 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token Reduction for Diffusion Models via Output-Similarity-Awareness
May 21, 2026Diffusion Transformers (DiTs) achieve superior image generation quality but suffer from quadratic computational complexity relative to token count. While various token reduction (TR) methods have been proposed to mitigate this cost, they overlook the primary objective of generative models: minimizing recovery error, which requires reflecting output token similarity. They rely solely on input token similarity inherited from reduction-only ViT paradigms, leading to a fundamental misalignment with this objective. To bridge this gap, we propose DiTo, a novel TR paradigm that shifts the focus toward output-centric token reduction. Based on the observation that output token similarity is consistently preserved across adjacent timesteps, DiTo utilizes prior-step similarities as an effective proxy to establish token correspondences at a Matching timestep, which are then reused across multiple subsequent Reduction timesteps. To optimize this interleaved scheduling, we propose Pair Match Ratio (PMR)-guided Interval Scheduling to determine the optimal matching frequency. Furthermore, to mitigate localized approximation errors and resulting blocking artifacts caused by repeated reuse, we propose Frequency-aware Token Matching by incorporating a selection-frequency penalty. Extensive experiments demonstrate that DiTo consistently outperforms existing TR methods with 1.6-3.9 dB higher PSNR at comparable speedups, achieving a superior Pareto frontier.
Advanced Knowledge Transfer: Refined Feature Distillation for Zero-Shot Quantization in Edge Computing
Dec 26, 2024



We introduce AKT (Advanced Knowledge Transfer), a novel method to enhance the training ability of low-bit quantized (Q) models in the field of zero-shot quantization (ZSQ). Existing research in ZSQ has focused on generating high-quality data from full-precision (FP) models. However, these approaches struggle with reduced learning ability in low-bit quantization due to its limited information capacity. To overcome this limitation, we propose effective training strategy compared to data generation. Particularly, we analyzed that refining feature maps in the feature distillation process is an effective way to transfer knowledge to the Q model. Based on this analysis, AKT efficiently transfer core information from the FP model to the Q model. AKT is the first approach to utilize both spatial and channel attention information in feature distillation in ZSQ. Our method addresses the fundamental gradient exploding problem in low-bit Q models. Experiments on CIFAR-10 and CIFAR-100 datasets demonstrated the effectiveness of the AKT. Our method led to significant performance enhancement in existing generative models. Notably, AKT achieved significant accuracy improvements in low-bit Q models, achieving state-of-the-art in the 3,5bit scenarios on CIFAR-10. The code is available at https://github.com/Inpyo-Hong/AKT-Advanced-knowledge-Transfer.
MRNet: Multifaceted Resilient Networks for Medical Image-to-Image Translation
Dec 04, 2024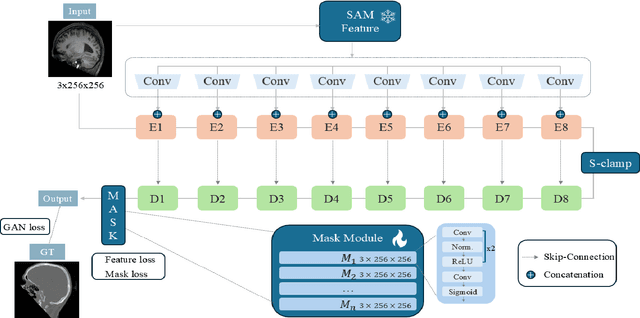
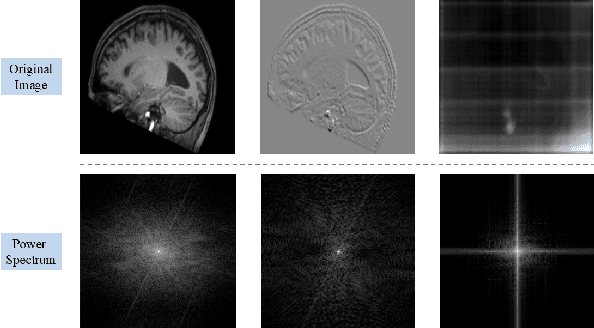
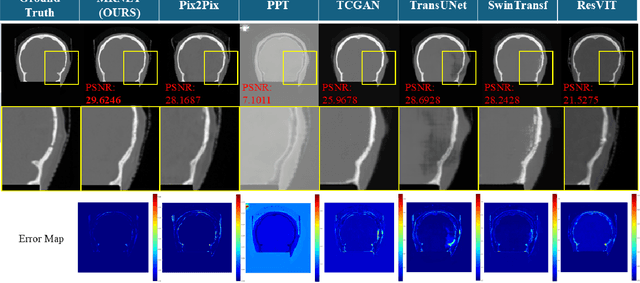
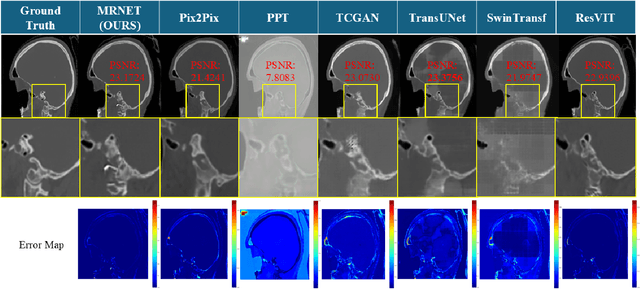
We propose a Multifaceted Resilient Network(MRNet), a novel architecture developed for medical image-to-image translation that outperforms state-of-the-art methods in MRI-to-CT and MRI-to-MRI conversion. MRNet leverages the Segment Anything Model (SAM) to exploit frequency-based features to build a powerful method for advanced medical image transformation. The architecture extracts comprehensive multiscale features from diverse datasets using a powerful SAM image encoder and performs resolution-aware feature fusion that consistently integrates U-Net encoder outputs with SAM-derived features. This fusion optimizes the traditional U-Net skip connection while leveraging transformer-based contextual analysis. The translation is complemented by an innovative dual-mask configuration incorporating dynamic attention patterns and a specialized loss function designed to address regional mapping mismatches, preserving both the gross anatomy and tissue details. Extensive validation studies have shown that MRNet outperforms state-of-the-art architectures, particularly in maintaining anatomical fidelity and minimizing translation artifacts.