 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Response Preference Optimization with Augmented Ranking Dataset
Dec 10, 2024
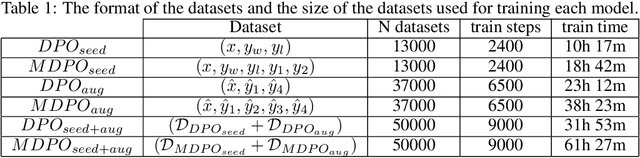
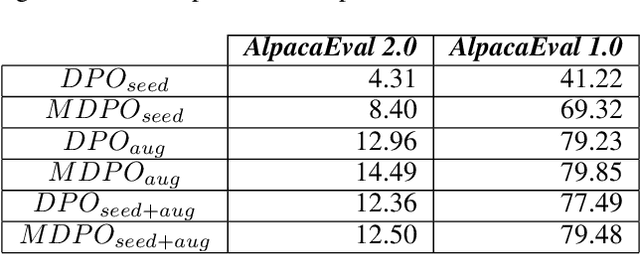

Recent advancements in Large Language Models (LLMs) have been remarkable, with new models consistently surpassing their predecessors. These advancements are underpinned by extensive research on various training mechanisms. Among these, Preference Optimization has played a significant role in improving the performance of LLMs by incorporating human preferences into the training process. However, constructing preference optimization datasets is challenging and the optimization process is highly sensitive to the dataset quality. In this study, we propose a novel approach to augment Preference Optimization datasets. Additionally, we introduce a Multi-response-based Preference Optimization training method that enables the simultaneous learning of multiple responses.
InMD-X: Large Language Models for Internal Medicine Doctors
Feb 20, 2024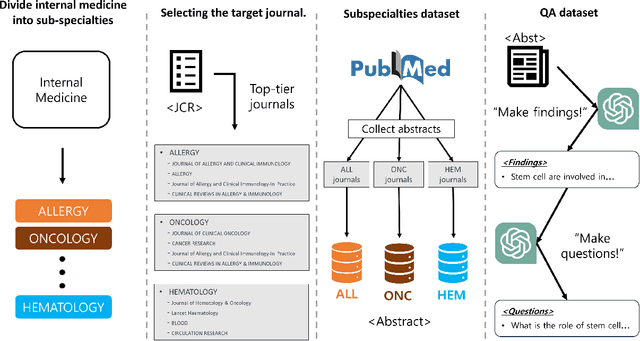
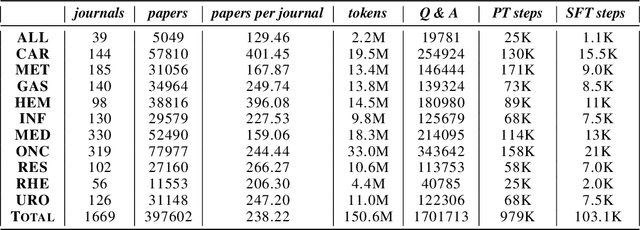
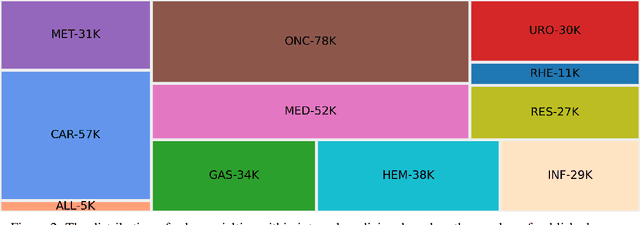

In this paper, we introduce InMD-X, a collection of multiple large language models specifically designed to cater to the unique characteristics and demands of Internal Medicine Doctors (IMD). InMD-X represents a groundbreaking development in natural language processing, offering a suite of language models fine-tuned for various aspects of the internal medicine field. These models encompass a wide range of medical sub-specialties, enabling IMDs to perform more efficient and accurate research, diagnosis, and documentation. InMD-X's versatility and adaptability make it a valuable tool for improving the healthcare industry, enhancing communication between healthcare professionals, and advancing medical research. Each model within InMD-X is meticulously tailored to address specific challenges faced by IMDs, ensuring the highest level of precision and comprehensiveness in clinical text analysis and decision support. This paper provides an overview of the design, development, and evaluation of InMD-X, showcasing its potential to revolutionize the way internal medicine practitioners interact with medical data and information. We present results from extensive testing, demonstrating the effectiveness and practical utility of InMD-X in real-world medical scenarios.
NOTE: Notable generation Of patient Text summaries through Efficient approach based on direct preference optimization
Feb 19, 2024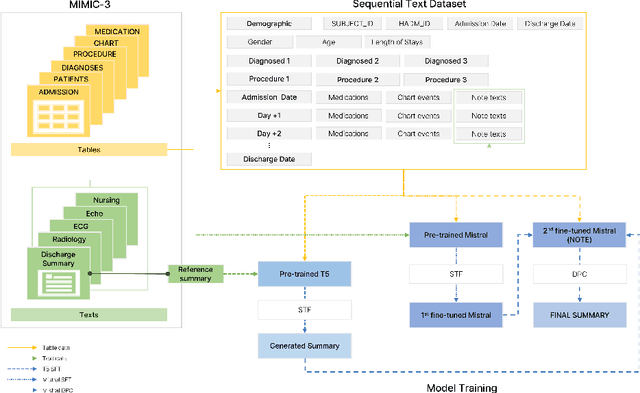
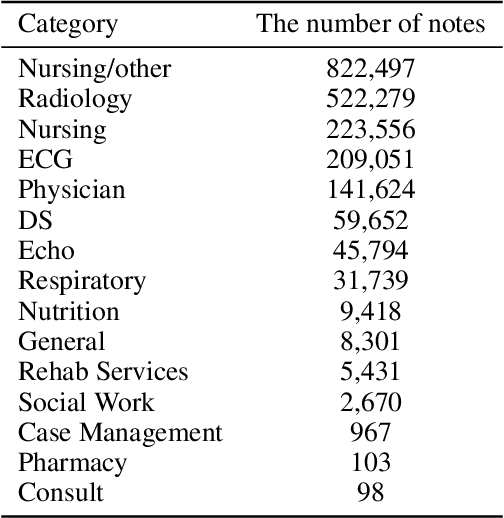
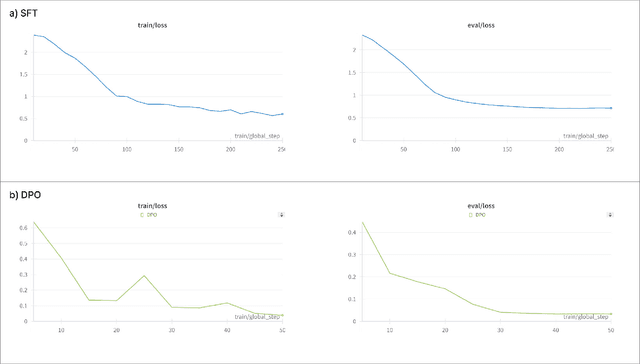

The discharge summary is a one of critical documents in the patient journey, encompassing all events experienced during hospitalization, including multiple visits, medications, tests, surgery/procedures, and admissions/discharge. Providing a summary of the patient's progress is crucial, as it significantly influences future care and planning. Consequently, clinicians face the laborious and resource-intensive task of manually collecting, organizing, and combining all the necessary data for a discharge summary. Therefore, we propose "NOTE", which stands for "Notable generation Of patient Text summaries through an Efficient approach based on direct preference optimization". NOTE is based on Medical Information Mart for Intensive Care- III dataset and summarizes a single hospitalization of a patient. Patient events are sequentially combined and used to generate a discharge summary for each hospitalization. In the present circumstances, large language models' application programming interfaces (LLMs' APIs) are widely available, but importing and exporting medical data presents significant challenges due to privacy protection policies in healthcare institutions. Moreover, to ensure optimal performance, it is essential to implement a lightweight model for internal server or program within the hospital. Therefore, we utilized DPO and parameter efficient fine tuning (PEFT) techniques to apply a fine-tuning method that guarantees superior performance. To demonstrate the practical application of the developed NOTE, we provide a webpage-based demonstration software. In the future, we will aim to deploy the software available for actual use by clinicians in hospital. NOTE can be utilized to generate various summaries not only discharge summaries but also throughout a patient's journey, thereby alleviating the labor-intensive workload of clinicians and aiming for increased efficiency.