 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Text-to-Image Generation by Fine-grained Multimodal Reasoning
Apr 16, 2026With the rapid progress of Multimodal Large Language Models (MLLMs), unified MLLMs that jointly perform image understanding and generation have advanced significantly. However, despite the inherent reasoning capabilities of unified MLLMs for self-reflection and self-refinement, their use in text-to-image generation remains largely underexplored. Meanwhile, existing multimodal reasoning-based image generation methods mostly rely on holistic image-text alignment judgments, without fine-grained reflection and refinement of detailed prompt attributes, leading to limited fine-grained control. Therefore, we propose Fine-grained Multimodal Reasoning (FiMR), a framework that leverages decomposed visual question answering (VQA) to break down an input prompt into minimal semantic units-such as entities and attributes-and verify each unit via VQA to generate explicit, fine-grained feedback. Based on this feedback, FiMR then applies targeted, localized refinements. This fine-grained self-reasoning and self-refinement enable MLLMs to achieve more precise improvements in image-prompt alignment and overall generation quality at test time. Extensive experiments demonstrate that FiMR consistently outperforms image generation baselines, including reasoning-based methods, particularly on compositional text-to-image benchmarks. The code and models are available at https://github.com/KU-AGI/FiMR
CRIT: Graph-Based Automatic Data Synthesis to Enhance Cross-Modal Multi-Hop Reasoning
Apr 02, 2026Real-world reasoning often requires combining information across modalities, connecting textual context with visual cues in a multi-hop process. Yet, most multimodal benchmarks fail to capture this ability: they typically rely on single images or set of images, where answers can be inferred from a single modality alone. This limitation is mirrored in the training data, where interleaved image-text content rarely enforces complementary, multi-hop reasoning. As a result, Vision-Language Models (VLMs) frequently hallucinate and produce reasoning traces poorly grounded in visual evidence. To address this gap, we introduce CRIT, a new dataset and benchmark built with a graph-based automatic pipeline for generating complex cross-modal reasoning tasks. CRIT consists of diverse domains ranging from natural images, videos, and text-rich sources, and includes a manually verified test set for reliable evaluation. Experiments on this benchmark reveal that even state-of-the-art models struggle on such reasoning tasks. Models trained on CRIT show significant gains in cross-modal multi-hop reasoning, including strong improvements on SPIQA and other standard multimodal benchmarks.
HEART-PFL: Stable Personalized Federated Learning under Heterogeneity with Hierarchical Directional Alignment and Adversarial Knowledge Transfer
Mar 25, 2026Personalized Federated Learning (PFL) aims to deliver effective client-specific models under heterogeneous distributions, yet existing methods suffer from shallow prototype alignment and brittle server-side distillation. We propose HEART-PFL, a dual-sided framework that (i) performs depth-aware Hierarchical Directional Alignment (HDA) using cosine similarity in the early stage and MSE matching in the deep stage to preserve client specificity, and (ii) stabilizes global updates through Adversarial Knowledge Transfer (AKT) with symmetric KL distillation on clean and adversarial proxy data. Using lightweight adapters with only 1.46M trainable parameters, HEART-PFL achieves state-of-the-art personalized accuracy on CIFAR-100, Flowers-102, and Caltech-101 (63.42%, 84.23%, and 95.67%, respectively) under Dirichlet non-IID partitions, and remains robust to out-of-domain proxy data. Ablation studies further confirm that HDA and AKT provide complementary gains in alignment, robustness, and optimization stability, offering insights into how the two components mutually reinforce effective personalization. Overall, these results demonstrate that HEART-PFL simultaneously enhances personalization and global stability, highlighting its potential as a strong and scalable solution for PFL(code available at https://github.com/danny0628/HEART-PFL).
Prune-then-Quantize or Quantize-then-Prune? Understanding the Impact of Compression Order in Joint Model Compression
Mar 19, 2026What happens when multiple compression methods are combined-does the order in which they are applied matter? Joint model compression has emerged as a powerful strategy to achieve higher efficiency by combining multiple methods such as pruning and quantization. A central but underexplored factor in joint model compression is the compression order, or the sequence of different methods within the compression pipeline. Most prior studies have either sidestepped the issue by assuming orthogonality between techniques, while a few have examined them only in highly constrained cases. Consequently, the broader role of compression order in shaping model performance remains poorly understood. In this paper, we address the overlooked problem of compression order and provide both theoretical and empirical analysis. We formulate the problem of optimizing the compression order and introduce the Progressive Intensity Hypothesis, which states that weaker perturbations should precede stronger ones. We provide theoretical guarantees showing that the relative benefit of one order increases with the underlying performance gap. Extensive experiments on both language and vision models validate the hypothesis, and further show its generality to broader setups such as multi-stage compression and mixed-precision quantization.
SynQ: Accurate Zero-shot Quantization by Synthesis-aware Fine-tuning
Mar 19, 2026How can we accurately quantize a pre-trained model without any data? Quantization algorithms are widely used for deploying neural networks on resource-constrained edge devices. Zero-shot Quantization (ZSQ) addresses the crucial and practical scenario where training data are inaccessible for privacy or security reasons. However, three significant challenges hinder the performance of existing ZSQ methods: 1) noise in the synthetic dataset, 2) predictions based on off-target patterns, and the 3) misguidance by erroneous hard labels. In this paper, we propose SynQ (Synthesis-aware Fine-tuning for Zero-shot Quantization), a carefully designed ZSQ framework to overcome the limitations of existing methods. SynQ minimizes the noise from the generated samples by exploiting a low-pass filter. Then, SynQ trains the quantized model to improve accuracy by aligning its class activation map with the pre-trained model. Furthermore, SynQ mitigates misguidance from the pre-trained model's error by leveraging only soft labels for difficult samples. Extensive experiments show that SynQ provides the state-of-the-art accuracy, over existing ZSQ methods.
ELO: Efficient Layer-Specific Optimization for Continual Pretraining of Multilingual LLMs
Jan 07, 2026We propose an efficient layer-specific optimization (ELO) method designed to enhance continual pretraining (CP) for specific languages in multilingual large language models (MLLMs). This approach addresses the common challenges of high computational cost and degradation of source language performance associated with traditional CP. The ELO method consists of two main stages: (1) ELO Pretraining, where a small subset of specific layers, identified in our experiments as the critically important first and last layers, are detached from the original MLLM and trained with the target language. This significantly reduces not only the number of trainable parameters but also the total parameters computed during the forward pass, minimizing GPU memory consumption and accelerating the training process. (2) Layer Alignment, where the newly trained layers are reintegrated into the original model, followed by a brief full fine-tuning step on a small dataset to align the parameters. Experimental results demonstrate that the ELO method achieves a training speedup of up to 6.46 times compared to existing methods, while improving target language performance by up to 6.2\% on qualitative benchmarks and effectively preserving source language (English) capabilities.
LampQ: Towards Accurate Layer-wise Mixed Precision Quantization for Vision Transformers
Nov 14, 2025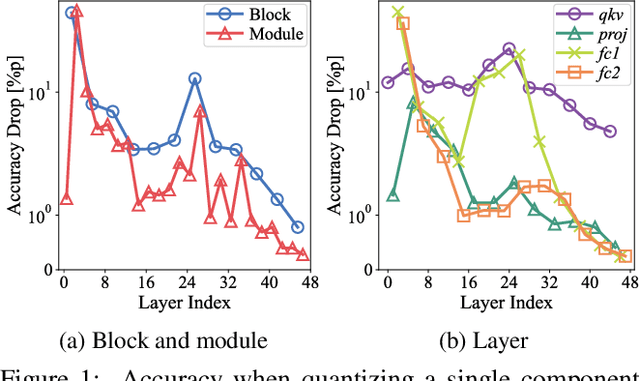

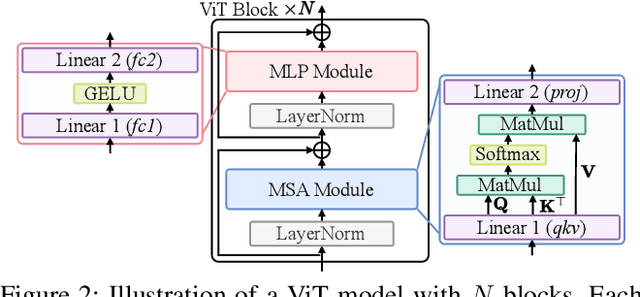

How can we accurately quantize a pre-trained Vision Transformer model? Quantization algorithms compress Vision Transformers (ViTs) into low-bit formats, reducing memory and computation demands with minimal accuracy degradation. However, existing methods rely on uniform precision, ignoring the diverse sensitivity of ViT components to quantization. Metric-based Mixed Precision Quantization (MPQ) is a promising alternative, but previous MPQ methods for ViTs suffer from three major limitations: 1) coarse granularity, 2) mismatch in metric scale across component types, and 3) quantization-unaware bit allocation. In this paper, we propose LampQ (Layer-wise Mixed Precision Quantization for Vision Transformers), an accurate metric-based MPQ method for ViTs to overcome these limitations. LampQ performs layer-wise quantization to achieve both fine-grained control and efficient acceleration, incorporating a type-aware Fisher-based metric to measure sensitivity. Then, LampQ assigns bit-widths optimally through integer linear programming and further updates them iteratively. Extensive experiments show that LampQ provides the state-of-the-art performance in quantizing ViTs pre-trained on various tasks such as image classification, object detection, and zero-shot quantization.
KORMo: Korean Open Reasoning Model for Everyone
Oct 10, 2025



This work presents the first large-scale investigation into constructing a fully open bilingual large language model (LLM) for a non-English language, specifically Korean, trained predominantly on synthetic data. We introduce KORMo-10B, a 10.8B-parameter model trained from scratch on a Korean-English corpus in which 68.74% of the Korean portion is synthetic. Through systematic experimentation, we demonstrate that synthetic data, when carefully curated with balanced linguistic coverage and diverse instruction styles, does not cause instability or degradation during large-scale pretraining. Furthermore, the model achieves performance comparable to that of contemporary open-weight multilingual baselines across a wide range of reasoning, knowledge, and instruction-following benchmarks. Our experiments reveal two key findings: (1) synthetic data can reliably sustain long-horizon pretraining without model collapse, and (2) bilingual instruction tuning enables near-native reasoning and discourse coherence in Korean. By fully releasing all components including data, code, training recipes, and logs, this work establishes a transparent framework for developing synthetic data-driven fully open models (FOMs) in low-resource settings and sets a reproducible precedent for future multilingual LLM research.
Unifying Uniform and Binary-coding Quantization for Accurate Compression of Large Language Models
Jun 04, 2025How can we quantize large language models while preserving accuracy? Quantization is essential for deploying large language models (LLMs) efficiently. Binary-coding quantization (BCQ) and uniform quantization (UQ) are promising quantization schemes that have strong expressiveness and optimizability, respectively. However, neither scheme leverages both advantages. In this paper, we propose UniQuanF (Unified Quantization with Flexible Mapping), an accurate quantization method for LLMs. UniQuanF harnesses both strong expressiveness and optimizability by unifying the flexible mapping technique in UQ and non-uniform quantization levels of BCQ. We propose unified initialization, and local and periodic mapping techniques to optimize the parameters in UniQuanF precisely. After optimization, our unification theorem removes computational and memory overhead, allowing us to utilize the superior accuracy of UniQuanF without extra deployment costs induced by the unification. Experimental results demonstrate that UniQuanF outperforms existing UQ and BCQ methods, achieving up to 4.60% higher accuracy on GSM8K benchmark.
Context Robust Knowledge Editing for Language Models
May 29, 2025Knowledge editing (KE) methods offer an efficient way to modify knowledge in large language models. Current KE evaluations typically assess editing success by considering only the edited knowledge without any preceding contexts. In real-world applications, however, preceding contexts often trigger the retrieval of the original knowledge and undermine the intended edit. To address this issue, we develop CHED -- a benchmark designed to evaluate the context robustness of KE methods. Evaluations on CHED show that they often fail when preceding contexts are present. To mitigate this shortcoming, we introduce CoRE, a KE method designed to strengthen context robustness by minimizing context-sensitive variance in hidden states of the model for edited knowledge. This method not only improves the editing success rate in situations where a preceding context is present but also preserves the overall capabilities of the model. We provide an in-depth analysis of the differing impacts of preceding contexts when introduced as user utterances versus assistant responses, and we dissect attention-score patterns to assess how specific tokens influence editing success.