 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Response Preference Optimization with Augmented Ranking Dataset
Paper and Code

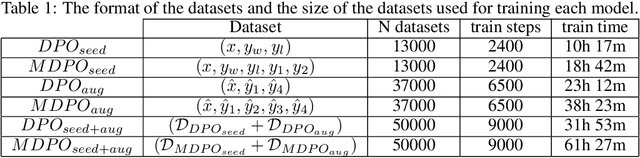
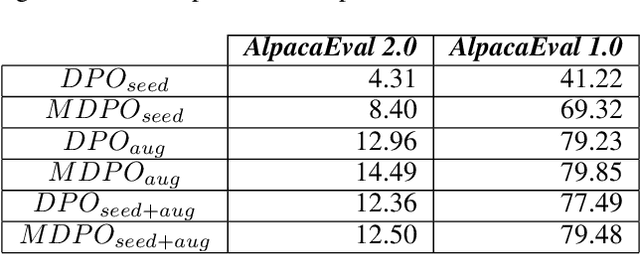

Recent advancements in Large Language Models (LLMs) have been remarkable, with new models consistently surpassing their predecessors. These advancements are underpinned by extensive research on various training mechanisms. Among these, Preference Optimization has played a significant role in improving the performance of LLMs by incorporating human preferences into the training process. However, constructing preference optimization datasets is challenging and the optimization process is highly sensitive to the dataset quality. In this study, we propose a novel approach to augment Preference Optimization datasets. Additionally, we introduce a Multi-response-based Preference Optimization training method that enables the simultaneous learning of multiple responses.