 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM
Mar 06, 2025



Video anomaly detection (VAD) is crucial for video analysis and surveillance in computer vision. However, existing VAD models rely on learned normal patterns, which makes them difficult to apply to diverse environments. Consequently, users should retrain models or develop separate AI models for new environments, which requires expertise in machine learning, high-performance hardware, and extensive data collection, limiting the practical usability of VAD. To address these challenges, this study proposes customizable video anomaly detection (C-VAD) technique and the AnyAnomaly model. C-VAD considers user-defined text as an abnormal event and detects frames containing a specified event in a video. We effectively implemented AnyAnomaly using a context-aware visual question answering without fine-tuning the large vision language model. To validate the effectiveness of the proposed model, we constructed C-VAD datasets and demonstrated the superiority of AnyAnomaly. Furthermore, our approach showed competitive performance on VAD benchmark datasets, achieving state-of-the-art results on the UBnormal dataset and outperforming other methods in generalization across all datasets. Our code is available online at github.com/SkiddieAhn/Paper-AnyAnomaly.
VideoPatchCore: An Effective Method to Memorize Normality for Video Anomaly Detection
Sep 26, 2024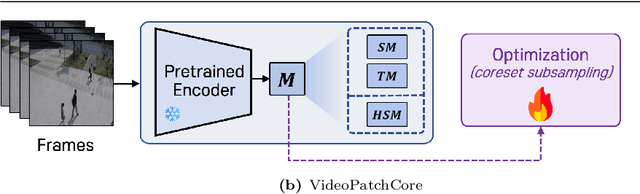
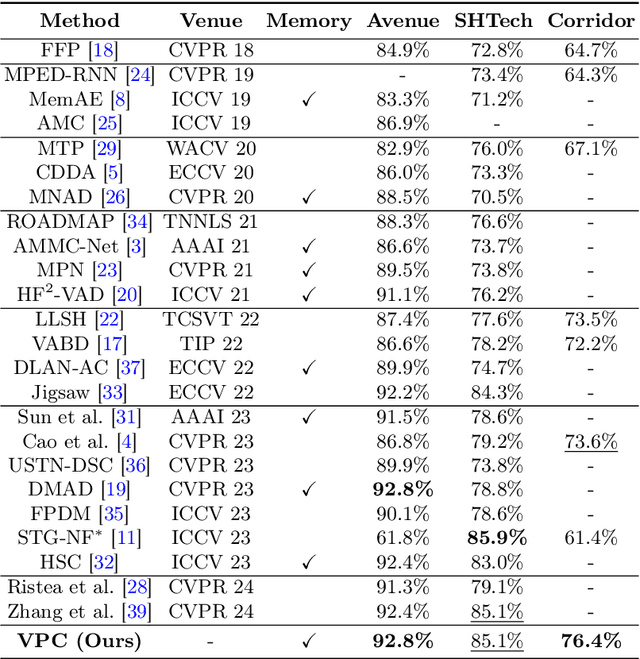
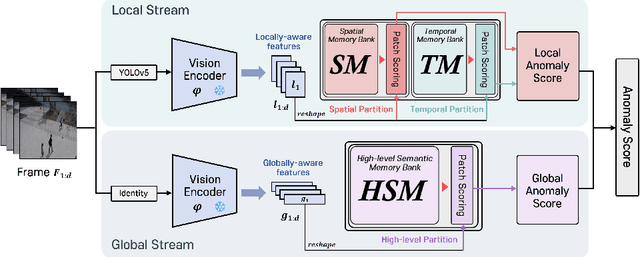

Video anomaly detection (VAD) is a crucial task in video analysis and surveillance within computer vision. Currently, VAD is gaining attention with memory techniques that store the features of normal frames. The stored features are utilized for frame reconstruction, identifying an abnormality when a significant difference exists between the reconstructed and input frames. However, this approach faces several challenges due to the simultaneous optimization required for both the memory and encoder-decoder model. These challenges include increased optimization difficulty, complexity of implementation, and performance variability depending on the memory size. To address these challenges,we propose an effective memory method for VAD, called VideoPatchCore. Inspired by PatchCore, our approach introduces a structure that prioritizes memory optimization and configures three types of memory tailored to the characteristics of video data. This method effectively addresses the limitations of existing memory-based methods, achieving good performance comparable to state-of-the-art methods. Furthermore, our method requires no training and is straightforward to implement, making VAD tasks more accessible. Our code is available online at github.com/SkiddieAhn/Paper-VideoPatchCore.