 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Bounds for the Distributed Experts Problem
Jan 06, 2025In this work, we study the experts problem in the distributed setting where an expert's cost needs to be aggregated across multiple servers. Our study considers various communication models such as the message-passing model and the broadcast model, along with multiple aggregation functions, such as summing and taking the $\ell_p$ norm of an expert's cost across servers. We propose the first communication-efficient protocols that achieve near-optimal regret in these settings, even against a strong adversary who can choose the inputs adaptively. Additionally, we give a conditional lower bound showing that the communication of our protocols is nearly optimal. Finally, we implement our protocols and demonstrate empirical savings on the HPO-B benchmarks.
ContCap: A comprehensive framework for continual image captioning
Sep 19, 2019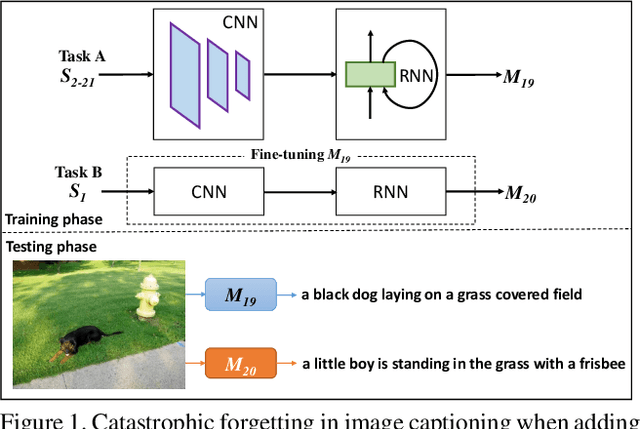


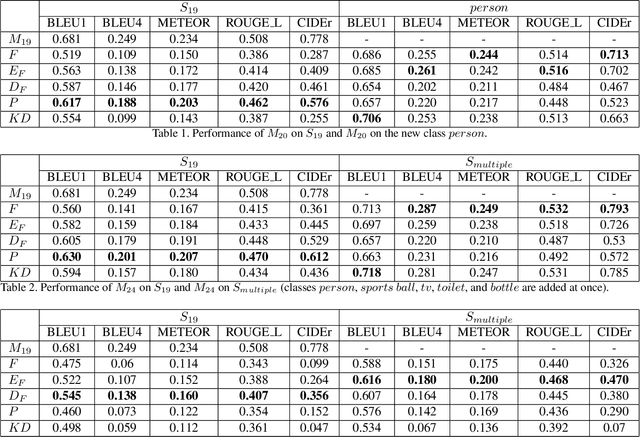
While cutting-edge image captioning systems are increasingly describing an image coherently and exactly, recent progresses in continual learning allow deep learning systems to avoid catastrophic forgetting. However, the domain where image captioning working with continual learning is not exploited yet. We define the task in which we consolidate continual learning and image captioning as continual image captioning. In this work, we propose ContCap, a framework continually generating captions over a series of new tasks coming, seamlessly integrating continual learning into image captioning accompanied by tackling catastrophic forgetting. After proving catastrophic forgetting in image captioning, we employ freezing, knowledge distillation, and pseudo-labeling techniques to overcome the forgetting dilemma with the baseline is a simple fine-tuning scheme. We split MS-COCO 2014 dataset to perform experiments on incremental tasks without revisiting dataset of previously provided tasks. The experiments are designed to increase the degree of catastrophic forgetting and appraise the capacity of approaches. Experimental results show remarkable improvements in the performance on the old tasks, while the figure for the new task remains almost the same compared to fine-tuning. For example, pseudo-labeling increases CIDEr from 0.287 to 0.576 on the old task and 0.686 down to 0.657 BLEU1 on the new task.