 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation-Aware Bayesian Optimization of DBMS Configurations Guided by Affinity Scores
Oct 31, 2025Database Management Systems (DBMSs) are fundamental for managing large-scale and heterogeneous data, and their performance is critically influenced by configuration parameters. Effective tuning of these parameters is essential for adapting to diverse workloads and maximizing throughput while minimizing latency. Recent research has focused on automated configuration optimization using machine learning; however, existing approaches still exhibit several key limitations. Most tuning frameworks disregard the dependencies among parameters, assuming that each operates independently. This simplification prevents optimizers from leveraging relational effects across parameters, limiting their capacity to capture performancesensitive interactions. Moreover, to reduce the complexity of the high-dimensional search space, prior work often selects only the top few parameters for optimization, overlooking others that contribute meaningfully to performance. Bayesian Optimization (BO), the most common method for automatic tuning, is also constrained by its reliance on surrogate models, which can lead to unstable predictions and inefficient exploration. To overcome these limitations, we propose RelTune, a novel framework that represents parameter dependencies as a Relational Graph and learns GNN-based latent embeddings that encode performancerelevant semantics. RelTune further introduces Hybrid-Score-Guided Bayesian Optimization (HBO), which combines surrogate predictions with an Affinity Score measuring proximity to previously high-performing configurations. Experimental results on multiple DBMSs and workloads demonstrate that RelTune achieves faster convergence and higher optimization efficiency than conventional BO-based methods, achieving state-of-the-art performance across all evaluated scenarios.
AnyAnomaly: Zero-Shot Customizable Video Anomaly Detection with LVLM
Mar 06, 2025



Video anomaly detection (VAD) is crucial for video analysis and surveillance in computer vision. However, existing VAD models rely on learned normal patterns, which makes them difficult to apply to diverse environments. Consequently, users should retrain models or develop separate AI models for new environments, which requires expertise in machine learning, high-performance hardware, and extensive data collection, limiting the practical usability of VAD. To address these challenges, this study proposes customizable video anomaly detection (C-VAD) technique and the AnyAnomaly model. C-VAD considers user-defined text as an abnormal event and detects frames containing a specified event in a video. We effectively implemented AnyAnomaly using a context-aware visual question answering without fine-tuning the large vision language model. To validate the effectiveness of the proposed model, we constructed C-VAD datasets and demonstrated the superiority of AnyAnomaly. Furthermore, our approach showed competitive performance on VAD benchmark datasets, achieving state-of-the-art results on the UBnormal dataset and outperforming other methods in generalization across all datasets. Our code is available online at github.com/SkiddieAhn/Paper-AnyAnomaly.
Advanced Knowledge Transfer: Refined Feature Distillation for Zero-Shot Quantization in Edge Computing
Dec 26, 2024



We introduce AKT (Advanced Knowledge Transfer), a novel method to enhance the training ability of low-bit quantized (Q) models in the field of zero-shot quantization (ZSQ). Existing research in ZSQ has focused on generating high-quality data from full-precision (FP) models. However, these approaches struggle with reduced learning ability in low-bit quantization due to its limited information capacity. To overcome this limitation, we propose effective training strategy compared to data generation. Particularly, we analyzed that refining feature maps in the feature distillation process is an effective way to transfer knowledge to the Q model. Based on this analysis, AKT efficiently transfer core information from the FP model to the Q model. AKT is the first approach to utilize both spatial and channel attention information in feature distillation in ZSQ. Our method addresses the fundamental gradient exploding problem in low-bit Q models. Experiments on CIFAR-10 and CIFAR-100 datasets demonstrated the effectiveness of the AKT. Our method led to significant performance enhancement in existing generative models. Notably, AKT achieved significant accuracy improvements in low-bit Q models, achieving state-of-the-art in the 3,5bit scenarios on CIFAR-10. The code is available at https://github.com/Inpyo-Hong/AKT-Advanced-knowledge-Transfer.
MRNet: Multifaceted Resilient Networks for Medical Image-to-Image Translation
Dec 04, 2024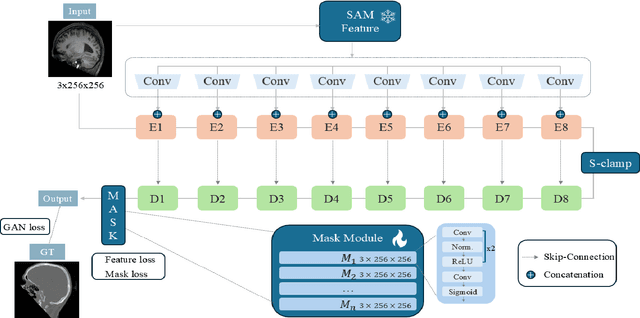
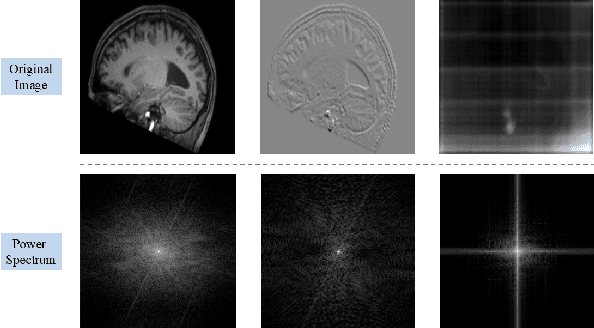
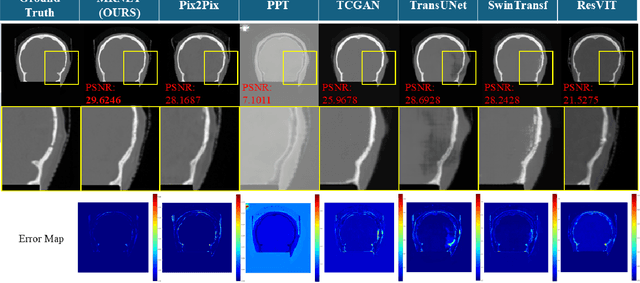
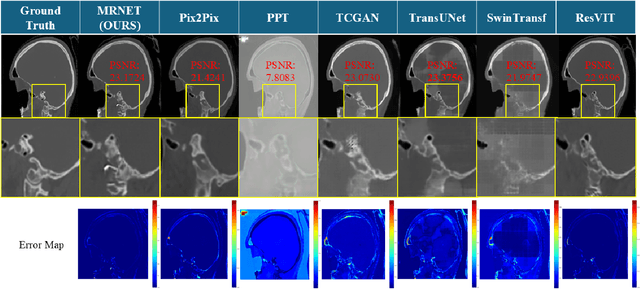
We propose a Multifaceted Resilient Network(MRNet), a novel architecture developed for medical image-to-image translation that outperforms state-of-the-art methods in MRI-to-CT and MRI-to-MRI conversion. MRNet leverages the Segment Anything Model (SAM) to exploit frequency-based features to build a powerful method for advanced medical image transformation. The architecture extracts comprehensive multiscale features from diverse datasets using a powerful SAM image encoder and performs resolution-aware feature fusion that consistently integrates U-Net encoder outputs with SAM-derived features. This fusion optimizes the traditional U-Net skip connection while leveraging transformer-based contextual analysis. The translation is complemented by an innovative dual-mask configuration incorporating dynamic attention patterns and a specialized loss function designed to address regional mapping mismatches, preserving both the gross anatomy and tissue details. Extensive validation studies have shown that MRNet outperforms state-of-the-art architectures, particularly in maintaining anatomical fidelity and minimizing translation artifacts.
VideoPatchCore: An Effective Method to Memorize Normality for Video Anomaly Detection
Sep 26, 2024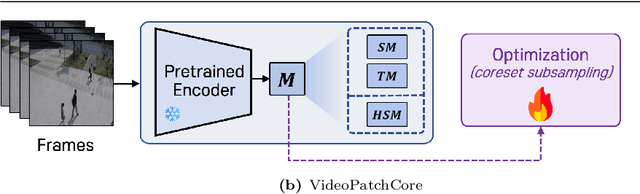
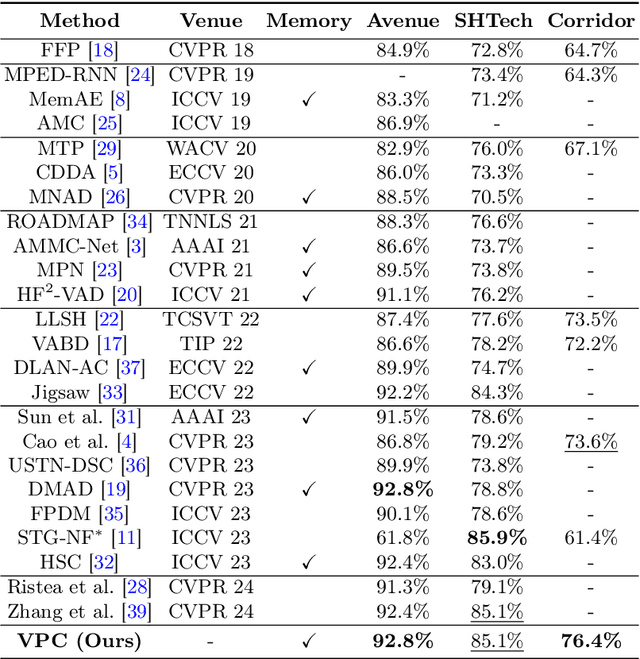
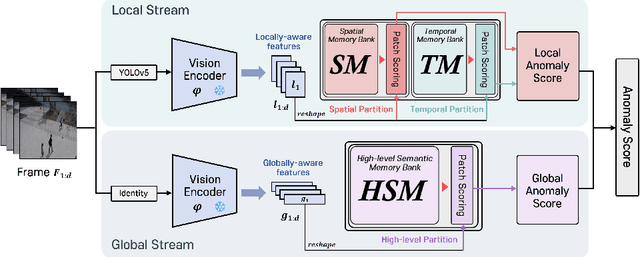

Video anomaly detection (VAD) is a crucial task in video analysis and surveillance within computer vision. Currently, VAD is gaining attention with memory techniques that store the features of normal frames. The stored features are utilized for frame reconstruction, identifying an abnormality when a significant difference exists between the reconstructed and input frames. However, this approach faces several challenges due to the simultaneous optimization required for both the memory and encoder-decoder model. These challenges include increased optimization difficulty, complexity of implementation, and performance variability depending on the memory size. To address these challenges,we propose an effective memory method for VAD, called VideoPatchCore. Inspired by PatchCore, our approach introduces a structure that prioritizes memory optimization and configures three types of memory tailored to the characteristics of video data. This method effectively addresses the limitations of existing memory-based methods, achieving good performance comparable to state-of-the-art methods. Furthermore, our method requires no training and is straightforward to implement, making VAD tasks more accessible. Our code is available online at github.com/SkiddieAhn/Paper-VideoPatchCore.