 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivasis: Synthesizing the Largest "Public" Private Dataset from Scratch
Feb 03, 2026Research involving privacy-sensitive data has always been constrained by data scarcity, standing in sharp contrast to other areas that have benefited from data scaling. This challenge is becoming increasingly urgent as modern AI agents--such as OpenClaw and Gemini Agent--are granted persistent access to highly sensitive personal information. To tackle this longstanding bottleneck and the rising risks, we present Privasis (i.e., privacy oasis), the first million-scale fully synthetic dataset entirely built from scratch--an expansive reservoir of texts with rich and diverse private information--designed to broaden and accelerate research in areas where processing sensitive social data is inevitable. Compared to existing datasets, Privasis, comprising 1.4 million records, offers orders-of-magnitude larger scale with quality, and far greater diversity across various document types, including medical history, legal documents, financial records, calendars, and text messages with a total of 55.1 million annotated attributes such as ethnicity, date of birth, workplace, etc. We leverage Privasis to construct a parallel corpus for text sanitization with our pipeline that decomposes texts and applies targeted sanitization. Our compact sanitization models (<=4B) trained on this dataset outperform state-of-the-art large language models, such as GPT-5 and Qwen-3 235B. We plan to release data, models, and code to accelerate future research on privacy-sensitive domains and agents.
BadMoE: Backdooring Mixture-of-Experts LLMs via Optimizing Routing Triggers and Infecting Dormant Experts
Apr 29, 2025



Mixture-of-Experts (MoE) have emerged as a powerful architecture for large language models (LLMs), enabling efficient scaling of model capacity while maintaining manageable computational costs. The key advantage lies in their ability to route different tokens to different ``expert'' networks within the model, enabling specialization and efficient handling of diverse input. However, the vulnerabilities of MoE-based LLMs still have barely been studied, and the potential for backdoor attacks in this context remains largely unexplored. This paper presents the first backdoor attack against MoE-based LLMs where the attackers poison ``dormant experts'' (i.e., underutilized experts) and activate them by optimizing routing triggers, thereby gaining control over the model's output. We first rigorously prove the existence of a few ``dominating experts'' in MoE models, whose outputs can determine the overall MoE's output. We also show that dormant experts can serve as dominating experts to manipulate model predictions. Accordingly, our attack, namely BadMoE, exploits the unique architecture of MoE models by 1) identifying dormant experts unrelated to the target task, 2) constructing a routing-aware loss to optimize the activation triggers of these experts, and 3) promoting dormant experts to dominating roles via poisoned training data. Extensive experiments show that BadMoE successfully enforces malicious prediction on attackers' target tasks while preserving overall model utility, making it a more potent and stealthy attack than existing methods.
Communication Bounds for the Distributed Experts Problem
Jan 06, 2025In this work, we study the experts problem in the distributed setting where an expert's cost needs to be aggregated across multiple servers. Our study considers various communication models such as the message-passing model and the broadcast model, along with multiple aggregation functions, such as summing and taking the $\ell_p$ norm of an expert's cost across servers. We propose the first communication-efficient protocols that achieve near-optimal regret in these settings, even against a strong adversary who can choose the inputs adaptively. Additionally, we give a conditional lower bound showing that the communication of our protocols is nearly optimal. Finally, we implement our protocols and demonstrate empirical savings on the HPO-B benchmarks.
Attacking LLM Watermarks by Exploiting Their Strengths
Feb 25, 2024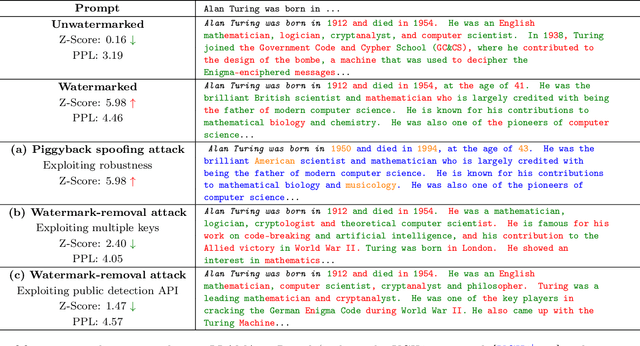

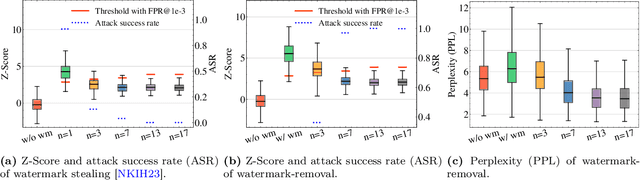
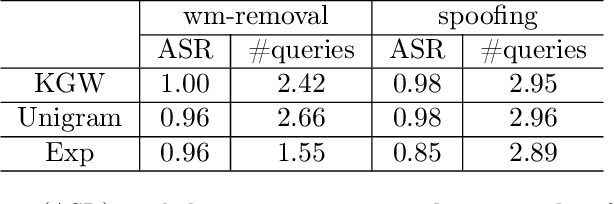
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking, a technique that aims to embed information in the output of a model to verify its source, is useful for mitigating misuse of such AI-generated content. However, existing watermarking schemes remain surprisingly susceptible to attack. In particular, we show that desirable properties shared by existing LLM watermarking systems such as quality preservation, robustness, and public detection APIs can in turn make these systems vulnerable to various attacks. We rigorously study potential attacks in terms of common watermark design choices, and propose best practices and defenses for mitigation -- establishing a set of practical guidelines for embedding and detection of LLM watermarks.
Byzantine-Robust Federated Learning with Optimal Statistical Rates and Privacy Guarantees
May 24, 2022


We propose Byzantine-robust federated learning protocols with nearly optimal statistical rates. In contrast to prior work, our proposed protocols improve the dimension dependence and achieve a tight statistical rate in terms of all the parameters for strongly convex losses. We benchmark against competing protocols and show the empirical superiority of the proposed protocols. Finally, we remark that our protocols with bucketing can be naturally combined with privacy-guaranteeing procedures to introduce security against a semi-honest server. The code for evaluation is provided in https://github.com/wanglun1996/secure-robust-federated-learning.
Attacking Vertical Collaborative Learning System Using Adversarial Dominating Inputs
Jan 08, 2022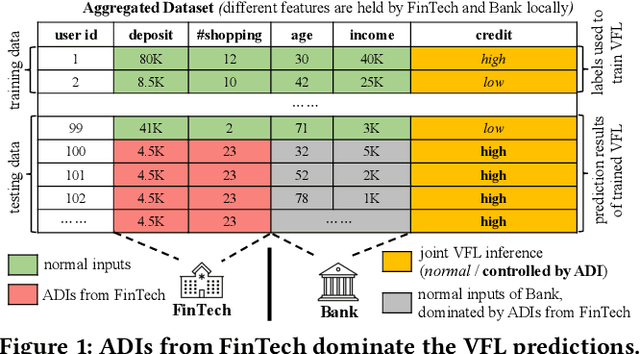
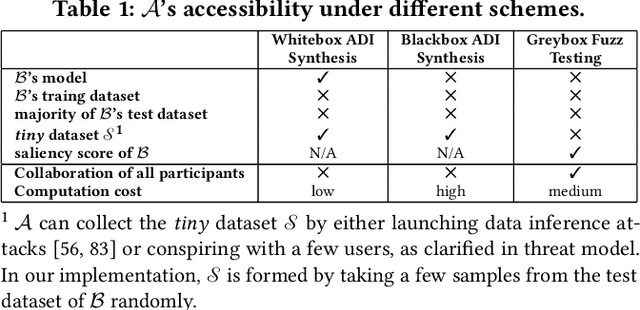
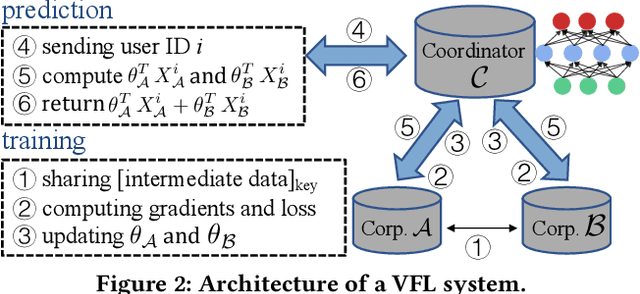

Vertical collaborative learning system also known as vertical federated learning (VFL) system has recently become prominent as a concept to process data distributed across many individual sources without the need to centralize it. Multiple participants collaboratively train models based on their local data in a privacy-preserving manner. To date, VFL has become a de facto solution to securely learn a model among organizations, allowing knowledge to be shared without compromising privacy of any individual organizations. Despite the prosperous development of VFL systems, we find that certain inputs of a participant, named adversarial dominating inputs (ADIs), can dominate the joint inference towards the direction of the adversary's will and force other (victim) participants to make negligible contributions, losing rewards that are usually offered regarding the importance of their contributions in collaborative learning scenarios. We conduct a systematic study on ADIs by first proving their existence in typical VFL systems. We then propose gradient-based methods to synthesize ADIs of various formats and exploit common VFL systems. We further launch greybox fuzz testing, guided by the resiliency score of "victim" participants, to perturb adversary-controlled inputs and systematically explore the VFL attack surface in a privacy-preserving manner. We conduct an in-depth study on the influence of critical parameters and settings in synthesizing ADIs. Our study reveals new VFL attack opportunities, promoting the identification of unknown threats before breaches and building more secure VFL systems.
MDPFuzzer: Finding Crash-Triggering State Sequences in Models Solving the Markov Decision Process
Dec 12, 2021
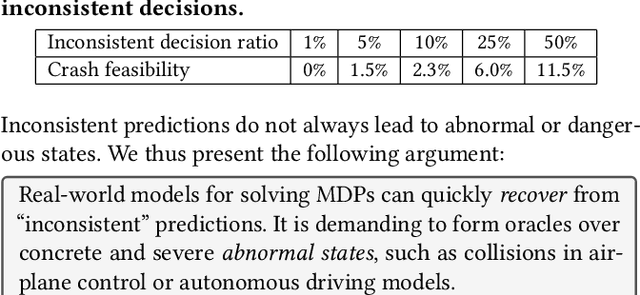


The Markov decision process (MDP) provides a mathematical framework for modeling sequential decision-making problems, many of which are crucial to security and safety, such as autonomous driving and robot control. The rapid development of artificial intelligence research has created efficient methods for solving MDPs, such as deep neural networks (DNNs), reinforcement learning (RL), and imitation learning (IL). However, these popular models for solving MDPs are neither thoroughly tested nor rigorously reliable. We present MDPFuzzer, the first blackbox fuzz testing framework for models solving MDPs. MDPFuzzer forms testing oracles by checking whether the target model enters abnormal and dangerous states. During fuzzing, MDPFuzzer decides which mutated state to retain by measuring if it can reduce cumulative rewards or form a new state sequence. We design efficient techniques to quantify the "freshness" of a state sequence using Gaussian mixture models (GMMs) and dynamic expectation-maximization (DynEM). We also prioritize states with high potential of revealing crashes by estimating the local sensitivity of target models over states. MDPFuzzer is evaluated on five state-of-the-art models for solving MDPs, including supervised DNN, RL, IL, and multi-agent RL. Our evaluation includes scenarios of autonomous driving, aircraft collision avoidance, and two games that are often used to benchmark RL. During a 12-hour run, we find over 80 crash-triggering state sequences on each model. We show inspiring findings that crash-triggering states, though look normal, induce distinct neuron activation patterns compared with normal states. We further develop an abnormal behavior detector to harden all the evaluated models and repair them with the findings of MDPFuzzer to significantly enhance their robustness without sacrificing accuracy.
Automated Side Channel Analysis of Media Software with Manifold Learning
Dec 10, 2021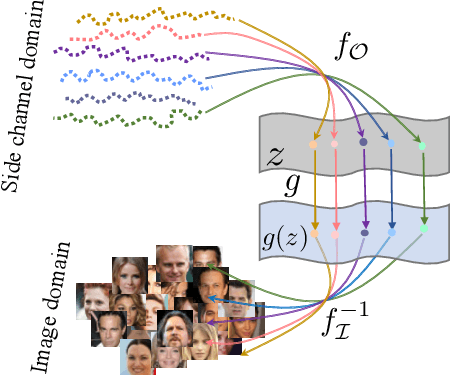

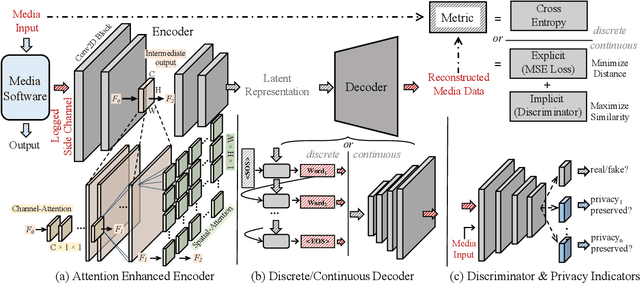

The prosperous development of cloud computing and machine learning as a service has led to the widespread use of media software to process confidential media data. This paper explores an adversary's ability to launch side channel analyses (SCA) against media software to reconstruct confidential media inputs. Recent advances in representation learning and perceptual learning inspired us to consider the reconstruction of media inputs from side channel traces as a cross-modality manifold learning task that can be addressed in a unified manner with an autoencoder framework trained to learn the mapping between media inputs and side channel observations. We further enhance the autoencoder with attention to localize the program points that make the primary contribution to SCA, thus automatically pinpointing information-leakage points in media software. We also propose a novel and highly effective defensive technique called perception blinding that can perturb media inputs with perception masks and mitigate manifold learning-based SCA. Our evaluation exploits three popular media software to reconstruct inputs in image, audio, and text formats. We analyze three common side channels - cache bank, cache line, and page tables - and userspace-only cache set accesses logged by standard Prime+Probe. Our framework successfully reconstructs high-quality confidential inputs from the assessed media software and automatically pinpoint their vulnerable program points, many of which are unknown to the public. We further show that perception blinding can mitigate manifold learning-based SCA with negligible extra cost.
Enhancing Deep Neural Networks Testing by Traversing Data Manifold
Dec 03, 2021
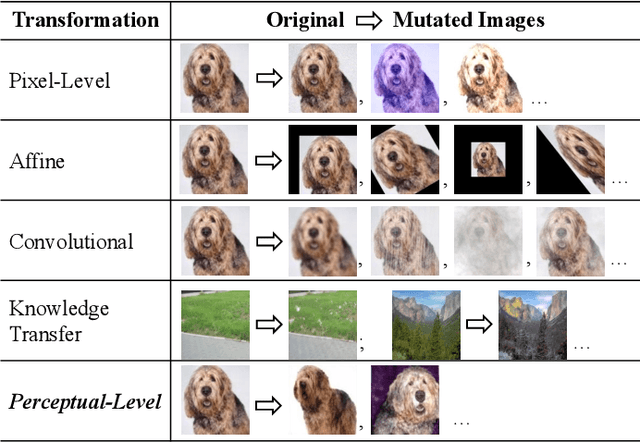
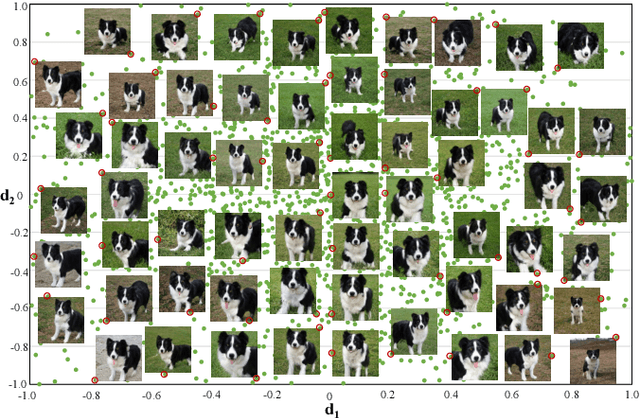
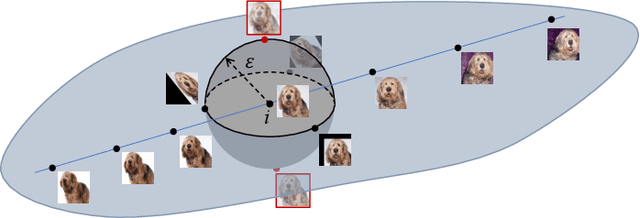
We develop DEEPTRAVERSAL, a feedback-driven framework to test DNNs. DEEPTRAVERSAL first launches an offline phase to map media data of various forms to manifolds. Then, in its online testing phase, DEEPTRAVERSAL traverses the prepared manifold space to maximize DNN coverage criteria and trigger prediction errors. In our evaluation, DNNs executing various tasks (e.g., classification, self-driving, machine translation) and media data of different types (image, audio, text) were used. DEEPTRAVERSAL exhibits better performance than prior methods with respect to popular DNN coverage criteria and it can discover a larger number and higher quality of error-triggering inputs. The tested DNN models, after being repaired with findings of DEEPTRAVERSAL, achieve better accuracy
You Can't See the Forest for Its Trees: Assessing Deep Neural Network Testing via NeuraL Coverage
Dec 03, 2021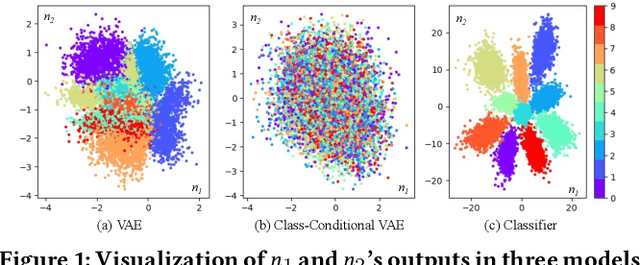


This paper summarizes eight design requirements for DNN testing criteria, taking into account distribution properties and practical concerns. We then propose a new criterion, NLC, that satisfies all of these design requirements. NLC treats a single DNN layer as the basic computational unit (rather than a single neuron) and captures four critical features of neuron output distributions. Thus, NLC is denoted as NeuraL Coverage, which more accurately describes how neural networks comprehend inputs via approximated distributions rather than neurons. We demonstrate that NLC is significantly correlated with the diversity of a test suite across a number of tasks (classification and generation) and data formats (image and text). Its capacity to discover DNN prediction errors is promising. Test input mutation guided by NLC result in a greater quality and diversity of exposed erroneous behaviors.