 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSUMMPILOT: Bridging Efficiency and Customization for Interactive Summarization System
Jan 13, 2026This paper incorporates the efficiency of automatic summarization and addresses the challenge of generating personalized summaries tailored to individual users' interests and requirements. To tackle this challenge, we introduce SummPilot, an interaction-based customizable summarization system. SummPilot leverages a large language model to facilitate both automatic and interactive summarization. Users can engage with the system to understand document content and personalize summaries through interactive components such as semantic graphs, entity clustering, and explainable evaluation. Our demo and user studies demonstrate SummPilot's adaptability and usefulness for customizable summarization.
EMR-AGENT: Automating Cohort and Feature Extraction from EMR Databases
Oct 02, 2025Machine learning models for clinical prediction rely on structured data extracted from Electronic Medical Records (EMRs), yet this process remains dominated by hardcoded, database-specific pipelines for cohort definition, feature selection, and code mapping. These manual efforts limit scalability, reproducibility, and cross-institutional generalization. To address this, we introduce EMR-AGENT (Automated Generalized Extraction and Navigation Tool), an agent-based framework that replaces manual rule writing with dynamic, language model-driven interaction to extract and standardize structured clinical data. Our framework automates cohort selection, feature extraction, and code mapping through interactive querying of databases. Our modular agents iteratively observe query results and reason over schema and documentation, using SQL not just for data retrieval but also as a tool for database observation and decision making. This eliminates the need for hand-crafted, schema-specific logic. To enable rigorous evaluation, we develop a benchmarking codebase for three EMR databases (MIMIC-III, eICU, SICdb), including both seen and unseen schema settings. Our results demonstrate strong performance and generalization across these databases, highlighting the feasibility of automating a process previously thought to require expert-driven design. The code will be released publicly at https://github.com/AITRICS/EMR-AGENT/tree/main. For a demonstration, please visit our anonymous demo page: https://anonymoususer-max600.github.io/EMR_AGENT/
Beyond Single-User Dialogue: Assessing Multi-User Dialogue State Tracking Capabilities of Large Language Models
Jun 12, 2025Large language models (LLMs) have demonstrated remarkable performance in zero-shot dialogue state tracking (DST), reducing the need for task-specific training. However, conventional DST benchmarks primarily focus on structured user-agent conversations, failing to capture the complexities of real-world multi-user interactions. In this study, we assess the robustness of LLMs in multi-user DST while minimizing dataset construction costs. Inspired by recent advances in LLM-based data annotation, we extend an existing DST dataset by generating utterances of a second user based on speech act theory. Our methodology systematically incorporates a second user's utterances into conversations, enabling a controlled evaluation of LLMs in multi-user settings. Experimental results reveal a significant performance drop compared to single-user DST, highlighting the limitations of current LLMs in extracting and tracking dialogue states amidst multiple speakers. Our findings emphasize the need for future research to enhance LLMs for multi-user DST scenarios, paving the way for more realistic and robust DST models.
Plug-in and Fine-tuning: Bridging the Gap between Small Language Models and Large Language Models
Jun 09, 2025Large language models (LLMs) are renowned for their extensive linguistic knowledge and strong generalization capabilities, but their high computational demands make them unsuitable for resource-constrained environments. In contrast, small language models (SLMs) are computationally efficient but often lack the broad generalization capacity of LLMs. To bridge this gap, we propose PiFi, a novel framework that combines the strengths of both LLMs and SLMs to achieve high performance while maintaining efficiency. PiFi integrates a single frozen layer from an LLM into a SLM and fine-tunes the combined model for specific tasks, boosting performance without a significant increase in computational cost. We show that PiFi delivers consistent performance improvements across a range of natural language processing tasks, including both natural language understanding and generation. Moreover, our findings demonstrate PiFi's ability to effectively leverage LLM knowledge, enhancing generalization to unseen domains and facilitating the transfer of linguistic abilities.
Delving into Multilingual Ethical Bias: The MSQAD with Statistical Hypothesis Tests for Large Language Models
May 25, 2025Despite the recent strides in large language models, studies have underscored the existence of social biases within these systems. In this paper, we delve into the validation and comparison of the ethical biases of LLMs concerning globally discussed and potentially sensitive topics, hypothesizing that these biases may arise from language-specific distinctions. Introducing the Multilingual Sensitive Questions & Answers Dataset (MSQAD), we collected news articles from Human Rights Watch covering 17 topics, and generated socially sensitive questions along with corresponding responses in multiple languages. We scrutinized the biases of these responses across languages and topics, employing two statistical hypothesis tests. The results showed that the null hypotheses were rejected in most cases, indicating biases arising from cross-language differences. It demonstrates that ethical biases in responses are widespread across various languages, and notably, these biases were prevalent even among different LLMs. By making the proposed MSQAD openly available, we aim to facilitate future research endeavors focused on examining cross-language biases in LLMs and their variant models.
Real-Time Sleepiness Detection for Driver State Monitoring System
Apr 21, 2025A driver face monitoring system can detect driver fatigue, which is a significant factor in many accidents, using computer vision techniques. In this paper, we present a real-time technique for driver eye state detection. First, the face is detected, and the eyes are located within the face region for tracking. A normalized cross-correlation-based online dynamic template matching technique, combined with Kalman filter tracking, is proposed to track the detected eye positions in subsequent image frames. A support vector machine with histogram of oriented gradients (HOG) features is used to classify the state of the eyes as open or closed. If the eyes remain closed for a specified period, the driver is considered to be asleep, and an alarm is triggered.
* 8 pages, published in GST 2015
See-Saw Modality Balance: See Gradient, and Sew Impaired Vision-Language Balance to Mitigate Dominant Modality Bias
Mar 18, 2025
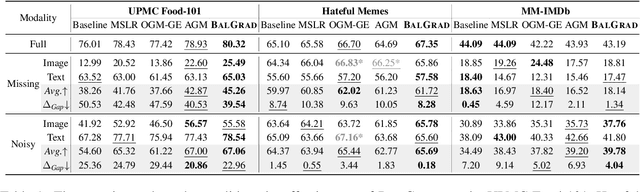
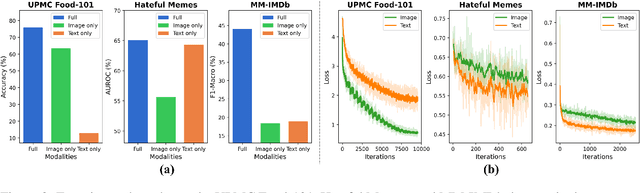
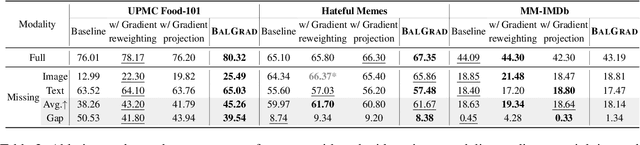
Vision-language (VL) models have demonstrated strong performance across various tasks. However, these models often rely on a specific modality for predictions, leading to "dominant modality bias.'' This bias significantly hurts performance, especially when one modality is impaired. In this study, we analyze model behavior under dominant modality bias and theoretically show that unaligned gradients or differences in gradient magnitudes prevent balanced convergence of the loss. Based on these findings, we propose a novel framework, BalGrad to mitigate dominant modality bias. Our approach includes inter-modality gradient reweighting, adjusting the gradient of KL divergence based on each modality's contribution, and inter-task gradient projection to align task directions in a non-conflicting manner. Experiments on UPMC Food-101, Hateful Memes, and MM-IMDb datasets confirm that BalGrad effectively alleviates over-reliance on specific modalities when making predictions.
Questioning Internal Knowledge Structure of Large Language Models Through the Lens of the Olympic Games
Sep 10, 2024Large language models (LLMs) have become a dominant approach in natural language processing, yet their internal knowledge structures remain largely unexplored. In this paper, we analyze the internal knowledge structures of LLMs using historical medal tallies from the Olympic Games. We task the models with providing the medal counts for each team and identifying which teams achieved specific rankings. Our results reveal that while state-of-the-art LLMs perform remarkably well in reporting medal counts for individual teams, they struggle significantly with questions about specific rankings. This suggests that the internal knowledge structures of LLMs are fundamentally different from those of humans, who can easily infer rankings from known medal counts. To support further research, we publicly release our code, dataset, and model outputs.
VolDoGer: LLM-assisted Datasets for Domain Generalization in Vision-Language Tasks
Jul 29, 2024



Domain generalizability is a crucial aspect of a deep learning model since it determines the capability of the model to perform well on data from unseen domains. However, research on the domain generalizability of deep learning models for vision-language tasks remains limited, primarily because of the lack of required datasets. To address these challenges, we propose VolDoGer: Vision-Language Dataset for Domain Generalization, a dedicated dataset designed for domain generalization that addresses three vision-language tasks: image captioning, visual question answering, and visual entailment. We constructed VolDoGer by extending LLM-based data annotation techniques to vision-language tasks, thereby alleviating the burden of recruiting human annotators. We evaluated the domain generalizability of various models, ranging from fine-tuned models to a recent multimodal large language model, through VolDoGer.
UniGen: Universal Domain Generalization for Sentiment Classification via Zero-shot Dataset Generation
May 02, 2024
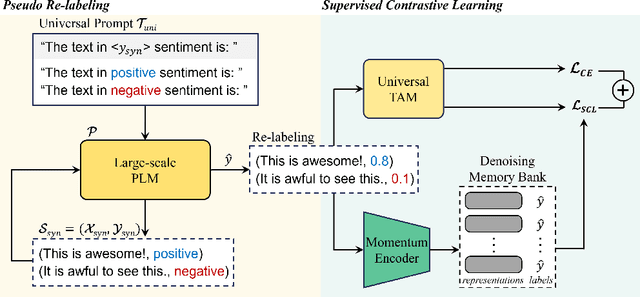
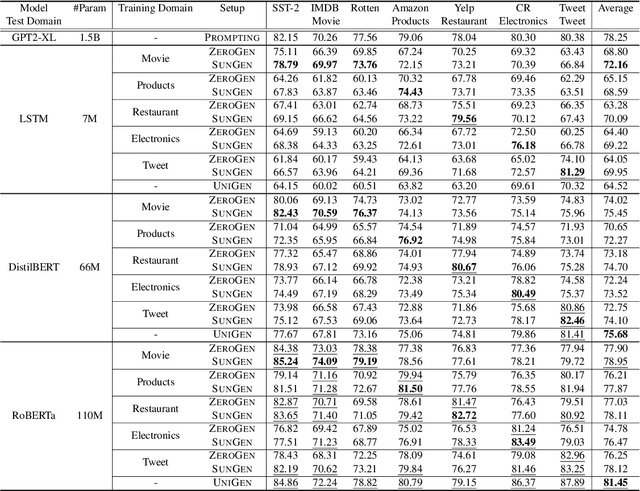
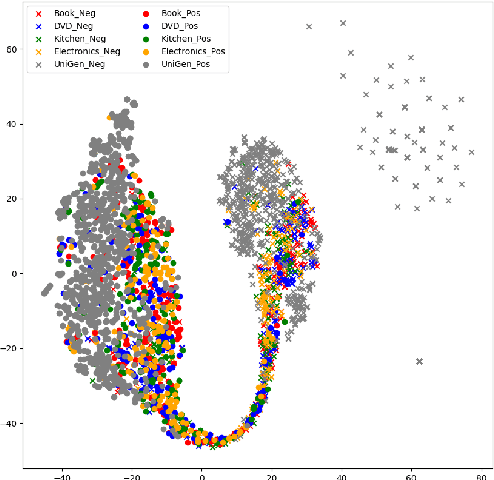
Although pre-trained language models have exhibited great flexibility and versatility with prompt-based few-shot learning, they suffer from the extensive parameter size and limited applicability for inference. Recent studies have suggested that PLMs be used as dataset generators and a tiny task-specific model be trained to achieve efficient inference. However, their applicability to various domains is limited because they tend to generate domain-specific datasets. In this work, we propose a novel approach to universal domain generalization that generates a dataset regardless of the target domain. This allows for generalization of the tiny task model to any domain that shares the label space, thus enhancing the real-world applicability of the dataset generation paradigm. Our experiments indicate that the proposed method accomplishes generalizability across various domains while using a parameter set that is orders of magnitude smaller than PLMs.