 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairQE: Multi-Agent Framework for Mitigating Gender Bias in Translation Quality Estimation
Apr 23, 2026Quality Estimation (QE) aims to assess machine translation quality without reference translations, but recent studies have shown that existing QE models exhibit systematic gender bias. In particular, they tend to favor masculine realizations in gender-ambiguous contexts and may assign higher scores to gender-misaligned translations even when gender is explicitly specified. To address these issues, we propose FairQE, a multi-agent-based, fairness-aware QE framework that mitigates gender bias in both gender-ambiguous and gender-explicit scenarios. FairQE detects gender cues, generates gender-flipped translation variants, and combines conventional QE scores with LLM-based bias-mitigating reasoning through a dynamic bias-aware aggregation mechanism. This design preserves the strengths of existing QE models while calibrating their gender-related biases in a plug-and-play manner. Extensive experiments across multiple gender bias evaluation settings demonstrate that FairQE consistently improves gender fairness over strong QE baselines. Moreover, under MQM-based meta-evaluation following the WMT 2023 Metrics Shared Task, FairQE achieves competitive or improved general QE performance. These results show that gender bias in QE can be effectively mitigated without sacrificing evaluation accuracy, enabling fairer and more reliable translation evaluation.
SUMMPILOT: Bridging Efficiency and Customization for Interactive Summarization System
Jan 13, 2026This paper incorporates the efficiency of automatic summarization and addresses the challenge of generating personalized summaries tailored to individual users' interests and requirements. To tackle this challenge, we introduce SummPilot, an interaction-based customizable summarization system. SummPilot leverages a large language model to facilitate both automatic and interactive summarization. Users can engage with the system to understand document content and personalize summaries through interactive components such as semantic graphs, entity clustering, and explainable evaluation. Our demo and user studies demonstrate SummPilot's adaptability and usefulness for customizable summarization.
LLM Agents at the Roundtable: A Multi-Perspective and Dialectical Reasoning Framework for Essay Scoring
Sep 18, 2025The emergence of large language models (LLMs) has brought a new paradigm to automated essay scoring (AES), a long-standing and practical application of natural language processing in education. However, achieving human-level multi-perspective understanding and judgment remains a challenge. In this work, we propose Roundtable Essay Scoring (RES), a multi-agent evaluation framework designed to perform precise and human-aligned scoring under a zero-shot setting. RES constructs evaluator agents based on LLMs, each tailored to a specific prompt and topic context. Each agent independently generates a trait-based rubric and conducts a multi-perspective evaluation. Then, by simulating a roundtable-style discussion, RES consolidates individual evaluations through a dialectical reasoning process to produce a final holistic score that more closely aligns with human evaluation. By enabling collaboration and consensus among agents with diverse evaluation perspectives, RES outperforms prior zero-shot AES approaches. Experiments on the ASAP dataset using ChatGPT and Claude show that RES achieves up to a 34.86% improvement in average QWK over straightforward prompting (Vanilla) methods.
From Ground Trust to Truth: Disparities in Offensive Language Judgments on Contemporary Korean Political Discourse
Sep 18, 2025Although offensive language continually evolves over time, even recent studies using LLMs have predominantly relied on outdated datasets and rarely evaluated the generalization ability on unseen texts. In this study, we constructed a large-scale dataset of contemporary political discourse and employed three refined judgments in the absence of ground truth. Each judgment reflects a representative offensive language detection method and is carefully designed for optimal conditions. We identified distinct patterns for each judgment and demonstrated tendencies of label agreement using a leave-one-out strategy. By establishing pseudo-labels as ground trust for quantitative performance assessment, we observed that a strategically designed single prompting achieves comparable performance to more resource-intensive methods. This suggests a feasible approach applicable in real-world settings with inherent constraints.
Plug-in and Fine-tuning: Bridging the Gap between Small Language Models and Large Language Models
Jun 09, 2025Large language models (LLMs) are renowned for their extensive linguistic knowledge and strong generalization capabilities, but their high computational demands make them unsuitable for resource-constrained environments. In contrast, small language models (SLMs) are computationally efficient but often lack the broad generalization capacity of LLMs. To bridge this gap, we propose PiFi, a novel framework that combines the strengths of both LLMs and SLMs to achieve high performance while maintaining efficiency. PiFi integrates a single frozen layer from an LLM into a SLM and fine-tunes the combined model for specific tasks, boosting performance without a significant increase in computational cost. We show that PiFi delivers consistent performance improvements across a range of natural language processing tasks, including both natural language understanding and generation. Moreover, our findings demonstrate PiFi's ability to effectively leverage LLM knowledge, enhancing generalization to unseen domains and facilitating the transfer of linguistic abilities.
$χ$-sepnet: Deep neural network for magnetic susceptibility source separation
Sep 24, 2024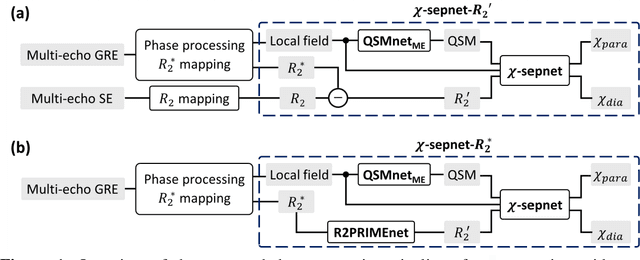
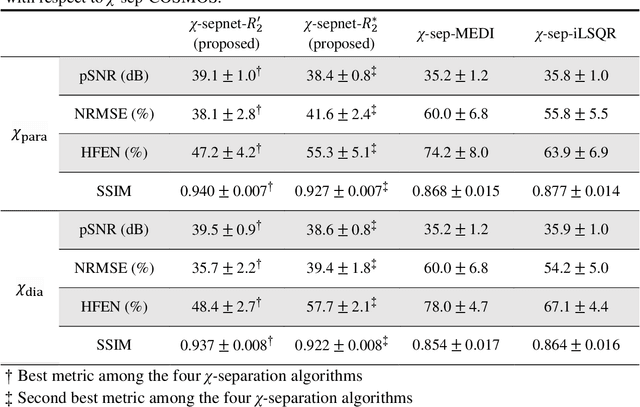
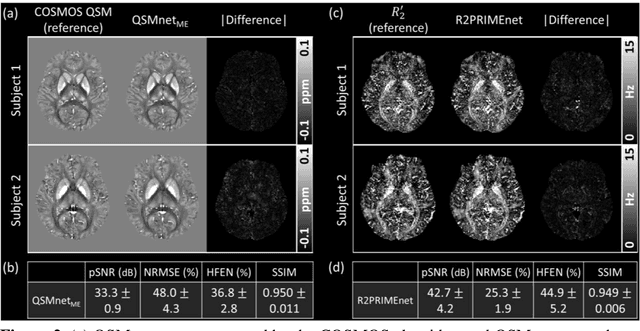
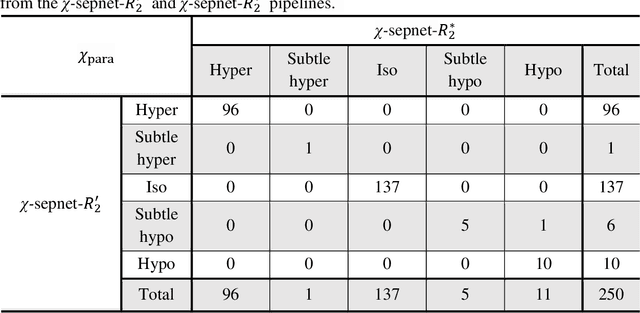
Magnetic susceptibility source separation ($\chi$-separation), an advanced quantitative susceptibility mapping (QSM) method, enables the separate estimation of para- and diamagnetic susceptibility source distributions in the brain. The method utilizes reversible transverse relaxation (R2'=R2*-R2) to complement frequency shift information for estimating susceptibility source concentrations, requiring time-consuming data acquisition for R2 in addition R2*. To address this challenge, we develop a new deep learning network, $\chi$-sepnet, and propose two deep learning-based susceptibility source separation pipelines, $\chi$-sepnet-R2' for inputs with multi-echo GRE and multi-echo spin-echo, and $\chi$-sepnet-R2* for input with multi-echo GRE only. $\chi$-sepnet is trained using multiple head orientation data that provide streaking artifact-free labels, generating high-quality $\chi$-separation maps. The evaluation of the pipelines encompasses both qualitative and quantitative assessments in healthy subjects, and visual inspection of lesion characteristics in multiple sclerosis patients. The susceptibility source-separated maps of the proposed pipelines delineate detailed brain structures with substantially reduced artifacts compared to those from conventional regularization-based reconstruction methods. In quantitative analysis, $\chi$-sepnet-R2' achieves the best outcomes followed by $\chi$-sepnet-R2*, outperforming the conventional methods. When the lesions of multiple sclerosis patients are assessed, both pipelines report identical lesion characteristics in most lesions ($\chi$para: 99.6% and $\chi$dia: 98.4% out of 250 lesions). The $\chi$-sepnet-R2* pipeline, which only requires multi-echo GRE data, has demonstrated its potential to offer broad clinical and scientific applications, although further evaluations for various diseases and pathological conditions are necessary.