 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttacking LLM Watermarks by Exploiting Their Strengths
Paper and Code
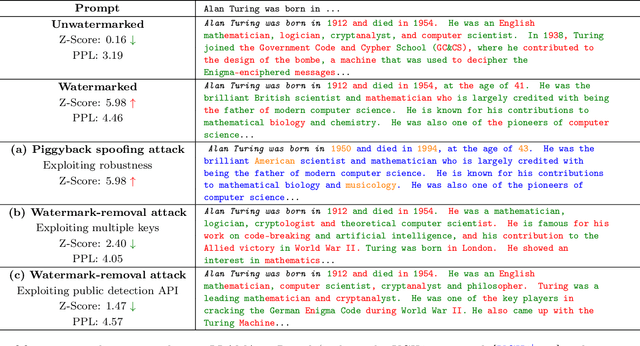

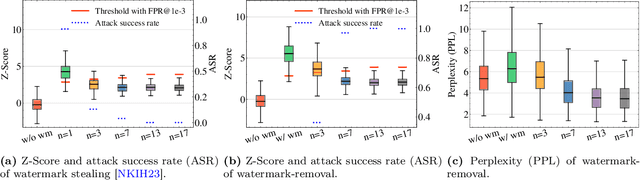
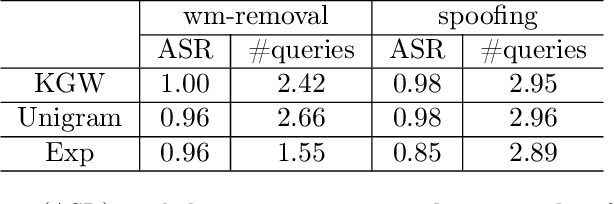
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating misuse of such AI-generated content. However, existing watermarking schemes remain surprisingly susceptible to attack. In particular, we show that desirable properties shared by existing LLM watermarking systems such as quality preservation, robustness, and public detection APIs can in turn make these systems vulnerable to various attacks. We rigorously study potential attacks in terms of common watermark design choices, and propose best practices and defenses for mitigation -- establishing a set of practical guidelines for embedding and detection of LLM watermarks.