 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Integer Linear Programming with Parallel Tempering
May 28, 2026Integer Linear Programming (ILP) serves as a versatile framework for modeling a wide range of combinatorial optimization problems, typically addressed by sophisticated exact solvers or heuristics. While learning-based approaches have recently shown their effectiveness, they suffer from poor generalization to out-of-distribution instances and inherent dependence on external solvers. In this work, we propose a solver-free, sampling-based optimization framework for ILP that directly explores discrete feasible regions without training or external solvers. Exploiting the linear structure of ILP, we employ a Locally-Balanced Proposal to construct a transition kernel, thereby avoiding the gradient approximation. To overcome the highly multimodal nature of ILP energy landscapes, we integrate Parallel Tempering. In addition to standard temperature tempering, we introduce penalty tempering, which modulates constraint barriers while preserving the objective landscape over feasible solutions. Empirically, our method consistently outperforms SCIP across all four benchmarks, matches or exceeds Gurobi on two of four tasks within a 200-second budget, and is substantially more robust to distribution shift than learning-based methods. Furthermore, on MIPLIB 2017 instances, our framework remains competitive with classical solvers without any problem-specific tuning.
Aligning Few-Step Generative Models by Amortizing Sample-based Variational Inference
May 27, 2026Aligning a few-step generative model is challenging, since existing alignment frameworks typically rely on restrictive assumptions: a tractable likelihood, a specific ODE/SDE solver, or a particular model family. We introduce FAV, Few-step Generative Models Alignment via Sample-based Variational Inference, a general alignment framework that requires only sample access to the generator and the reference distribution. We cast alignment as sampling from a reward-tilted distribution anchored to a reference distribution. We leverage Stein Variational Gradient Descent as a sample-based variational inference scheme and amortize its particle updates into the generator parameters via fixed-point regression. We evaluate FAV on two domains: robotics manipulation and image generator alignment. On generative policy alignment for robotic manipulation, FAV outperforms prevailing policy extraction baselines across 56 offline and 30 offline-to-online RL tasks. For image generator alignment, FAV fine-tunes diverse few-step backbones, including GAN, drifting model, consistency models, and flow maps, scaling from ImageNet-$256$ to 1024$^2$ text-to-image synthesis. Code is available at https://github.com/Jaewoopudding/FAV.
Rethinking Positional Encoding for Neural Vehicle Routing
May 12, 2026Transformer-based models have become the dominant paradigm for neural combinatorial optimization (NCO) of vehicle routing problems (VRPs), yet the role of positional encoding (PE) in these architectures remains largely unexplored. Unlike natural language, where tokens are uniformly spaced on a line, routing solutions exhibit several properties that render standard NLP positional encodings inadequate. In this work, we formalize three such structural properties that a routing-aware PE should respect, namely anisometric node distances, cyclic and direction-aware topology, and hierarchical depot-anchored global multi-route structure, combining them with a unifying design principle of geometric grounding. Guided by these criteria, we analyze and compare PE methods spanning NLP, graph-transformer, and routing-specific families, and propose a hierarchical anisometric PE that combines a distance-indexed, circularly consistent in-route encoding with a depot-anchored angular cross-route encoding. Extensive experiments across diverse VRP variants demonstrate that geometry-grounded PE consistently outperforms index-based alternatives, with gains that transfer across problem variants, model architectures, and distribution shifts.
EvoNav: Evolutionary Reward Function Design for Robot Navigation with Large Language Models
May 12, 2026Robot navigation is a crucial task with applications to social robots in dynamic human environments. While Reinforcement Learning (RL) has shown great promise for this problem, the policy quality is highly sensitive to the specification of reward functions. Hand-crafted rewards require substantial domain expertise and embed inductive biases that are difficult to audit or adapt, limiting their effectiveness and leading to suboptimal performance. In this paper, we propose EvoNav, an evolutionary framework that automates the design of robot navigation reward functions via large language models (LLMs). To overcome prohibitively costly policy training, EvoNav evaluates each candidate proposal from the LLM via a progressive three-stage warm-up-boost procedure. EvoNav advances from analytical proxies with low-cost surrogates, such as small datasets and analytic rules, to lightweight rollouts and, finally, to full policy training, enabling computationally efficient exploration under effective feedback. Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods.
Cooperative Informative Sensing for Monitoring Dynamic Indoor Environments via Multi-Agent Reinforcement Learning
Apr 25, 2026Monitoring human activity in indoor environments is important for applications such as facility management, safety assessment, and space utilization analysis. While mobile robot teams offer the potential to actively improve observation quality, existing multi-robot monitoring and active perception approaches typically rely on coverage or visitation based objectives that are weakly aligned with the accuracy requirements of human-centric monitoring tasks. In this work, we formulate cooperative active observation as a decentralized control problem in which multiple robots adjust their motion to directly optimize monitoring accuracy under partial observability. We propose a learning-based framework for cooperative policies from decentralized observations using multi-agent reinforcement learning (MARL), supported by an architecture that handles variable numbers of humans and temporal dependencies. Simulation results across diverse indoor environments and monitoring tasks show that the proposed approach consistently outperforms classical coverage, persistent monitoring, and learning-free multi-robot baselines, while remaining robust to changes in the number of observed humans.
JudgeFlow: Agentic Workflow Optimization via Block Judge
Jan 12, 2026Optimizing LLM-based agentic workflows is challenging for scaling AI capabilities. Current methods rely on coarse, end-to-end evaluation signals and lack fine-grained signals on where to refine, often resulting in inefficient or low-impact modifications. To address these limitations, we propose {\our{}}, an Evaluation-Judge-Optimization-Update pipeline. We incorporate reusable, configurable logic blocks into agentic workflows to capture fundamental forms of logic. On top of this abstraction, we design a dedicated Judge module that inspects execution traces -- particularly failed runs -- and assigns rank-based responsibility scores to problematic blocks. These fine-grained diagnostic signals are then leveraged by an LLM-based optimizer, which focuses modifications on the most problematic block in the workflow. Our approach improves sample efficiency, enhances interpretability through block-level diagnostics, and provides a scalable foundation for automating increasingly complex agentic workflows. We evaluate {\our{}} on mathematical reasoning and code generation benchmarks, where {\our{}} achieves superior performance and efficiency compared to existing methods. The source code is publicly available at https://github.com/ma-zihan/JudgeFlow.
Priority-Aware Multi-Robot Coverage Path Planning
Jan 02, 2026Multi-robot systems are widely used for coverage tasks that require efficient coordination across large environments. In Multi-Robot Coverage Path Planning (MCPP), the objective is typically to minimize the makespan by generating non-overlapping paths for full-area coverage. However, most existing methods assume uniform importance across regions, limiting their effectiveness in scenarios where some zones require faster attention. We introduce the Priority-Aware MCPP (PA-MCPP) problem, where a subset of the environment is designated as prioritized zones with associated weights. The goal is to minimize, in lexicographic order, the total priority-weighted latency of zone coverage and the overall makespan. To address this, we propose a scalable two-phase framework combining (1) greedy zone assignment with local search, spanning-tree-based path planning, and (2) Steiner-tree-guided residual coverage. Experiments across diverse scenarios demonstrate that our method significantly reduces priority-weighted latency compared to standard MCPP baselines, while maintaining competitive makespan. Sensitivity analyses further show that the method scales well with the number of robots and that zone coverage behavior can be effectively controlled by adjusting priority weights.
Adaptive Replay Buffer for Offline-to-Online Reinforcement Learning
Dec 11, 2025Offline-to-Online Reinforcement Learning (O2O RL) faces a critical dilemma in balancing the use of a fixed offline dataset with newly collected online experiences. Standard methods, often relying on a fixed data-mixing ratio, struggle to manage the trade-off between early learning stability and asymptotic performance. To overcome this, we introduce the Adaptive Replay Buffer (ARB), a novel approach that dynamically prioritizes data sampling based on a lightweight metric we call 'on-policyness'. Unlike prior methods that rely on complex learning procedures or fixed ratios, ARB is designed to be learning-free and simple to implement, seamlessly integrating into existing O2O RL algorithms. It assesses how closely collected trajectories align with the current policy's behavior and assigns a proportional sampling weight to each transition within that trajectory. This strategy effectively leverages offline data for initial stability while progressively focusing learning on the most relevant, high-rewarding online experiences. Our extensive experiments on D4RL benchmarks demonstrate that ARB consistently mitigates early performance degradation and significantly improves the final performance of various O2O RL algorithms, highlighting the importance of an adaptive, behavior-aware replay buffer design.
VRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
Oct 08, 2025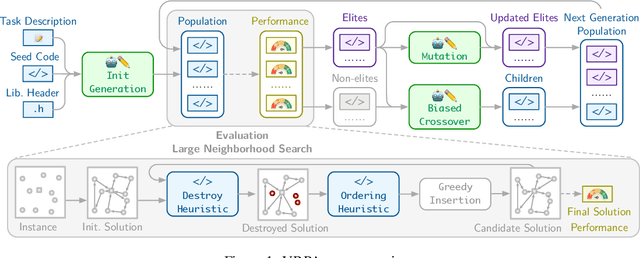
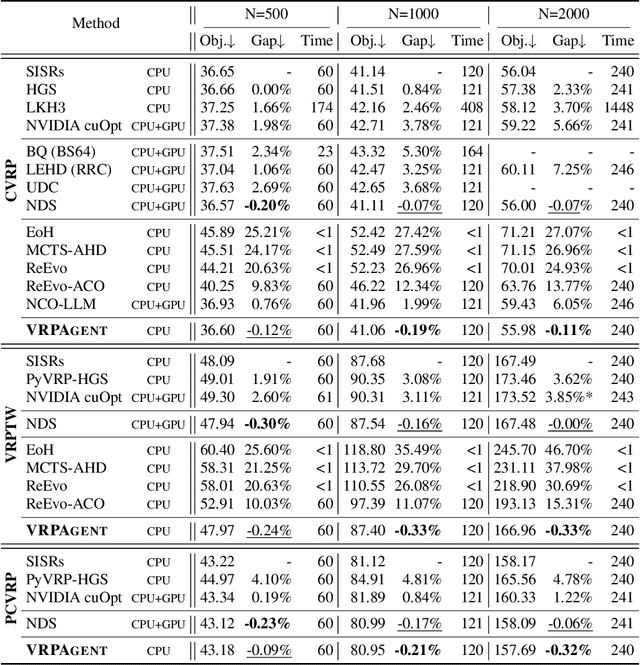
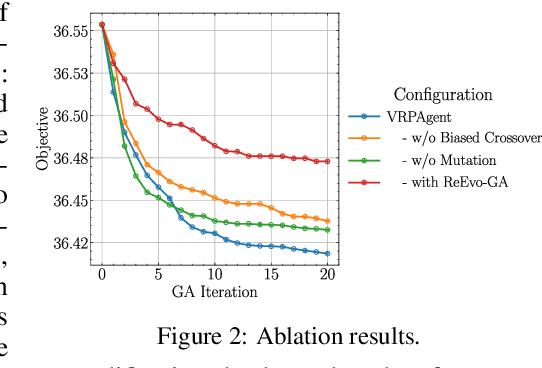
Designing high-performing heuristics for vehicle routing problems (VRPs) is a complex task that requires both intuition and deep domain knowledge. Large language model (LLM)-based code generation has recently shown promise across many domains, but it still falls short of producing heuristics that rival those crafted by human experts. In this paper, we propose VRPAgent, a framework that integrates LLM-generated components into a metaheuristic and refines them through a novel genetic search. By using the LLM to generate problem-specific operators, embedded within a generic metaheuristic framework, VRPAgent keeps tasks manageable, guarantees correctness, and still enables the discovery of novel and powerful strategies. Across multiple problems, including the capacitated VRP, the VRP with time windows, and the prize-collecting VRP, our method discovers heuristic operators that outperform handcrafted methods and recent learning-based approaches while requiring only a single CPU core. To our knowledge, \VRPAgent is the first LLM-based paradigm to advance the state-of-the-art in VRPs, highlighting a promising future for automated heuristics discovery.
Diffusion Alignment as Variational Expectation-Maximization
Oct 01, 2025Diffusion alignment aims to optimize diffusion models for the downstream objective. While existing methods based on reinforcement learning or direct backpropagation achieve considerable success in maximizing rewards, they often suffer from reward over-optimization and mode collapse. We introduce Diffusion Alignment as Variational Expectation-Maximization (DAV), a framework that formulates diffusion alignment as an iterative process alternating between two complementary phases: the E-step and the M-step. In the E-step, we employ test-time search to generate diverse and reward-aligned samples. In the M-step, we refine the diffusion model using samples discovered by the E-step. We demonstrate that DAV can optimize reward while preserving diversity for both continuous and discrete tasks: text-to-image synthesis and DNA sequence design.