 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Adversarial Attacks in LLMs through Defensive Suffix Generation
Dec 18, 2024Large language models (LLMs) have exhibited outstanding performance in natural language processing tasks. However, these models remain susceptible to adversarial attacks in which slight input perturbations can lead to harmful or misleading outputs. A gradient-based defensive suffix generation algorithm is designed to bolster the robustness of LLMs. By appending carefully optimized defensive suffixes to input prompts, the algorithm mitigates adversarial influences while preserving the models' utility. To enhance adversarial understanding, a novel total loss function ($L_{\text{total}}$) combining defensive loss ($L_{\text{def}}$) and adversarial loss ($L_{\text{adv}}$) generates defensive suffixes more effectively. Experimental evaluations conducted on open-source LLMs such as Gemma-7B, mistral-7B, Llama2-7B, and Llama2-13B show that the proposed method reduces attack success rates (ASR) by an average of 11\% compared to models without defensive suffixes. Additionally, the perplexity score of Gemma-7B decreased from 6.57 to 3.93 when applying the defensive suffix generated by openELM-270M. Furthermore, TruthfulQA evaluations demonstrate consistent improvements with Truthfulness scores increasing by up to 10\% across tested configurations. This approach significantly enhances the security of LLMs in critical applications without requiring extensive retraining.
Multi-Response Preference Optimization with Augmented Ranking Dataset
Dec 10, 2024
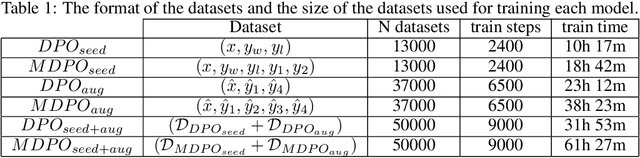
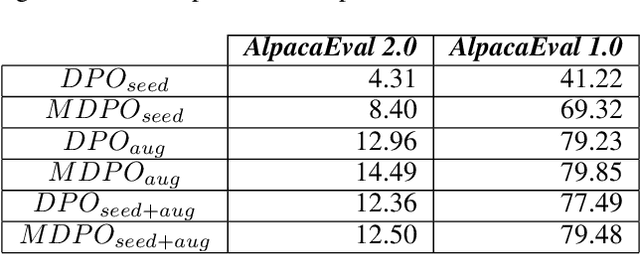

Recent advancements in Large Language Models (LLMs) have been remarkable, with new models consistently surpassing their predecessors. These advancements are underpinned by extensive research on various training mechanisms. Among these, Preference Optimization has played a significant role in improving the performance of LLMs by incorporating human preferences into the training process. However, constructing preference optimization datasets is challenging and the optimization process is highly sensitive to the dataset quality. In this study, we propose a novel approach to augment Preference Optimization datasets. Additionally, we introduce a Multi-response-based Preference Optimization training method that enables the simultaneous learning of multiple responses.
Enhancing Clinical Efficiency through LLM: Discharge Note Generation for Cardiac Patients
Apr 08, 2024Medical documentation, including discharge notes, is crucial for ensuring patient care quality, continuity, and effective medical communication. However, the manual creation of these documents is not only time-consuming but also prone to inconsistencies and potential errors. The automation of this documentation process using artificial intelligence (AI) represents a promising area of innovation in healthcare. This study directly addresses the inefficiencies and inaccuracies in creating discharge notes manually, particularly for cardiac patients, by employing AI techniques, specifically large language model (LLM). Utilizing a substantial dataset from a cardiology center, encompassing wide-ranging medical records and physician assessments, our research evaluates the capability of LLM to enhance the documentation process. Among the various models assessed, Mistral-7B distinguished itself by accurately generating discharge notes that significantly improve both documentation efficiency and the continuity of care for patients. These notes underwent rigorous qualitative evaluation by medical expert, receiving high marks for their clinical relevance, completeness, readability, and contribution to informed decision-making and care planning. Coupled with quantitative analyses, these results confirm Mistral-7B's efficacy in distilling complex medical information into concise, coherent summaries. Overall, our findings illuminate the considerable promise of specialized LLM, such as Mistral-7B, in refining healthcare documentation workflows and advancing patient care. This study lays the groundwork for further integrating advanced AI technologies in healthcare, demonstrating their potential to revolutionize patient documentation and support better care outcomes.
InMD-X: Large Language Models for Internal Medicine Doctors
Feb 20, 2024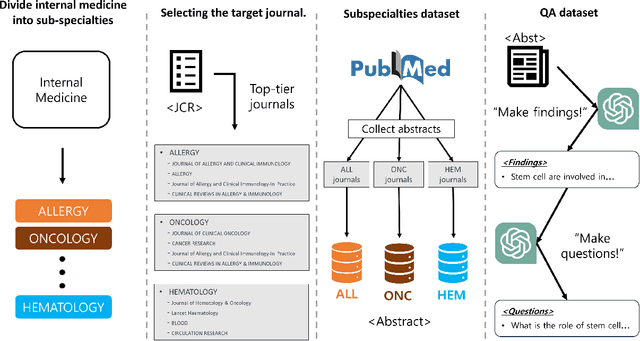
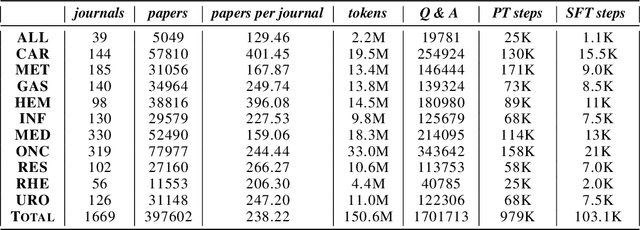
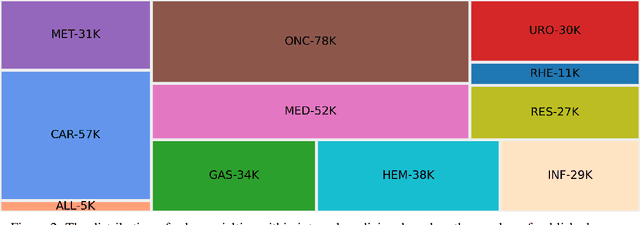

In this paper, we introduce InMD-X, a collection of multiple large language models specifically designed to cater to the unique characteristics and demands of Internal Medicine Doctors (IMD). InMD-X represents a groundbreaking development in natural language processing, offering a suite of language models fine-tuned for various aspects of the internal medicine field. These models encompass a wide range of medical sub-specialties, enabling IMDs to perform more efficient and accurate research, diagnosis, and documentation. InMD-X's versatility and adaptability make it a valuable tool for improving the healthcare industry, enhancing communication between healthcare professionals, and advancing medical research. Each model within InMD-X is meticulously tailored to address specific challenges faced by IMDs, ensuring the highest level of precision and comprehensiveness in clinical text analysis and decision support. This paper provides an overview of the design, development, and evaluation of InMD-X, showcasing its potential to revolutionize the way internal medicine practitioners interact with medical data and information. We present results from extensive testing, demonstrating the effectiveness and practical utility of InMD-X in real-world medical scenarios.
NOTE: Notable generation Of patient Text summaries through Efficient approach based on direct preference optimization
Feb 19, 2024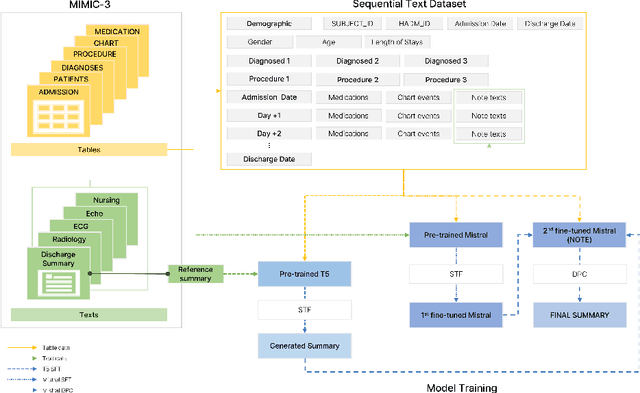
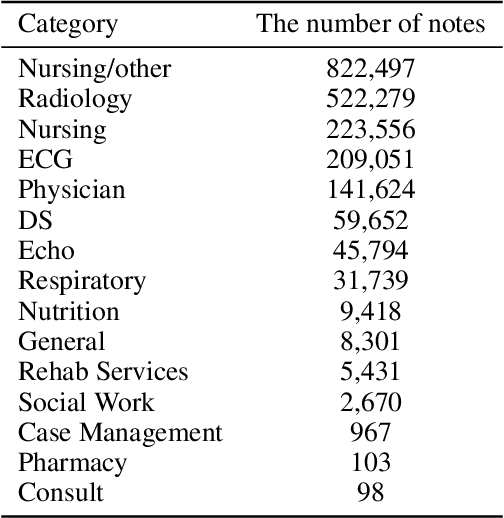
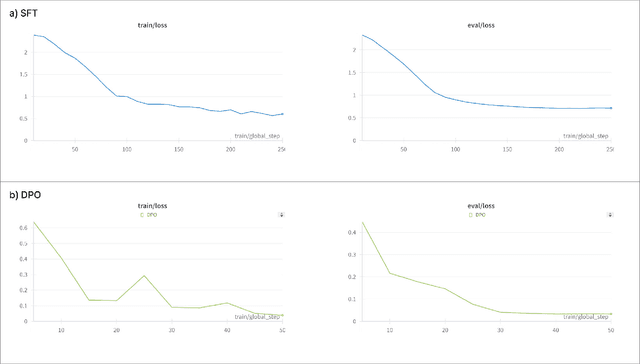

The discharge summary is a one of critical documents in the patient journey, encompassing all events experienced during hospitalization, including multiple visits, medications, tests, surgery/procedures, and admissions/discharge. Providing a summary of the patient's progress is crucial, as it significantly influences future care and planning. Consequently, clinicians face the laborious and resource-intensive task of manually collecting, organizing, and combining all the necessary data for a discharge summary. Therefore, we propose "NOTE", which stands for "Notable generation Of patient Text summaries through an Efficient approach based on direct preference optimization". NOTE is based on Medical Information Mart for Intensive Care- III dataset and summarizes a single hospitalization of a patient. Patient events are sequentially combined and used to generate a discharge summary for each hospitalization. In the present circumstances, large language models' application programming interfaces (LLMs' APIs) are widely available, but importing and exporting medical data presents significant challenges due to privacy protection policies in healthcare institutions. Moreover, to ensure optimal performance, it is essential to implement a lightweight model for internal server or program within the hospital. Therefore, we utilized DPO and parameter efficient fine tuning (PEFT) techniques to apply a fine-tuning method that guarantees superior performance. To demonstrate the practical application of the developed NOTE, we provide a webpage-based demonstration software. In the future, we will aim to deploy the software available for actual use by clinicians in hospital. NOTE can be utilized to generate various summaries not only discharge summaries but also throughout a patient's journey, thereby alleviating the labor-intensive workload of clinicians and aiming for increased efficiency.
Explaining How Deep Neural Networks Forget by Deep Visualization
May 03, 2020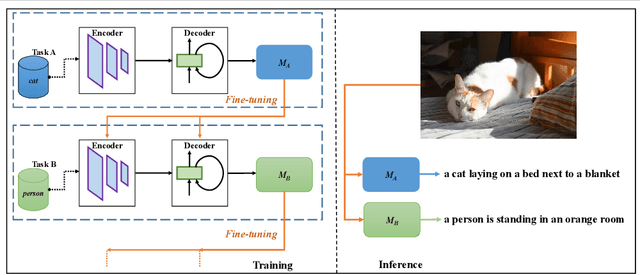
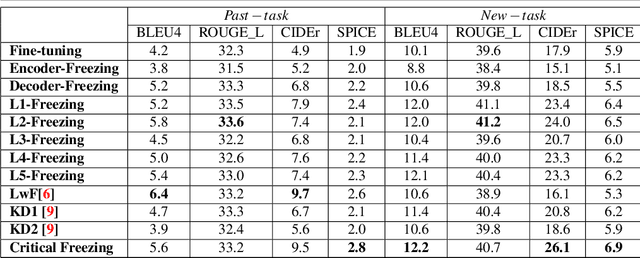
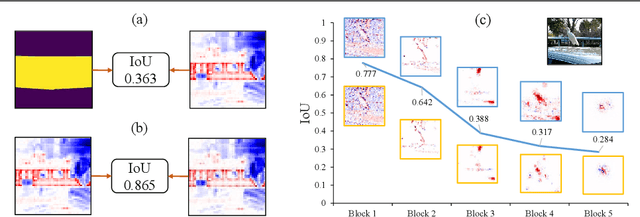
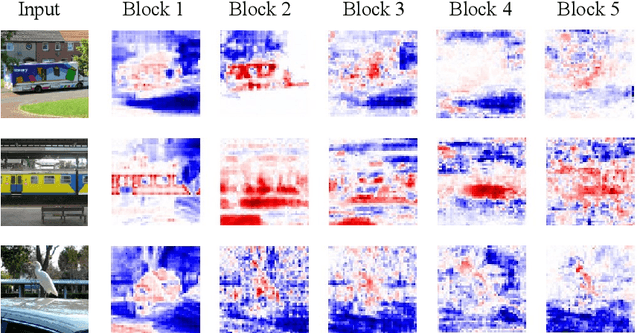
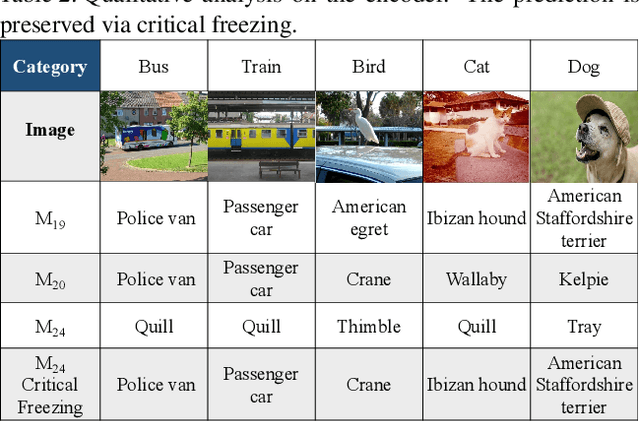
Explaining the behaviors of deep neural networks, usually considered as black boxes, is critical especially when they are now being adopted over diverse aspects of human life. Taking the advantages of interpretable machine learning (interpretable ML), this paper proposes a novel tool called Catastrophic Forgetting Dissector (or CFD) to explain catastrophic forgetting in continual learning settings. We also introduce a new method called Critical Freezing based on the observations of our tool. Experiments on ResNet articulate how catastrophic forgetting happens, particularly showing which components of this famous network are forgetting. Our new continual learning algorithm defeats various recent techniques by a significant margin, proving the capability of the investigation. Critical freezing not only attacks catastrophic forgetting but also exposes explainability.
Smart Inference for Multidigit Convolutional Neural Network based Barcode Decoding
Apr 14, 2020
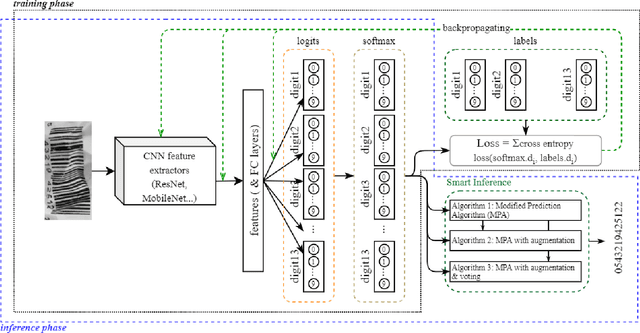
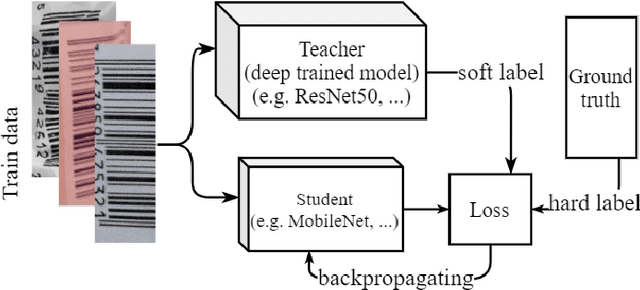
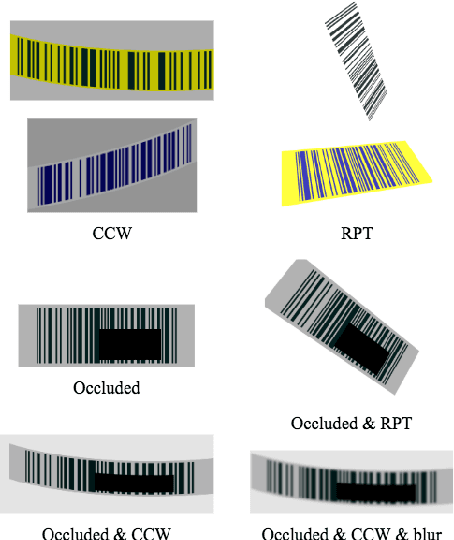
Barcodes are ubiquitous and have been used in most of critical daily activities for decades. However, most of traditional decoders require well-founded barcode under a relatively standard condition. While wilder conditioned barcodes such as underexposed, occluded, blurry, wrinkled and rotated are commonly captured in reality, those traditional decoders show weakness of recognizing. Several works attempted to solve those challenging barcodes, but many limitations still exist. This work aims to solve the decoding problem using deep convolutional neural network with the possibility of running on portable devices. Firstly, we proposed a special modification of inference based on the feature of having checksum and test-time augmentation, named as Smart Inference (SI) in prediction phase of a trained model. SI considerably boosts accuracy and reduces the false prediction for trained models. Secondly, we have created a large practical evaluation dataset of real captured 1D barcode under various challenging conditions to test our methods vigorously, which is publicly available for other researchers. The experiments' results demonstrated the SI effectiveness with the highest accuracy of 95.85% which outperformed many existing decoders on the evaluation set. Finally, we successfully minimized the best model by knowledge distillation to a shallow model which is shown to have high accuracy (90.85%) with good inference speed of 34.2 ms per image on a real edge device.
Applying Tensor Decomposition to image for Robustness against Adversarial Attack
Mar 05, 2020
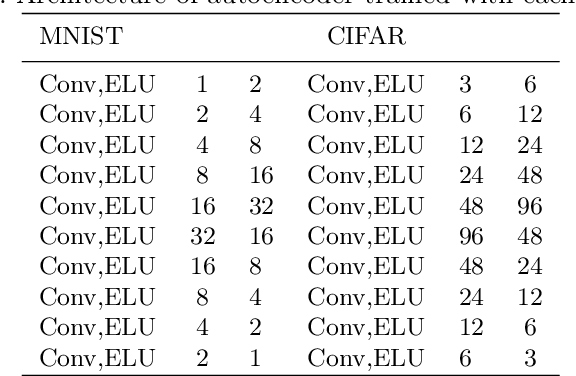
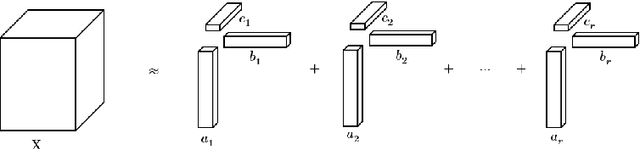
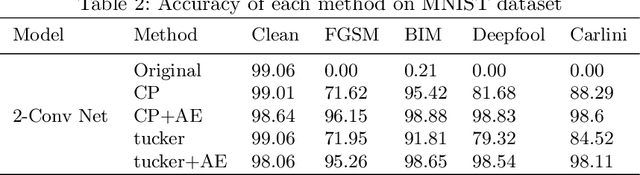
Nowadays the deep learning technology is growing faster and shows dramatic performance in computer vision areas. However, it turns out a deep learning based model is highly vulnerable to some small perturbation called an adversarial attack. It can easily fool the deep learning model by adding small perturbations. On the other hand, tensor decomposition method widely uses for compressing the tensor data, including data matrix, image, etc. In this paper, we suggest combining tensor decomposition for defending the model against adversarial example. We verify this idea is simple and effective to resist adversarial attack. In addition, this method rarely degrades the original performance of clean data. We experiment on MNIST, CIFAR10 and ImageNet data and show our method robust on state-of-the-art attack methods.
Unbalanced GANs: Pre-training the Generator of Generative Adversarial Network using Variational Autoencoder
Feb 06, 2020
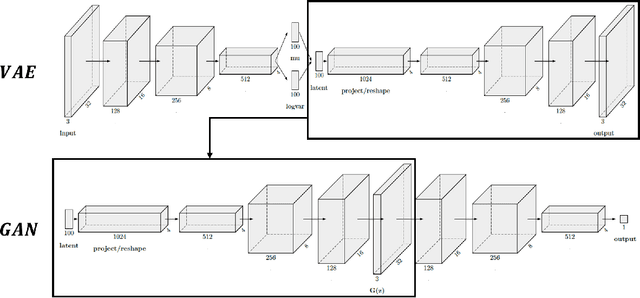


We propose Unbalanced GANs, which pre-trains the generator of the generative adversarial network (GAN) using variational autoencoder (VAE). We guarantee the stable training of the generator by preventing the faster convergence of the discriminator at early epochs. Furthermore, we balance between the generator and the discriminator at early epochs and thus maintain the stabilized training of GANs. We apply Unbalanced GANs to well known public datasets and find that Unbalanced GANs reduce mode collapses. We also show that Unbalanced GANs outperform ordinary GANs in terms of stabilized learning, faster convergence and better image quality at early epochs.
Dissecting Catastrophic Forgetting in Continual Learning by Deep Visualization
Jan 07, 2020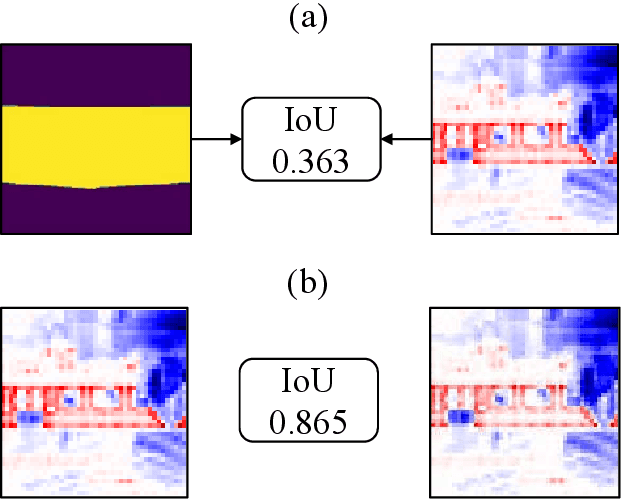

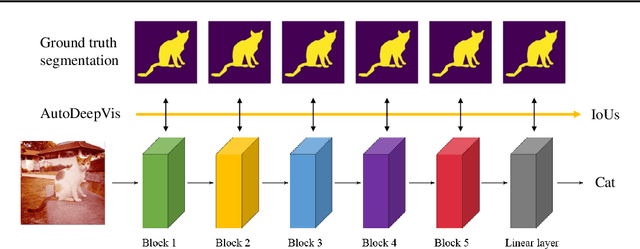
Interpreting the behaviors of Deep Neural Networks (usually considered as a black box) is critical especially when they are now being widely adopted over diverse aspects of human life. Taking the advancements from Explainable Artificial Intelligent, this paper proposes a novel technique called Auto DeepVis to dissect catastrophic forgetting in continual learning. A new method to deal with catastrophic forgetting named critical freezing is also introduced upon investigating the dilemma by Auto DeepVis. Experiments on a captioning model meticulously present how catastrophic forgetting happens, particularly showing which components are forgetting or changing. The effectiveness of our technique is then assessed; and more precisely, critical freezing claims the best performance on both previous and coming tasks over baselines, proving the capability of the investigation. Our techniques could not only be supplementary to existing solutions for completely eradicating catastrophic forgetting for life-long learning but also explainable.