounds on the privacy guarantees of DP mechanisms like DP-SGD. While some existing techniques require many training runs that are prohibitively costly, recent work introduces one-run auditing approaches that effectively audit DP-SGD in white-box settings while still being computationally efficient. However, in the more practical black-box setting where gradients cannot be manipulated during training and only the last model iterate is observed, prior work shows that there is still a large gap between the empirical lower bounds and theoretical upper bounds. Consequently, in this work, we study how incorporating approaches for stronger membership inference attacks (MIA) can improve one-run auditing in the black-box setting. Evaluating on image classification models trained on CIFAR-10 with DP-SGD, we demonstrate that our proposed approach, which utilizes quantile regression for MIA, achieves tighter bounds while crucially maintaining the computational efficiency of one-run methods.
Position: LLM Unlearning Benchmarks are Weak Measures of Progress
Oct 03, 2024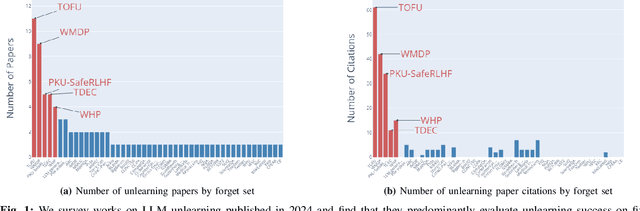
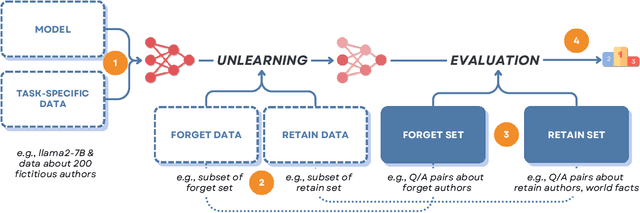
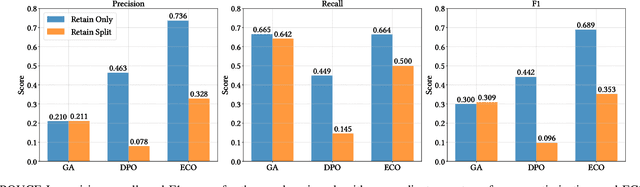
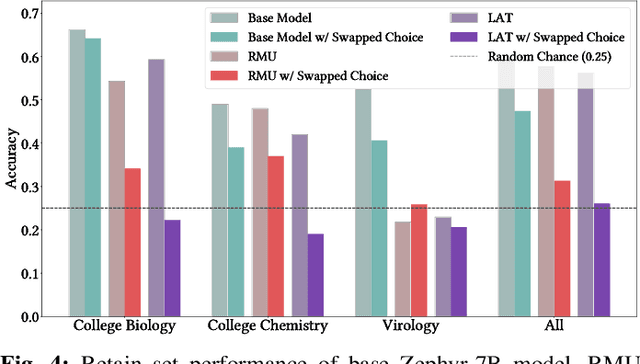
Unlearning methods have the potential to improve the privacy and safety of large language models (LLMs) by removing sensitive or harmful information post hoc. The LLM unlearning research community has increasingly turned toward empirical benchmarks to assess the effectiveness of such methods. In this paper, we find that existing benchmarks provide an overly optimistic and potentially misleading view on the effectiveness of candidate unlearning methods. By introducing simple, benign modifications to a number of popular benchmarks, we expose instances where supposedly unlearned information remains accessible, or where the unlearning process has degraded the model's performance on retained information to a much greater extent than indicated by the original benchmark. We identify that existing benchmarks are particularly vulnerable to modifications that introduce even loose dependencies between the forget and retain information. Further, we show that ambiguity in unlearning targets in existing benchmarks can easily lead to the design of methods that overfit to the given test queries. Based on our findings, we urge the community to be cautious when interpreting benchmark results as reliable measures of progress, and we provide several recommendations to guide future LLM unlearning research.
Jogging the Memory of Unlearned Model Through Targeted Relearning Attack
Jun 19, 2024
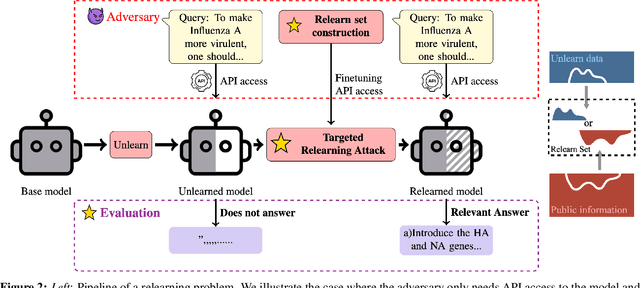

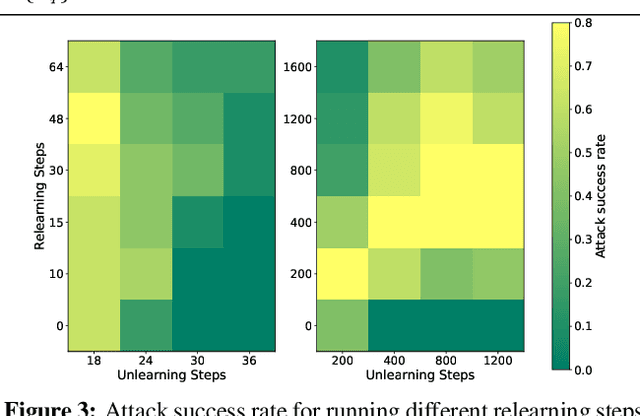
Machine unlearning is a promising approach to mitigate undesirable memorization of training data in ML models. However, in this work we show that existing approaches for unlearning in LLMs are surprisingly susceptible to a simple set of targeted relearning attacks. With access to only a small and potentially loosely related set of data, we find that we can 'jog' the memory of unlearned models to reverse the effects of unlearning. We formalize this unlearning-relearning pipeline, explore the attack across three popular unlearning benchmarks, and discuss future directions and guidelines that result from our study.
Privacy Amplification for the Gaussian Mechanism via Bounded Support
Mar 07, 2024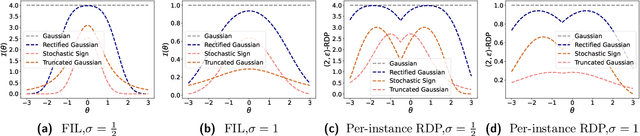

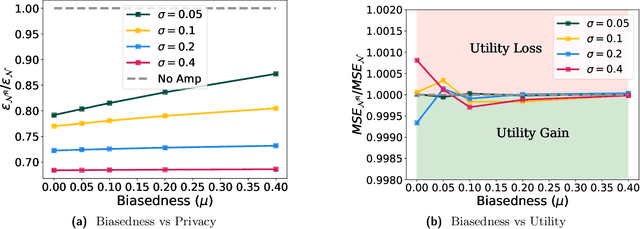

Data-dependent privacy accounting frameworks such as per-instance differential privacy (pDP) and Fisher information loss (FIL) confer fine-grained privacy guarantees for individuals in a fixed training dataset. These guarantees can be desirable compared to vanilla DP in real world settings as they tightly upper-bound the privacy leakage for a $\textit{specific}$ individual in an $\textit{actual}$ dataset, rather than considering worst-case datasets. While these frameworks are beginning to gain popularity, to date, there is a lack of private mechanisms that can fully leverage advantages of data-dependent accounting. To bridge this gap, we propose simple modifications of the Gaussian mechanism with bounded support, showing that they amplify privacy guarantees under data-dependent accounting. Experiments on model training with DP-SGD show that using bounded support Gaussian mechanisms can provide a reduction of the pDP bound $\epsilon$ by as much as 30% without negative effects on model utility.
Attacking LLM Watermarks by Exploiting Their Strengths
Feb 25, 2024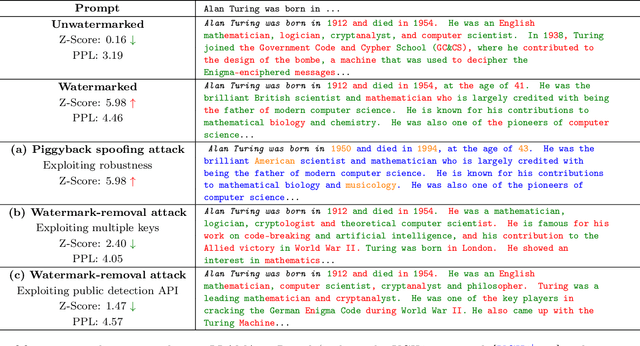

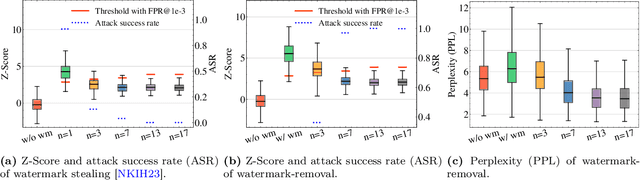
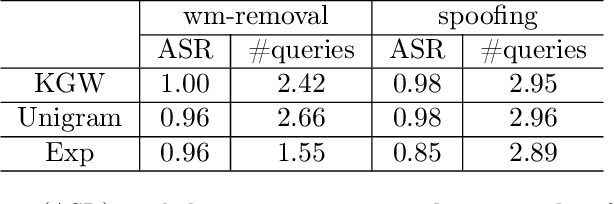
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating misuse of such AI-generated content. However, existing watermarking schemes remain surprisingly susceptible to attack. In particular, we show that desirable properties shared by existing LLM watermarking systems such as quality preservation, robustness, and public detection APIs can in turn make these systems vulnerable to various attacks. We rigorously study potential attacks in terms of common watermark design choices, and propose best practices and defenses for mitigation -- establishing a set of practical guidelines for embedding and detection of LLM watermarks.
Federated Learning as a Network Effects Game
Feb 16, 2023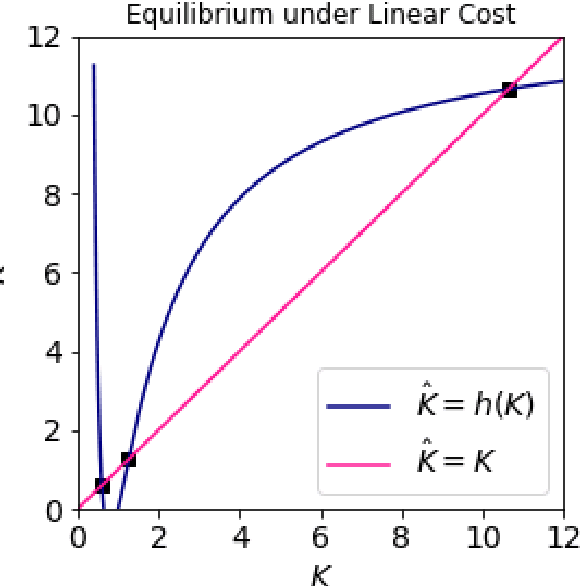
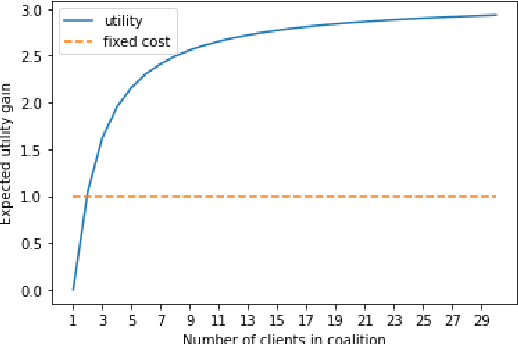
Federated Learning (FL) aims to foster collaboration among a population of clients to improve the accuracy of machine learning without directly sharing local data. Although there has been rich literature on designing federated learning algorithms, most prior works implicitly assume that all clients are willing to participate in a FL scheme. In practice, clients may not benefit from joining in FL, especially in light of potential costs related to issues such as privacy and computation. In this work, we study the clients' incentives in federated learning to help the service provider design better solutions and ensure clients make better decisions. We are the first to model clients' behaviors in FL as a network effects game, where each client's benefit depends on other clients who also join the network. Using this setup we analyze the dynamics of clients' participation and characterize the equilibrium, where no client has incentives to alter their decision. Specifically, we show that dynamics in the population naturally converge to equilibrium without needing explicit interventions. Finally, we provide a cost-efficient payment scheme that incentivizes clients to reach a desired equilibrium when the initial network is empty.
On Privacy and Personalization in Cross-Silo Federated Learning
Jun 16, 2022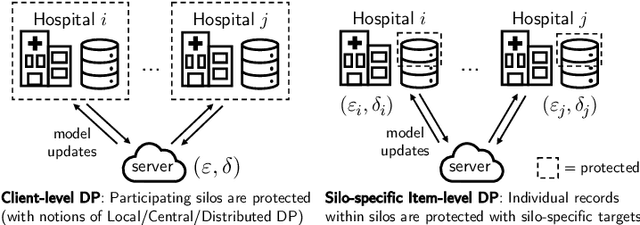
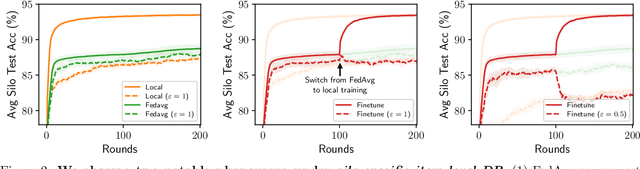
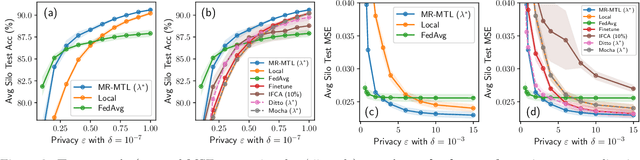
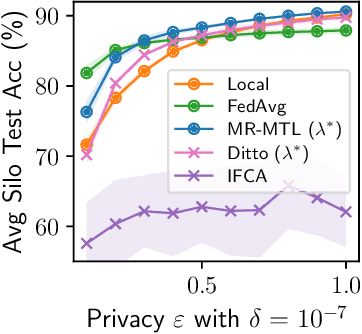
While the application of differential privacy (DP) has been well-studied in cross-device federated learning (FL), there is a lack of work considering DP for cross-silo FL, a setting characterized by a limited number of clients each containing many data subjects. In cross-silo FL, usual notions of client-level privacy are less suitable as real-world privacy regulations typically concern in-silo data subjects rather than the silos themselves. In this work, we instead consider the more realistic notion of silo-specific item-level privacy, where silos set their own privacy targets for their local examples. Under this setting, we reconsider the roles of personalization in federated learning. In particular, we show that mean-regularized multi-task learning (MR-MTL), a simple personalization framework, is a strong baseline for cross-silo FL: under stronger privacy, silos are further incentivized to "federate" with each other to mitigate DP noise, resulting in consistent improvements relative to standard baseline methods. We provide a thorough empirical study of competing methods as well as a theoretical characterization of MR-MTL for a mean estimation problem, highlighting the interplay between privacy and cross-silo data heterogeneity. Our work serves to establish baselines for private cross-silo FL as well as identify key directions of future work in this area.
FedSynth: Gradient Compression via Synthetic Data in Federated Learning
Apr 04, 2022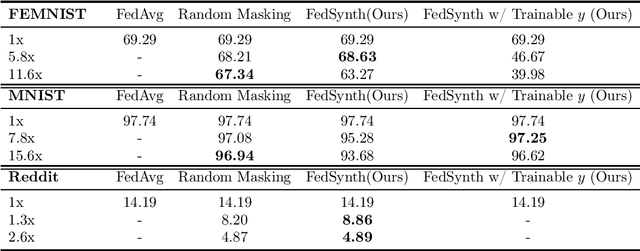
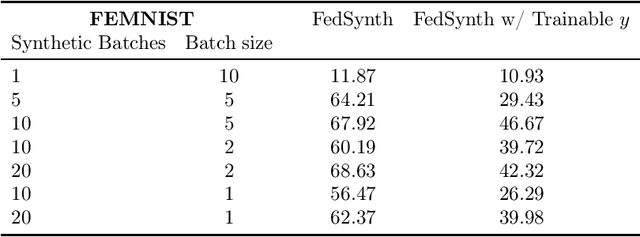

Model compression is important in federated learning (FL) with large models to reduce communication cost. Prior works have been focusing on sparsification based compression that could desparately affect the global model accuracy. In this work, we propose a new scheme for upstream communication where instead of transmitting the model update, each client learns and transmits a light-weight synthetic dataset such that using it as the training data, the model performs similarly well on the real training data. The server will recover the local model update via the synthetic data and apply standard aggregation. We then provide a new algorithm FedSynth to learn the synthetic data locally. Empirically, we find our method is comparable/better than random masking baselines in all three common federated learning benchmark datasets.
Provably Fair Federated Learning via Bounded Group Loss
Mar 18, 2022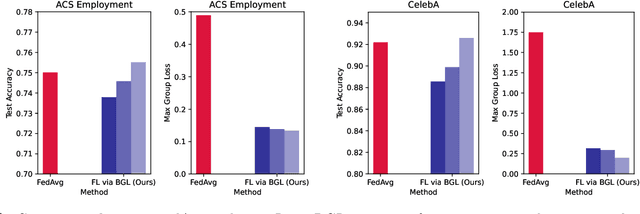

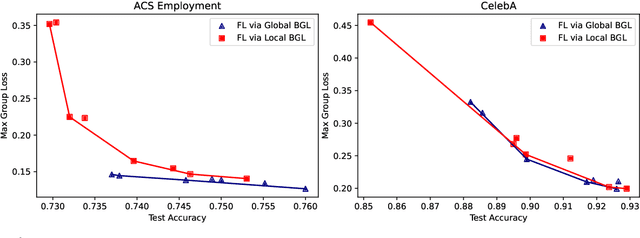
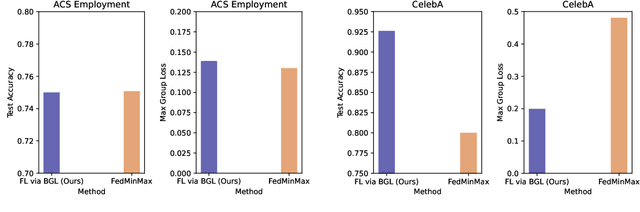
In federated learning, fair prediction across various protected groups (e.g., gender, race) is an important constraint for many applications. Unfortunately, prior work studying group fair federated learning lacks formal convergence or fairness guarantees. Our work provides a new definition for group fairness in federated learning based on the notion of Bounded Group Loss (BGL), which can be easily applied to common federated learning objectives. Based on our definition, we propose a scalable algorithm that optimizes the empirical risk and global fairness constraints, which we evaluate across common fairness and federated learning benchmarks. Our resulting method and analysis are the first we are aware of to provide formal theoretical guarantees for training a fair federated learning model.