 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Positional Encoding for Neural Vehicle Routing
May 12, 2026Transformer-based models have become the dominant paradigm for neural combinatorial optimization (NCO) of vehicle routing problems (VRPs), yet the role of positional encoding (PE) in these architectures remains largely unexplored. Unlike natural language, where tokens are uniformly spaced on a line, routing solutions exhibit several properties that render standard NLP positional encodings inadequate. In this work, we formalize three such structural properties that a routing-aware PE should respect, namely anisometric node distances, cyclic and direction-aware topology, and hierarchical depot-anchored global multi-route structure, combining them with a unifying design principle of geometric grounding. Guided by these criteria, we analyze and compare PE methods spanning NLP, graph-transformer, and routing-specific families, and propose a hierarchical anisometric PE that combines a distance-indexed, circularly consistent in-route encoding with a depot-anchored angular cross-route encoding. Extensive experiments across diverse VRP variants demonstrate that geometry-grounded PE consistently outperforms index-based alternatives, with gains that transfer across problem variants, model architectures, and distribution shifts.
EvoNav: Evolutionary Reward Function Design for Robot Navigation with Large Language Models
May 12, 2026Robot navigation is a crucial task with applications to social robots in dynamic human environments. While Reinforcement Learning (RL) has shown great promise for this problem, the policy quality is highly sensitive to the specification of reward functions. Hand-crafted rewards require substantial domain expertise and embed inductive biases that are difficult to audit or adapt, limiting their effectiveness and leading to suboptimal performance. In this paper, we propose EvoNav, an evolutionary framework that automates the design of robot navigation reward functions via large language models (LLMs). To overcome prohibitively costly policy training, EvoNav evaluates each candidate proposal from the LLM via a progressive three-stage warm-up-boost procedure. EvoNav advances from analytical proxies with low-cost surrogates, such as small datasets and analytic rules, to lightweight rollouts and, finally, to full policy training, enabling computationally efficient exploration under effective feedback. Experiment results show that EvoNav produces more effective navigation policies than manually designed RL rewards and state-of-the-art reward design methods.
JudgeFlow: Agentic Workflow Optimization via Block Judge
Jan 12, 2026Optimizing LLM-based agentic workflows is challenging for scaling AI capabilities. Current methods rely on coarse, end-to-end evaluation signals and lack fine-grained signals on where to refine, often resulting in inefficient or low-impact modifications. To address these limitations, we propose {\our{}}, an Evaluation-Judge-Optimization-Update pipeline. We incorporate reusable, configurable logic blocks into agentic workflows to capture fundamental forms of logic. On top of this abstraction, we design a dedicated Judge module that inspects execution traces -- particularly failed runs -- and assigns rank-based responsibility scores to problematic blocks. These fine-grained diagnostic signals are then leveraged by an LLM-based optimizer, which focuses modifications on the most problematic block in the workflow. Our approach improves sample efficiency, enhances interpretability through block-level diagnostics, and provides a scalable foundation for automating increasingly complex agentic workflows. We evaluate {\our{}} on mathematical reasoning and code generation benchmarks, where {\our{}} achieves superior performance and efficiency compared to existing methods. The source code is publicly available at https://github.com/ma-zihan/JudgeFlow.
VRPAgent: LLM-Driven Discovery of Heuristic Operators for Vehicle Routing Problems
Oct 08, 2025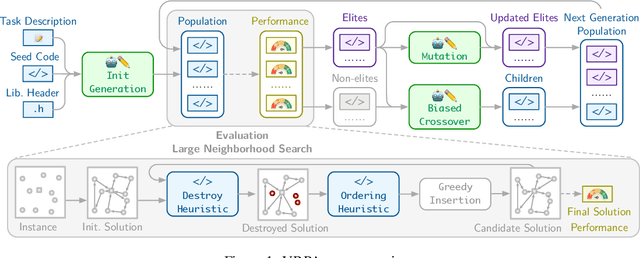
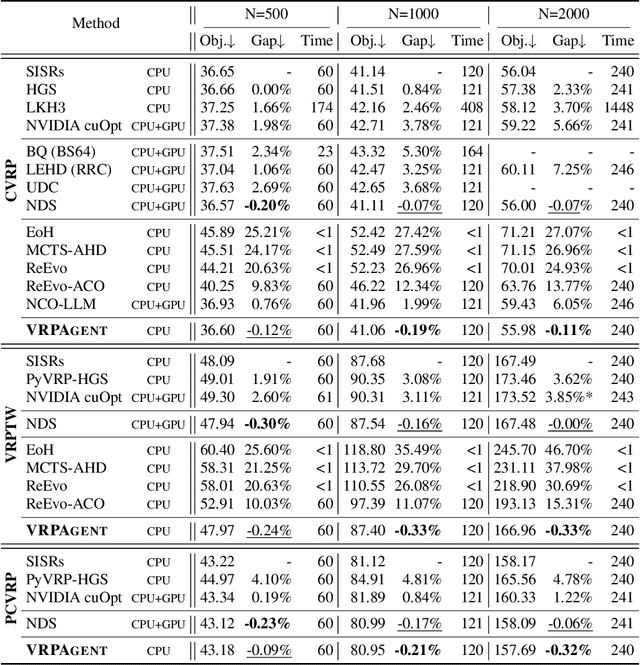
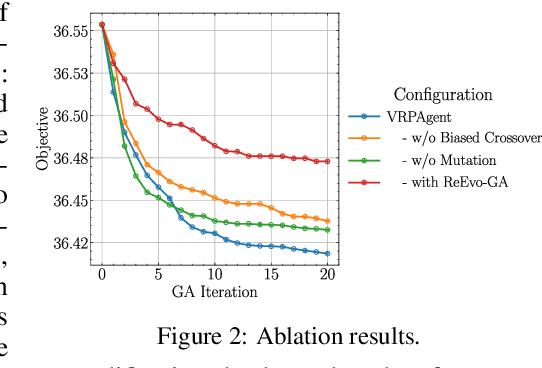
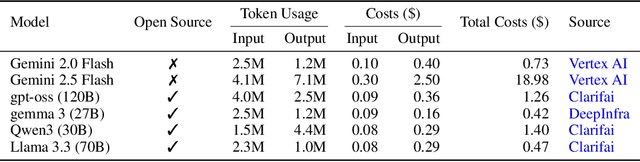
Designing high-performing heuristics for vehicle routing problems (VRPs) is a complex task that requires both intuition and deep domain knowledge. Large language model (LLM)-based code generation has recently shown promise across many domains, but it still falls short of producing heuristics that rival those crafted by human experts. In this paper, we propose VRPAgent, a framework that integrates LLM-generated components into a metaheuristic and refines them through a novel genetic search. By using the LLM to generate problem-specific operators, embedded within a generic metaheuristic framework, VRPAgent keeps tasks manageable, guarantees correctness, and still enables the discovery of novel and powerful strategies. Across multiple problems, including the capacitated VRP, the VRP with time windows, and the prize-collecting VRP, our method discovers heuristic operators that outperform handcrafted methods and recent learning-based approaches while requiring only a single CPU core. To our knowledge, \VRPAgent is the first LLM-based paradigm to advance the state-of-the-art in VRPs, highlighting a promising future for automated heuristics discovery.
TrajEvo: Trajectory Prediction Heuristics Design via LLM-driven Evolution
Aug 07, 2025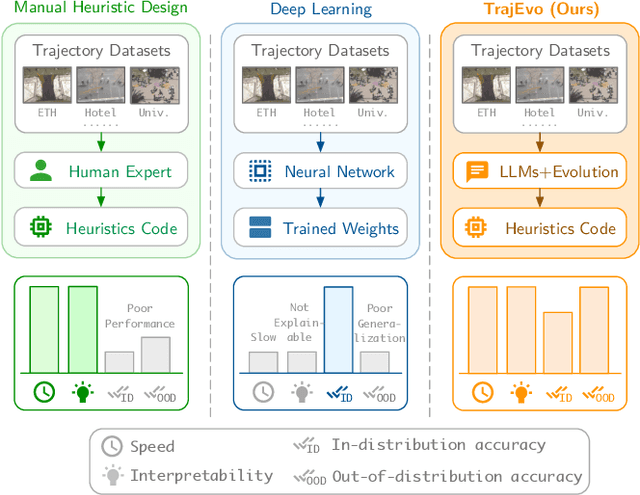
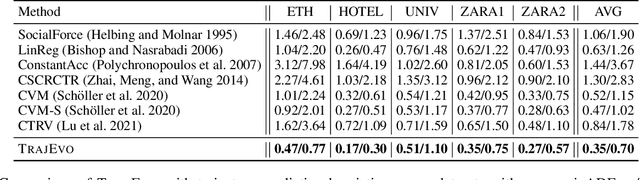
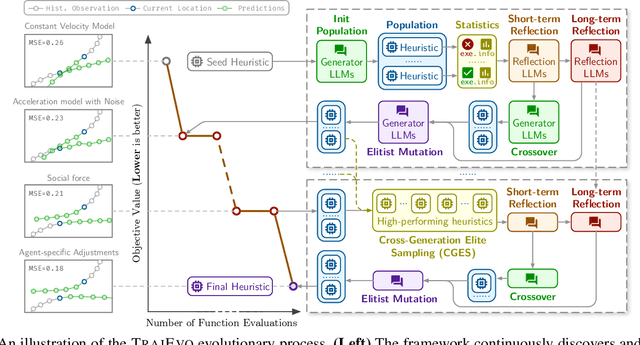
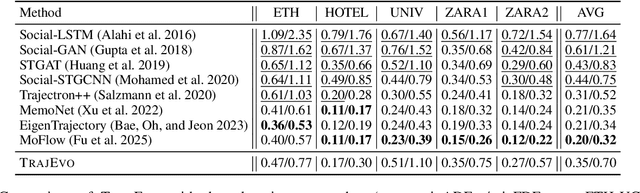
Trajectory prediction is a critical task in modeling human behavior, especially in safety-critical domains such as social robotics and autonomous vehicle navigation. Traditional heuristics based on handcrafted rules often lack accuracy and generalizability. Although deep learning approaches offer improved performance, they typically suffer from high computational cost, limited explainability, and, importantly, poor generalization to out-of-distribution (OOD) scenarios. In this paper, we introduce TrajEvo, a framework that leverages Large Language Models (LLMs) to automatically design trajectory prediction heuristics. TrajEvo employs an evolutionary algorithm to generate and refine prediction heuristics from past trajectory data. We propose two key innovations: Cross-Generation Elite Sampling to encourage population diversity, and a Statistics Feedback Loop that enables the LLM to analyze and improve alternative predictions. Our evaluations demonstrate that TrajEvo outperforms existing heuristic methods across multiple real-world datasets, and notably surpasses both heuristic and deep learning methods in generalizing to an unseen OOD real-world dataset. TrajEvo marks a promising step toward the automated design of fast, explainable, and generalizable trajectory prediction heuristics. We release our source code to facilitate future research at https://github.com/ai4co/trajevo.
USPR: Learning a Unified Solver for Profiled Routing
May 08, 2025The Profiled Vehicle Routing Problem (PVRP) extends the classical VRP by incorporating vehicle-client-specific preferences and constraints, reflecting real-world requirements such as zone restrictions and service-level preferences. While recent reinforcement learning (RL) solvers have shown promise, they require retraining for each new profile distribution, suffer from poor representation ability, and struggle to generalize to out-of-distribution instances. In this paper, we address these limitations by introducing USPR (Unified Solver for Profiled Routing), a novel framework that natively handles arbitrary profile types. USPR introduces three key innovations: (i) Profile Embeddings (PE) to encode any combination of profile types; (ii) Multi-Head Profiled Attention (MHPA), an attention mechanism that models rich interactions between vehicles and clients; (iii) Profile-aware Score Reshaping (PSR), which dynamically adjusts decoder logits using profile scores to improve generalization. Empirical results on diverse PVRP benchmarks demonstrate that USPR achieves state-of-the-art results among learning-based methods while offering significant gains in flexibility and computational efficiency. We make our source code publicly available to foster future research at https://github.com/ai4co/uspr.
TrajEvo: Designing Trajectory Prediction Heuristics via LLM-driven Evolution
May 07, 2025



Trajectory prediction is a crucial task in modeling human behavior, especially in fields as social robotics and autonomous vehicle navigation. Traditional heuristics based on handcrafted rules often lack accuracy, while recently proposed deep learning approaches suffer from computational cost, lack of explainability, and generalization issues that limit their practical adoption. In this paper, we introduce TrajEvo, a framework that leverages Large Language Models (LLMs) to automatically design trajectory prediction heuristics. TrajEvo employs an evolutionary algorithm to generate and refine prediction heuristics from past trajectory data. We introduce a Cross-Generation Elite Sampling to promote population diversity and a Statistics Feedback Loop allowing the LLM to analyze alternative predictions. Our evaluations show TrajEvo outperforms previous heuristic methods on the ETH-UCY datasets, and remarkably outperforms both heuristics and deep learning methods when generalizing to the unseen SDD dataset. TrajEvo represents a first step toward automated design of fast, explainable, and generalizable trajectory prediction heuristics. We make our source code publicly available to foster future research at https://github.com/ai4co/trajevo.
Neural Combinatorial Optimization for Real-World Routing
Mar 20, 2025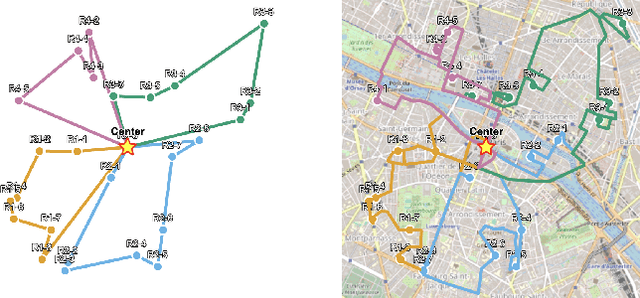



Vehicle Routing Problems (VRPs) are a class of NP-hard problems ubiquitous in several real-world logistics scenarios that pose significant challenges for optimization. Neural Combinatorial Optimization (NCO) has emerged as a promising alternative to classical approaches, as it can learn fast heuristics to solve VRPs. However, most research works in NCO for VRPs focus on simplified settings, which do not account for asymmetric distances and travel durations that cannot be derived by simple Euclidean distances and unrealistic data distributions, hindering real-world deployment. This work introduces RRNCO (Real Routing NCO) to bridge the gap of NCO between synthetic and real-world VRPs in the critical aspects of both data and modeling. First, we introduce a new, openly available dataset with real-world data containing a diverse dataset of locations, distances, and duration matrices from 100 cities, considering realistic settings with actual routing distances and durations obtained from Open Source Routing Machine (OSRM). Second, we propose a novel approach that efficiently processes both node and edge features through contextual gating, enabling the construction of more informed node embedding, and we finally incorporate an Adaptation Attention Free Module (AAFM) with neural adaptive bias mechanisms that effectively integrates not only distance matrices but also angular relationships between nodes, allowing our model to capture rich structural information. RRNCO achieves state-of-the-art results in real-world VRPs among NCO methods. We make our dataset and code publicly available at https://github.com/ai4co/real-routing-nco.
CAMP: Collaborative Attention Model with Profiles for Vehicle Routing Problems
Jan 06, 2025The profiled vehicle routing problem (PVRP) is a generalization of the heterogeneous capacitated vehicle routing problem (HCVRP) in which the objective is to optimize the routes of vehicles to serve client demands subject to different vehicle profiles, with each having a preference or constraint on a per-client basis. While existing learning methods have shown promise for solving the HCVRP in real-time, no learning method exists to solve the more practical and challenging PVRP. In this paper, we propose a Collaborative Attention Model with Profiles (CAMP), a novel approach that learns efficient solvers for PVRP using multi-agent reinforcement learning. CAMP employs a specialized attention-based encoder architecture to embed profiled client embeddings in parallel for each vehicle profile. We design a communication layer between agents for collaborative decision-making across profiled embeddings at each decoding step and a batched pointer mechanism to attend to the profiled embeddings to evaluate the likelihood of the next actions. We evaluate CAMP on two variants of PVRPs: PVRP with preferences, which explicitly influence the reward function, and PVRP with zone constraints with different numbers of agents and clients, demonstrating that our learned solvers achieve competitive results compared to both classical state-of-the-art neural multi-agent models in terms of solution quality and computational efficiency. We make our code openly available at https://github.com/ai4co/camp.
PARCO: Learning Parallel Autoregressive Policies for Efficient Multi-Agent Combinatorial Optimization
Sep 05, 2024



Multi-agent combinatorial optimization problems such as routing and scheduling have great practical relevance but present challenges due to their NP-hard combinatorial nature, hard constraints on the number of possible agents, and hard-to-optimize objective functions. This paper introduces PARCO (Parallel AutoRegressive Combinatorial Optimization), a novel approach that learns fast surrogate solvers for multi-agent combinatorial problems with reinforcement learning by employing parallel autoregressive decoding. We propose a model with a Multiple Pointer Mechanism to efficiently decode multiple decisions simultaneously by different agents, enhanced by a Priority-based Conflict Handling scheme. Moreover, we design specialized Communication Layers that enable effective agent collaboration, thus enriching decision-making. We evaluate PARCO in representative multi-agent combinatorial problems in routing and scheduling and demonstrate that our learned solvers offer competitive results against both classical and neural baselines in terms of both solution quality and speed. We make our code openly available at https://github.com/ai4co/parco.