 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizable Molecular Generation via Soft-constrained GFlowNets with Rich Chemical Priors
Feb 04, 2026The application of generative models for experimental drug discovery campaigns is severely limited by the difficulty of designing molecules de novo that can be synthesized in practice. Previous works have leveraged Generative Flow Networks (GFlowNets) to impose hard synthesizability constraints through the design of state and action spaces based on predefined reaction templates and building blocks. Despite the promising prospects of this approach, it currently lacks flexibility and scalability. As an alternative, we propose S3-GFN, which generates synthesizable SMILES molecules via simple soft regularization of a sequence-based GFlowNet. Our approach leverages rich molecular priors learned from large-scale SMILES corpora to steer molecular generation towards high-reward, synthesizable chemical spaces. The model induces constraints through off-policy replay training with a contrastive learning signal based on separate buffers of synthesizable and unsynthesizable samples. Our experiments show that S3-GFN learns to generate synthesizable molecules ($\geq 95\%$) with higher rewards in diverse tasks.
Improved Off-policy Reinforcement Learning in Biological Sequence Design
Oct 06, 2024
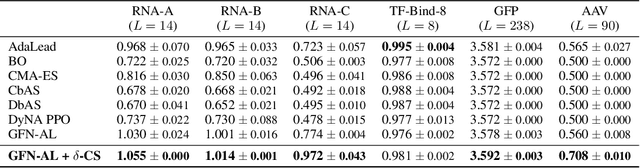
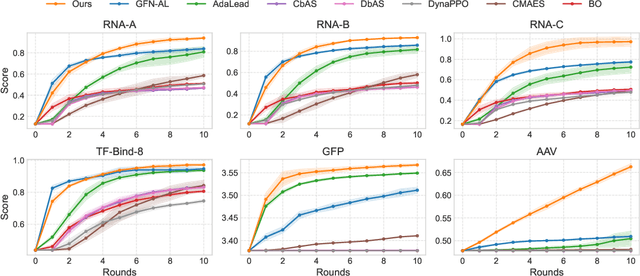
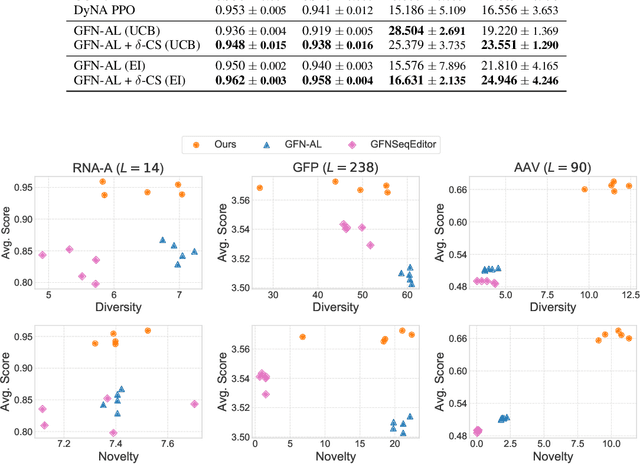
Designing biological sequences with desired properties is a significant challenge due to the combinatorially vast search space and the high cost of evaluating each candidate sequence. To address these challenges, reinforcement learning (RL) methods, such as GFlowNets, utilize proxy models for rapid reward evaluation and annotated data for policy training. Although these approaches have shown promise in generating diverse and novel sequences, the limited training data relative to the vast search space often leads to the misspecification of proxy for out-of-distribution inputs. We introduce $\delta$-Conservative Search, a novel off-policy search method for training GFlowNets designed to improve robustness against proxy misspecification. The key idea is to incorporate conservativeness, controlled by parameter $\delta$, to constrain the search to reliable regions. Specifically, we inject noise into high-score offline sequences by randomly masking tokens with a Bernoulli distribution of parameter $\delta$ and then denoise masked tokens using the GFlowNet policy. Additionally, $\delta$ is adaptively adjusted based on the uncertainty of the proxy model for each data point. This enables the reflection of proxy uncertainty to determine the level of conservativeness. Experimental results demonstrate that our method consistently outperforms existing machine learning methods in discovering high-score sequences across diverse tasks-including DNA, RNA, protein, and peptide design-especially in large-scale scenarios.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024



This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
Genetic-guided GFlowNets: Advancing in Practical Molecular Optimization Benchmark
Feb 05, 2024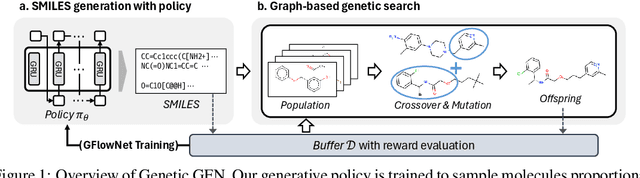
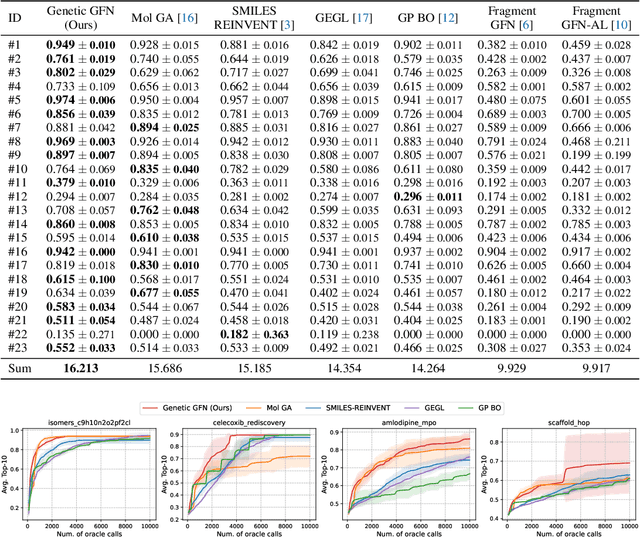

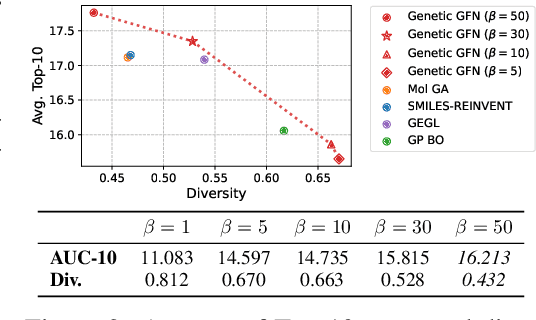
This paper proposes a novel variant of GFlowNet, genetic-guided GFlowNet (Genetic GFN), which integrates an iterative genetic search into GFlowNet. Genetic search effectively guides the GFlowNet to high-rewarded regions, addressing global over-exploration that results in training inefficiency and exploring limited regions. In addition, training strategies, such as rank-based replay training and unsupervised maximum likelihood pre-training, are further introduced to improve the sample efficiency of Genetic GFN. The proposed method shows a state-of-the-art score of 16.213, significantly outperforming the reported best score in the benchmark of 15.185, in practical molecular optimization (PMO), which is an official benchmark for sample-efficient molecular optimization. Remarkably, ours exceeds all baselines, including reinforcement learning, Bayesian optimization, generative models, GFlowNets, and genetic algorithms, in 14 out of 23 tasks.
RL4CO: an Extensive Reinforcement Learning for Combinatorial Optimization Benchmark
Jun 29, 2023
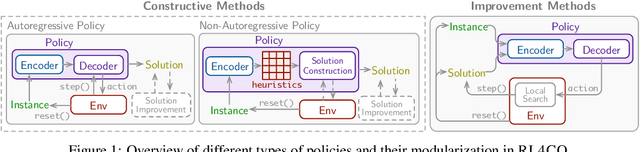

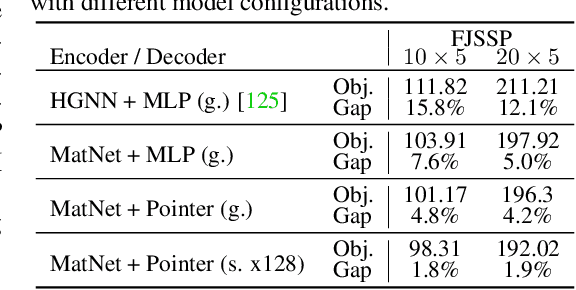
We introduce RL4CO, an extensive reinforcement learning (RL) for combinatorial optimization (CO) benchmark. RL4CO employs state-of-the-art software libraries as well as best practices in implementation, such as modularity and configuration management, to be efficient and easily modifiable by researchers for adaptations of neural network architecture, environments, and algorithms. Contrary to the existing focus on specific tasks like the traveling salesman problem (TSP) for performance assessment, we underline the importance of scalability and generalization capabilities for diverse optimization tasks. We also systematically benchmark sample efficiency, zero-shot generalization, and adaptability to changes in data distributions of various models. Our experiments show that some recent state-of-the-art methods fall behind their predecessors when evaluated using these new metrics, suggesting the necessity for a more balanced view of the performance of neural CO solvers. We hope RL4CO will encourage the exploration of novel solutions to complex real-world tasks, allowing to compare with existing methods through a standardized interface that decouples the science from the software engineering. We make our library publicly available at https://github.com/kaist-silab/rl4co.
A Neural Separation Algorithm for the Rounded Capacity Inequalities
Jun 29, 2023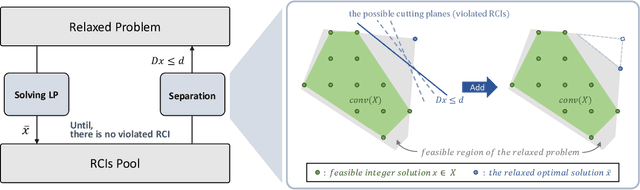
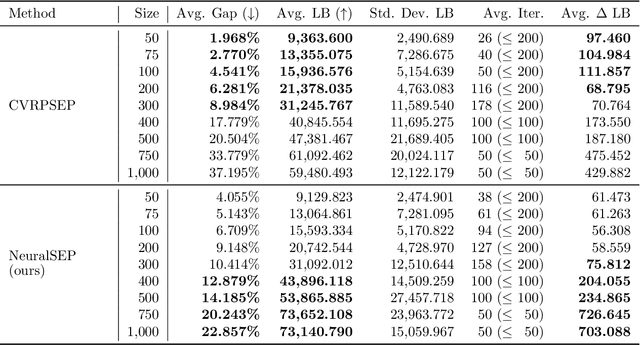
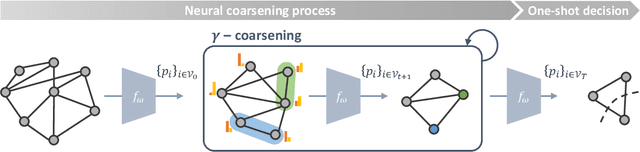
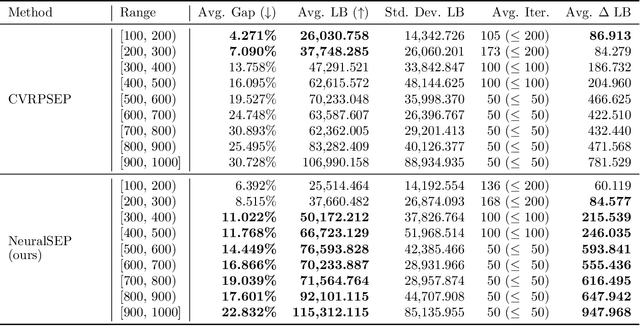
The cutting plane method is a key technique for successful branch-and-cut and branch-price-and-cut algorithms that find the exact optimal solutions for various vehicle routing problems (VRPs). Among various cuts, the rounded capacity inequalities (RCIs) are the most fundamental. To generate RCIs, we need to solve the separation problem, whose exact solution takes a long time to obtain; therefore, heuristic methods are widely used. We design a learning-based separation heuristic algorithm with graph coarsening that learns the solutions of the exact separation problem with a graph neural network (GNN), which is trained with small instances of 50 to 100 customers. We embed our separation algorithm within the cutting plane method to find a lower bound for the capacitated VRP (CVRP) with up to 1,000 customers. We compare the performance of our approach with CVRPSEP, a popular separation software package for various cuts used in solving VRPs. Our computational results show that our approach finds better lower bounds than CVRPSEP for large-scale problems with 400 or more customers, while CVRPSEP shows strong competency for problems with less than 400 customers.
Meta-SAGE: Scale Meta-Learning Scheduled Adaptation with Guided Exploration for Mitigating Scale Shift on Combinatorial Optimization
Jun 07, 2023This paper proposes Meta-SAGE, a novel approach for improving the scalability of deep reinforcement learning models for combinatorial optimization (CO) tasks. Our method adapts pre-trained models to larger-scale problems in test time by suggesting two components: a scale meta-learner (SML) and scheduled adaptation with guided exploration (SAGE). First, SML transforms the context embedding for subsequent adaptation of SAGE based on scale information. Then, SAGE adjusts the model parameters dedicated to the context embedding for a specific instance. SAGE introduces locality bias, which encourages selecting nearby locations to determine the next location. The locality bias gradually decays as the model is adapted to the target instance. Results show that Meta-SAGE outperforms previous adaptation methods and significantly improves scalability in representative CO tasks. Our source code is available at https://github.com/kaist-silab/meta-sage
Symmetric Exploration in Combinatorial Optimization is Free!
Jun 02, 2023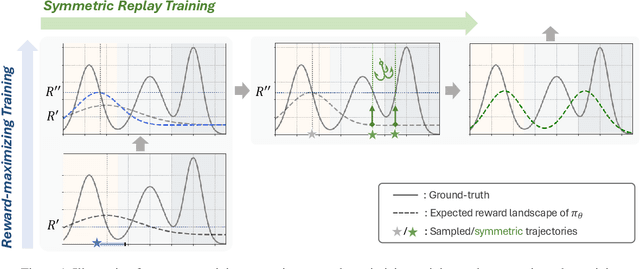
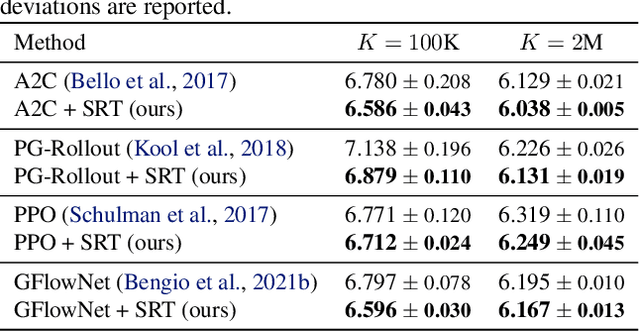
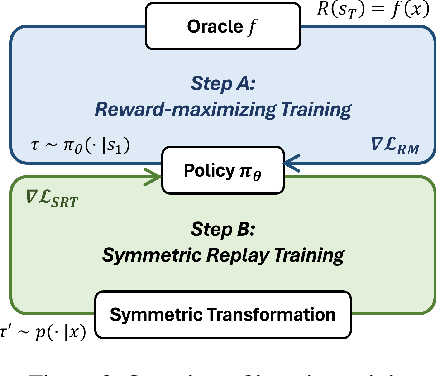
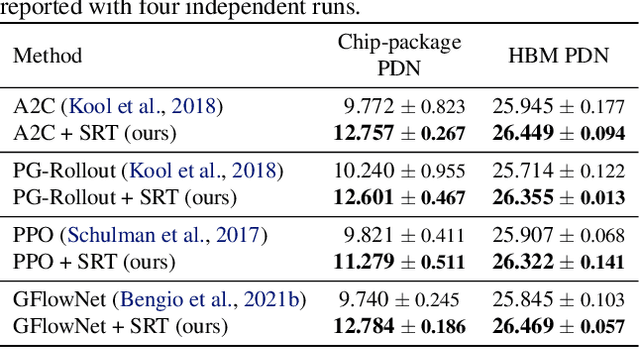
Recently, deep reinforcement learning (DRL) has shown promise in solving combinatorial optimization (CO) problems. However, they often require a large number of evaluations on the objective function, which can be time-consuming in real-world scenarios. To address this issue, we propose a "free" technique to enhance the performance of any deep reinforcement learning (DRL) solver by exploiting symmetry without requiring additional objective function evaluations. Our key idea is to augment the training of DRL-based combinatorial optimization solvers by reward-preserving transformations. The proposed algorithm is likely to be impactful since it is simple, easy to integrate with existing solvers, and applicable to a wide range of combinatorial optimization tasks. Extensive empirical evaluations on NP-hard routing optimization, scheduling optimization, and de novo molecular optimization confirm that our method effortlessly improves the sample efficiency of state-of-the-art DRL algorithms. Our source code is available at https://github.com/kaist-silab/sym-rd.