 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpiralThinker: Latent Reasoning through an Iterative Process with Text-Latent Interleaving
Nov 12, 2025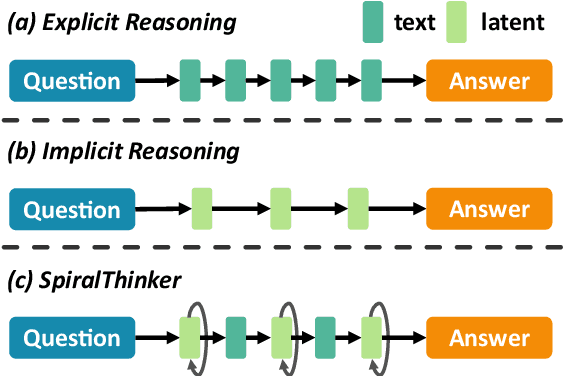
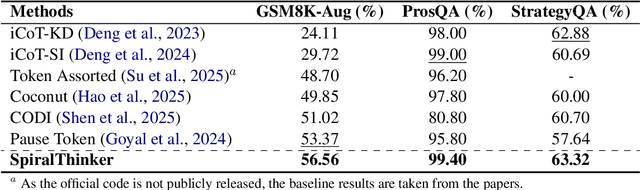
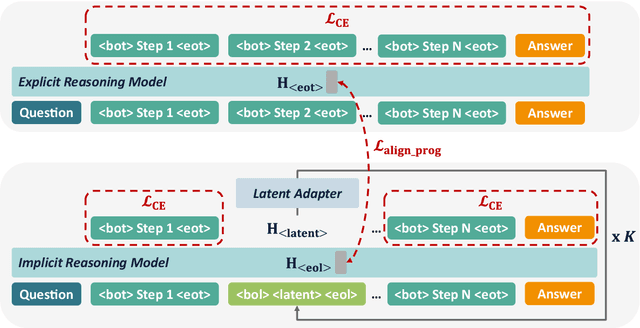

Recent advances in large reasoning models have been driven by reinforcement learning and test-time scaling, accompanied by growing interest in latent rather than purely textual reasoning. However, existing latent reasoning methods lack mechanisms to ensure stable evolution of latent representations and a systematic way to interleave implicit and explicit reasoning. We introduce SpiralThinker, a unified framework that performs iterative updates over latent representations, enabling extended implicit reasoning without generating additional tokens. A progressive alignment objective combined with structured annotations maintains coherence between latent and textual reasoning. Across mathematical, logical, and commonsense reasoning tasks, SpiralThinker achieves the best overall performance among latent reasoning approaches, consistently surpassing previous methods across all benchmarks. Detailed analyses reveal that both iteration and alignment are indispensable, the numbers of latent tokens and iterations exhibit dataset-specific optima, and appropriate alignment proves critical for an effective iterative process. Overall, SpiralThinker bridges iterative computation and latent reasoning, demonstrating that aligned iterative updates can reliably steer reasoning in the latent space.
Relation-Aware Bayesian Optimization of DBMS Configurations Guided by Affinity Scores
Oct 31, 2025Database Management Systems (DBMSs) are fundamental for managing large-scale and heterogeneous data, and their performance is critically influenced by configuration parameters. Effective tuning of these parameters is essential for adapting to diverse workloads and maximizing throughput while minimizing latency. Recent research has focused on automated configuration optimization using machine learning; however, existing approaches still exhibit several key limitations. Most tuning frameworks disregard the dependencies among parameters, assuming that each operates independently. This simplification prevents optimizers from leveraging relational effects across parameters, limiting their capacity to capture performancesensitive interactions. Moreover, to reduce the complexity of the high-dimensional search space, prior work often selects only the top few parameters for optimization, overlooking others that contribute meaningfully to performance. Bayesian Optimization (BO), the most common method for automatic tuning, is also constrained by its reliance on surrogate models, which can lead to unstable predictions and inefficient exploration. To overcome these limitations, we propose RelTune, a novel framework that represents parameter dependencies as a Relational Graph and learns GNN-based latent embeddings that encode performancerelevant semantics. RelTune further introduces Hybrid-Score-Guided Bayesian Optimization (HBO), which combines surrogate predictions with an Affinity Score measuring proximity to previously high-performing configurations. Experimental results on multiple DBMSs and workloads demonstrate that RelTune achieves faster convergence and higher optimization efficiency than conventional BO-based methods, achieving state-of-the-art performance across all evaluated scenarios.
Real-Time Sleepiness Detection for Driver State Monitoring System
Apr 21, 2025A driver face monitoring system can detect driver fatigue, which is a significant factor in many accidents, using computer vision techniques. In this paper, we present a real-time technique for driver eye state detection. First, the face is detected, and the eyes are located within the face region for tracking. A normalized cross-correlation-based online dynamic template matching technique, combined with Kalman filter tracking, is proposed to track the detected eye positions in subsequent image frames. A support vector machine with histogram of oriented gradients (HOG) features is used to classify the state of the eyes as open or closed. If the eyes remain closed for a specified period, the driver is considered to be asleep, and an alarm is triggered.
* 8 pages, published in GST 2015
AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM
Mar 06, 2025



Video anomaly detection (VAD) is crucial for video analysis and surveillance in computer vision. However, existing VAD models rely on learned normal patterns, which makes them difficult to apply to diverse environments. Consequently, users should retrain models or develop separate AI models for new environments, which requires expertise in machine learning, high-performance hardware, and extensive data collection, limiting the practical usability of VAD. To address these challenges, this study proposes customizable video anomaly detection (C-VAD) technique and the AnyAnomaly model. C-VAD considers user-defined text as an abnormal event and detects frames containing a specified event in a video. We effectively implemented AnyAnomaly using a context-aware visual question answering without fine-tuning the large vision language model. To validate the effectiveness of the proposed model, we constructed C-VAD datasets and demonstrated the superiority of AnyAnomaly. Furthermore, our approach showed competitive performance on VAD benchmark datasets, achieving state-of-the-art results on the UBnormal dataset and outperforming other methods in generalization across all datasets. Our code is available online at github.com/SkiddieAhn/Paper-AnyAnomaly.
Style Extraction on Text Embeddings Using VAE and Parallel Dataset
Feb 12, 2025This study investigates the stylistic differences among various Bible translations using a Variational Autoencoder (VAE) model. By embedding textual data into high-dimensional vectors, the study aims to detect and analyze stylistic variations between translations, with a specific focus on distinguishing the American Standard Version (ASV) from other translations. The results demonstrate that each translation exhibits a unique stylistic distribution, which can be effectively identified using the VAE model. These findings suggest that the VAE model is proficient in capturing and differentiating textual styles, although it is primarily optimized for distinguishing a single style. The study highlights the model's potential for broader applications in AI-based text generation and stylistic analysis, while also acknowledging the need for further model refinement to address the complexity of multi-dimensional stylistic relationships. Future research could extend this methodology to other text domains, offering deeper insights into the stylistic features embedded within various types of textual data.
Thinking with Many Minds: Using Large Language Models for Multi-Perspective Problem-Solving
Jan 04, 2025Complex problem-solving requires cognitive flexibility--the capacity to entertain multiple perspectives while preserving their distinctiveness. This flexibility replicates the "wisdom of crowds" within a single individual, allowing them to "think with many minds." While mental simulation enables imagined deliberation, cognitive constraints limit its effectiveness. We propose synthetic deliberation, a Large Language Model (LLM)-based method that simulates discourse between agents embodying diverse perspectives, as a solution. Using a custom GPT-based model, we showcase its benefits: concurrent processing of multiple viewpoints without cognitive degradation, parallel exploration of perspectives, and precise control over viewpoint synthesis. By externalizing the deliberative process and distributing cognitive labor between parallel search and integration, synthetic deliberation transcends mental simulation's limitations. This approach shows promise for strategic planning, policymaking, and conflict resolution.
Advanced Knowledge Transfer: Refined Feature Distillation for Zero-Shot Quantization in Edge Computing
Dec 26, 2024



We introduce AKT (Advanced Knowledge Transfer), a novel method to enhance the training ability of low-bit quantized (Q) models in the field of zero-shot quantization (ZSQ). Existing research in ZSQ has focused on generating high-quality data from full-precision (FP) models. However, these approaches struggle with reduced learning ability in low-bit quantization due to its limited information capacity. To overcome this limitation, we propose effective training strategy compared to data generation. Particularly, we analyzed that refining feature maps in the feature distillation process is an effective way to transfer knowledge to the Q model. Based on this analysis, AKT efficiently transfer core information from the FP model to the Q model. AKT is the first approach to utilize both spatial and channel attention information in feature distillation in ZSQ. Our method addresses the fundamental gradient exploding problem in low-bit Q models. Experiments on CIFAR-10 and CIFAR-100 datasets demonstrated the effectiveness of the AKT. Our method led to significant performance enhancement in existing generative models. Notably, AKT achieved significant accuracy improvements in low-bit Q models, achieving state-of-the-art in the 3,5bit scenarios on CIFAR-10. The code is available at https://github.com/Inpyo-Hong/AKT-Advanced-knowledge-Transfer.
Mitigating Adversarial Attacks in LLMs through Defensive Suffix Generation
Dec 18, 2024Large language models (LLMs) have exhibited outstanding performance in natural language processing tasks. However, these models remain susceptible to adversarial attacks in which slight input perturbations can lead to harmful or misleading outputs. A gradient-based defensive suffix generation algorithm is designed to bolster the robustness of LLMs. By appending carefully optimized defensive suffixes to input prompts, the algorithm mitigates adversarial influences while preserving the models' utility. To enhance adversarial understanding, a novel total loss function ($L_{\text{total}}$) combining defensive loss ($L_{\text{def}}$) and adversarial loss ($L_{\text{adv}}$) generates defensive suffixes more effectively. Experimental evaluations conducted on open-source LLMs such as Gemma-7B, mistral-7B, Llama2-7B, and Llama2-13B show that the proposed method reduces attack success rates (ASR) by an average of 11\% compared to models without defensive suffixes. Additionally, the perplexity score of Gemma-7B decreased from 6.57 to 3.93 when applying the defensive suffix generated by openELM-270M. Furthermore, TruthfulQA evaluations demonstrate consistent improvements with Truthfulness scores increasing by up to 10\% across tested configurations. This approach significantly enhances the security of LLMs in critical applications without requiring extensive retraining.
TinyThinker: Distilling Reasoning through Coarse-to-Fine Knowledge Internalization with Self-Reflection
Dec 11, 2024Large Language Models exhibit impressive reasoning capabilities across diverse tasks, motivating efforts to distill these capabilities into smaller models through generated reasoning data. However, direct training on such synthesized reasoning data may lead to superficial imitation of reasoning process, rather than fostering a genuine integration of reasoning capabilities with underlying knowledge. To address this, we propose TinyThinker, a framework introducing two novel approaches. First, we introduce a three-stage process that incrementally guides the student model through the reasoning process, progressively refining knowledge from coarse to fine granularity. Second, we develop a two-phase training framework comprising an initial reasoning acquisition phase followed by a self-reflection phase utilizing self-generated data. Experiments on commonsense reasoning benchmarks demonstrate that TinyThinker achieves superior performance compared to baselines. Ablation studies further validate the effectiveness of each component in our framework. TinyThinker is extendable to other knowledge-intensive reasoning tasks, offering an alternative strategy for developing effective reasoning capabilities in smaller language models. Codes are available at https://github.com/shengminp/TinyThinker
Multi-Response Preference Optimization with Augmented Ranking Dataset
Dec 10, 2024
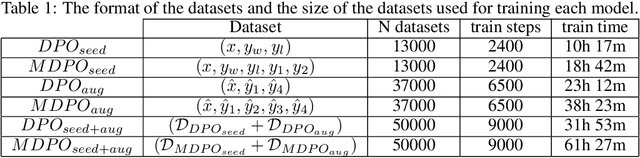
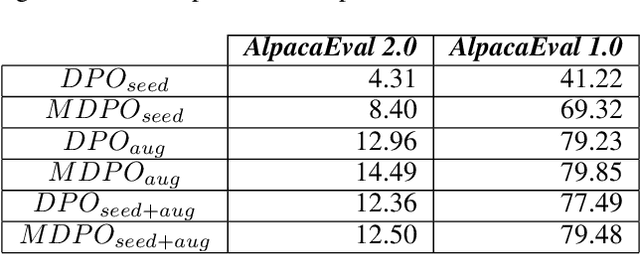

Recent advancements in Large Language Models (LLMs) have been remarkable, with new models consistently surpassing their predecessors. These advancements are underpinned by extensive research on various training mechanisms. Among these, Preference Optimization has played a significant role in improving the performance of LLMs by incorporating human preferences into the training process. However, constructing preference optimization datasets is challenging and the optimization process is highly sensitive to the dataset quality. In this study, we propose a novel approach to augment Preference Optimization datasets. Additionally, we introduce a Multi-response-based Preference Optimization training method that enables the simultaneous learning of multiple responses.