 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSolving Integer Linear Programming with Parallel Tempering
May 28, 2026Integer Linear Programming (ILP) serves as a versatile framework for modeling a wide range of combinatorial optimization problems, typically addressed by sophisticated exact solvers or heuristics. While learning-based approaches have recently shown their effectiveness, they suffer from poor generalization to out-of-distribution instances and inherent dependence on external solvers. In this work, we propose a solver-free, sampling-based optimization framework for ILP that directly explores discrete feasible regions without training or external solvers. Exploiting the linear structure of ILP, we employ a Locally-Balanced Proposal to construct a transition kernel, thereby avoiding the gradient approximation. To overcome the highly multimodal nature of ILP energy landscapes, we integrate Parallel Tempering. In addition to standard temperature tempering, we introduce penalty tempering, which modulates constraint barriers while preserving the objective landscape over feasible solutions. Empirically, our method consistently outperforms SCIP across all four benchmarks, matches or exceeds Gurobi on two of four tasks within a 200-second budget, and is substantially more robust to distribution shift than learning-based methods. Furthermore, on MIPLIB 2017 instances, our framework remains competitive with classical solvers without any problem-specific tuning.
Aligning Few-Step Generative Models by Amortizing Sample-based Variational Inference
May 27, 2026Aligning a few-step generative model is challenging, since existing alignment frameworks typically rely on restrictive assumptions: a tractable likelihood, a specific ODE/SDE solver, or a particular model family. We introduce FAV, Few-step Generative Models Alignment via Sample-based Variational Inference, a general alignment framework that requires only sample access to the generator and the reference distribution. We cast alignment as sampling from a reward-tilted distribution anchored to a reference distribution. We leverage Stein Variational Gradient Descent as a sample-based variational inference scheme and amortize its particle updates into the generator parameters via fixed-point regression. We evaluate FAV on two domains: robotics manipulation and image generator alignment. On generative policy alignment for robotic manipulation, FAV outperforms prevailing policy extraction baselines across 56 offline and 30 offline-to-online RL tasks. For image generator alignment, FAV fine-tunes diverse few-step backbones, including GAN, drifting model, consistency models, and flow maps, scaling from ImageNet-$256$ to 1024$^2$ text-to-image synthesis. Code is available at https://github.com/Jaewoopudding/FAV.
Discrete diffusion samplers and bridges: Off-policy algorithms and applications in latent spaces
Feb 05, 2026Sampling from a distribution $p(x) \propto e^{-\mathcal{E}(x)}$ known up to a normalising constant is an important and challenging problem in statistics. Recent years have seen the rise of a new family of amortised sampling algorithms, commonly referred to as diffusion samplers, that enable fast and efficient sampling from an unnormalised density. Such algorithms have been widely studied for continuous-space sampling tasks; however, their application to problems in discrete space remains largely unexplored. Although some progress has been made in this area, discrete diffusion samplers do not take full advantage of ideas commonly used for continuous-space sampling. In this paper, we propose to bridge this gap by introducing off-policy training techniques for discrete diffusion samplers. We show that these techniques improve the performance of discrete samplers on both established and new synthetic benchmarks. Next, we generalise discrete diffusion samplers to the task of bridging between two arbitrary distributions, introducing data-to-energy Schrödinger bridge training for the discrete domain for the first time. Lastly, we showcase the application of the proposed diffusion samplers to data-free posterior sampling in the discrete latent spaces of image generative models.
SocraticKG: Knowledge Graph Construction via QA-Driven Fact Extraction
Jan 15, 2026Constructing Knowledge Graphs (KGs) from unstructured text provides a structured framework for knowledge representation and reasoning, yet current LLM-based approaches struggle with a fundamental trade-off: factual coverage often leads to relational fragmentation, while premature consolidation causes information loss. To address this, we propose SocraticKG, an automated KG construction method that introduces question-answer pairs as a structured intermediate representation to systematically unfold document-level semantics prior to triple extraction. By employing 5W1H-guided QA expansion, SocraticKG captures contextual dependencies and implicit relational links typically lost in direct KG extraction pipelines, providing explicit grounding in the source document that helps mitigate implicit reasoning errors. Evaluation on the MINE benchmark demonstrates that our approach effectively addresses the coverage-connectivity trade-off, achieving superior factual retention while maintaining high structural cohesion even as extracted knowledge volume substantially expands. These results highlight that QA-mediated semantic scaffolding plays a critical role in structuring semantics prior to KG extraction, enabling more coherent and reliable graph construction in subsequent stages.
Diffusion Alignment as Variational Expectation-Maximization
Oct 01, 2025Diffusion alignment aims to optimize diffusion models for the downstream objective. While existing methods based on reinforcement learning or direct backpropagation achieve considerable success in maximizing rewards, they often suffer from reward over-optimization and mode collapse. We introduce Diffusion Alignment as Variational Expectation-Maximization (DAV), a framework that formulates diffusion alignment as an iterative process alternating between two complementary phases: the E-step and the M-step. In the E-step, we employ test-time search to generate diverse and reward-aligned samples. In the M-step, we refine the diffusion model using samples discovered by the E-step. We demonstrate that DAV can optimize reward while preserving diversity for both continuous and discrete tasks: text-to-image synthesis and DNA sequence design.
Knowledge Synthesis of Photosynthesis Research Using a Large Language Model
Feb 03, 2025The development of biological data analysis tools and large language models (LLMs) has opened up new possibilities for utilizing AI in plant science research, with the potential to contribute significantly to knowledge integration and research gap identification. Nonetheless, current LLMs struggle to handle complex biological data and theoretical models in photosynthesis research and often fail to provide accurate scientific contexts. Therefore, this study proposed a photosynthesis research assistant (PRAG) based on OpenAI's GPT-4o with retrieval-augmented generation (RAG) techniques and prompt optimization. Vector databases and an automated feedback loop were used in the prompt optimization process to enhance the accuracy and relevance of the responses to photosynthesis-related queries. PRAG showed an average improvement of 8.7% across five metrics related to scientific writing, with a 25.4% increase in source transparency. Additionally, its scientific depth and domain coverage were comparable to those of photosynthesis research papers. A knowledge graph was used to structure PRAG's responses with papers within and outside the database, which allowed PRAG to match key entities with 63% and 39.5% of the database and test papers, respectively. PRAG can be applied for photosynthesis research and broader plant science domains, paving the way for more in-depth data analysis and predictive capabilities.
Improved Off-policy Reinforcement Learning in Biological Sequence Design
Oct 06, 2024
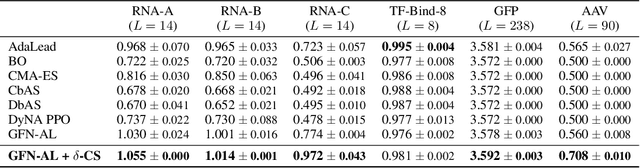
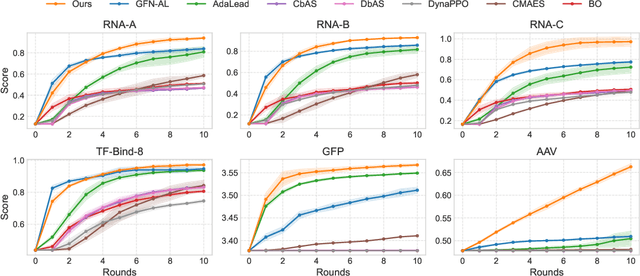
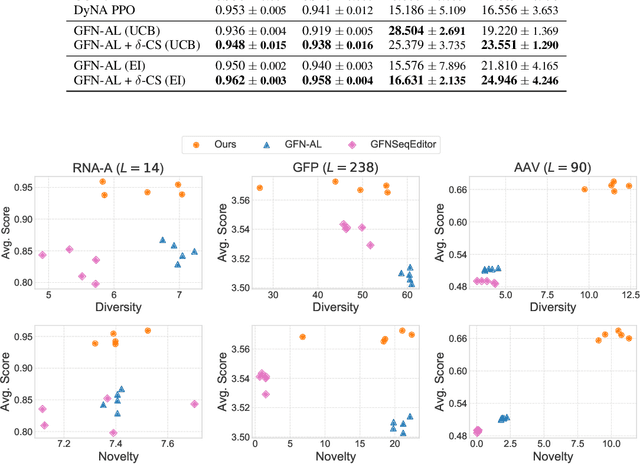
Designing biological sequences with desired properties is a significant challenge due to the combinatorially vast search space and the high cost of evaluating each candidate sequence. To address these challenges, reinforcement learning (RL) methods, such as GFlowNets, utilize proxy models for rapid reward evaluation and annotated data for policy training. Although these approaches have shown promise in generating diverse and novel sequences, the limited training data relative to the vast search space often leads to the misspecification of proxy for out-of-distribution inputs. We introduce $\delta$-Conservative Search, a novel off-policy search method for training GFlowNets designed to improve robustness against proxy misspecification. The key idea is to incorporate conservativeness, controlled by parameter $\delta$, to constrain the search to reliable regions. Specifically, we inject noise into high-score offline sequences by randomly masking tokens with a Bernoulli distribution of parameter $\delta$ and then denoise masked tokens using the GFlowNet policy. Additionally, $\delta$ is adaptively adjusted based on the uncertainty of the proxy model for each data point. This enables the reflection of proxy uncertainty to determine the level of conservativeness. Experimental results demonstrate that our method consistently outperforms existing machine learning methods in discovering high-score sequences across diverse tasks-including DNA, RNA, protein, and peptide design-especially in large-scale scenarios.
Adaptive teachers for amortized samplers
Oct 02, 2024



Amortized inference is the task of training a parametric model, such as a neural network, to approximate a distribution with a given unnormalized density where exact sampling is intractable. When sampling is implemented as a sequential decision-making process, reinforcement learning (RL) methods, such as generative flow networks, can be used to train the sampling policy. Off-policy RL training facilitates the discovery of diverse, high-reward candidates, but existing methods still face challenges in efficient exploration. We propose to use an adaptive training distribution (the Teacher) to guide the training of the primary amortized sampler (the Student) by prioritizing high-loss regions. The Teacher, an auxiliary behavior model, is trained to sample high-error regions of the Student and can generalize across unexplored modes, thereby enhancing mode coverage by providing an efficient training curriculum. We validate the effectiveness of this approach in a synthetic environment designed to present an exploration challenge, two diffusion-based sampling tasks, and four biochemical discovery tasks demonstrating its ability to improve sample efficiency and mode coverage.
Ant Colony Sampling with GFlowNets for Combinatorial Optimization
Mar 11, 2024



This paper introduces the Generative Flow Ant Colony Sampler (GFACS), a novel neural-guided meta-heuristic algorithm for combinatorial optimization. GFACS integrates generative flow networks (GFlowNets) with the ant colony optimization (ACO) methodology. GFlowNets, a generative model that learns a constructive policy in combinatorial spaces, enhance ACO by providing an informed prior distribution of decision variables conditioned on input graph instances. Furthermore, we introduce a novel combination of training tricks, including search-guided local exploration, energy normalization, and energy shaping to improve GFACS. Our experimental results demonstrate that GFACS outperforms baseline ACO algorithms in seven CO tasks and is competitive with problem-specific heuristics for vehicle routing problems. The source code is available at \url{https://github.com/ai4co/gfacs}.
Genetic-guided GFlowNets: Advancing in Practical Molecular Optimization Benchmark
Feb 05, 2024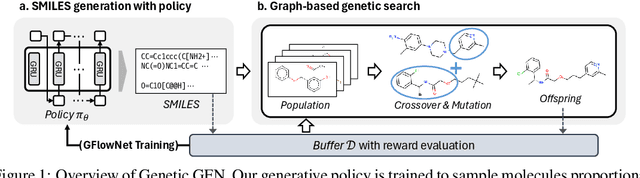
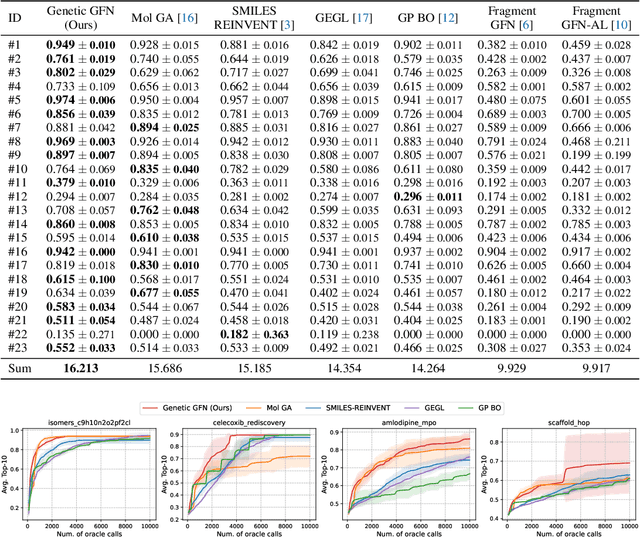

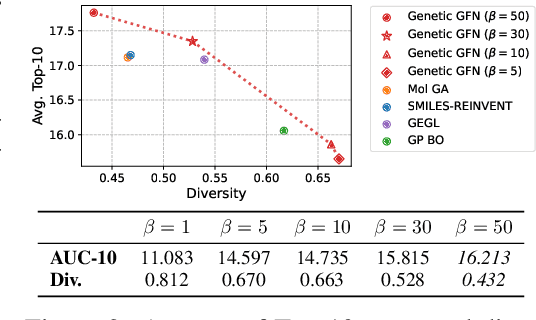
This paper proposes a novel variant of GFlowNet, genetic-guided GFlowNet (Genetic GFN), which integrates an iterative genetic search into GFlowNet. Genetic search effectively guides the GFlowNet to high-rewarded regions, addressing global over-exploration that results in training inefficiency and exploring limited regions. In addition, training strategies, such as rank-based replay training and unsupervised maximum likelihood pre-training, are further introduced to improve the sample efficiency of Genetic GFN. The proposed method shows a state-of-the-art score of 16.213, significantly outperforming the reported best score in the benchmark of 15.185, in practical molecular optimization (PMO), which is an official benchmark for sample-efficient molecular optimization. Remarkably, ours exceeds all baselines, including reinforcement learning, Bayesian optimization, generative models, GFlowNets, and genetic algorithms, in 14 out of 23 tasks.