 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Multimodal Protein Design Enables DNA-Encoding of Chemistry
Apr 06, 2026Evolution is an extraordinary engine for enzymatic diversity, yet the chemistry it has explored remains a narrow slice of what DNA can encode. Deep generative models can design new proteins that bind ligands, but none have created enzymes without pre-specifying catalytic residues. We introduce DISCO (DIffusion for Sequence-structure CO-design), a multimodal model that co-designs protein sequence and 3D structure around arbitrary biomolecules, as well as inference-time scaling methods that optimize objectives across both modalities. Conditioned solely on reactive intermediates, DISCO designs diverse heme enzymes with novel active-site geometries. These enzymes catalyze new-to-nature carbene-transfer reactions, including alkene cyclopropanation, spirocyclopropanation, B-H, and C(sp$^3$)-H insertions, with high activities exceeding those of engineered enzymes. Random mutagenesis of a selected design further confirmed that enzyme activity can be improved through directed evolution. By providing a scalable route to evolvable enzymes, DISCO broadens the potential scope of genetically encodable transformations. Code is available at https://github.com/DISCO-design/DISCO.
Solving Bayesian inverse problems with diffusion priors and off-policy RL
Mar 12, 2025This paper presents a practical application of Relative Trajectory Balance (RTB), a recently introduced off-policy reinforcement learning (RL) objective that can asymptotically solve Bayesian inverse problems optimally. We extend the original work by using RTB to train conditional diffusion model posteriors from pretrained unconditional priors for challenging linear and non-linear inverse problems in vision, and science. We use the objective alongside techniques such as off-policy backtracking exploration to improve training. Importantly, our results show that existing training-free diffusion posterior methods struggle to perform effective posterior inference in latent space due to inherent biases.
Path Planning for Masked Diffusion Model Sampling
Feb 05, 2025In this paper, we investigate how the order in which tokens are unmasked during masked diffusion models (MDMs) inference affects generative quality. We derive an expanded evidence lower bound (ELBO) that introduces a planner, responsible for selecting which tokens to unmask at each step. Our analysis suggests that alternative unmasking strategies can improve generative performance. Based on these insights, we propose Path Planning (P2), a sampling framework that leverages pre-trained BERT or the denoiser itself to guide unmasking decisions. P2 generalizes all known MDM sampling strategies and enables significant improvements across diverse domains including language generation (in-context learning, code generation, story infilling, mathematical reasoning, reverse curse correction) and biological sequence generation (protein and RNA sequences).
From discrete-time policies to continuous-time diffusion samplers: Asymptotic equivalences and faster training
Jan 10, 2025We study the problem of training neural stochastic differential equations, or diffusion models, to sample from a Boltzmann distribution without access to target samples. Existing methods for training such models enforce time-reversal of the generative and noising processes, using either differentiable simulation or off-policy reinforcement learning (RL). We prove equivalences between families of objectives in the limit of infinitesimal discretization steps, linking entropic RL methods (GFlowNets) with continuous-time objects (partial differential equations and path space measures). We further show that an appropriate choice of coarse time discretization during training allows greatly improved sample efficiency and the use of time-local objectives, achieving competitive performance on standard sampling benchmarks with reduced computational cost.
Steering Masked Discrete Diffusion Models via Discrete Denoising Posterior Prediction
Oct 10, 2024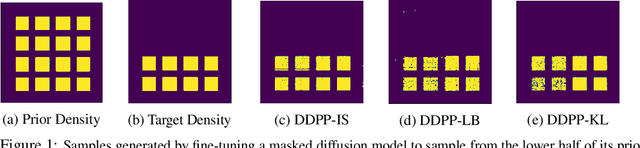

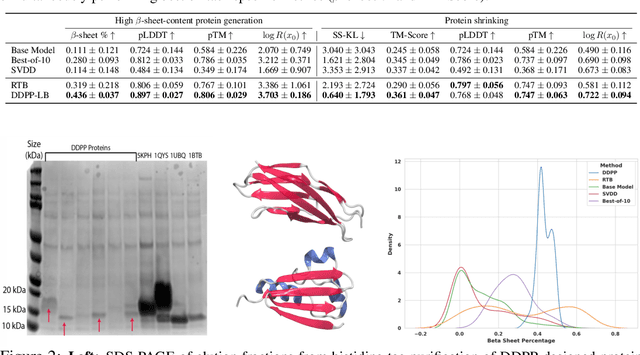

Generative modeling of discrete data underlies important applications spanning text-based agents like ChatGPT to the design of the very building blocks of life in protein sequences. However, application domains need to exert control over the generated data by steering the generative process - typically via RLHF - to satisfy a specified property, reward, or affinity metric. In this paper, we study the problem of steering Masked Diffusion Models (MDMs), a recent class of discrete diffusion models that offer a compelling alternative to traditional autoregressive models. We introduce Discrete Denoising Posterior Prediction (DDPP), a novel framework that casts the task of steering pre-trained MDMs as a problem of probabilistic inference by learning to sample from a target Bayesian posterior. Our DDPP framework leads to a family of three novel objectives that are all simulation-free, and thus scalable while applying to general non-differentiable reward functions. Empirically, we instantiate DDPP by steering MDMs to perform class-conditional pixel-level image modeling, RLHF-based alignment of MDMs using text-based rewards, and finetuning protein language models to generate more diverse secondary structures and shorter proteins. We substantiate our designs via wet-lab validation, where we observe transient expression of reward-optimized protein sequences.
Adaptive teachers for amortized samplers
Oct 02, 2024



Amortized inference is the task of training a parametric model, such as a neural network, to approximate a distribution with a given unnormalized density where exact sampling is intractable. When sampling is implemented as a sequential decision-making process, reinforcement learning (RL) methods, such as generative flow networks, can be used to train the sampling policy. Off-policy RL training facilitates the discovery of diverse, high-reward candidates, but existing methods still face challenges in efficient exploration. We propose to use an adaptive training distribution (the Teacher) to guide the training of the primary amortized sampler (the Student) by prioritizing high-loss regions. The Teacher, an auxiliary behavior model, is trained to sample high-error regions of the Student and can generalize across unexplored modes, thereby enhancing mode coverage by providing an efficient training curriculum. We validate the effectiveness of this approach in a synthetic environment designed to present an exploration challenge, two diffusion-based sampling tasks, and four biochemical discovery tasks demonstrating its ability to improve sample efficiency and mode coverage.
Amortizing intractable inference in diffusion models for vision, language, and control
May 31, 2024



Diffusion models have emerged as effective distribution estimators in vision, language, and reinforcement learning, but their use as priors in downstream tasks poses an intractable posterior inference problem. This paper studies amortized sampling of the posterior over data, $\mathbf{x}\sim p^{\rm post}(\mathbf{x})\propto p(\mathbf{x})r(\mathbf{x})$, in a model that consists of a diffusion generative model prior $p(\mathbf{x})$ and a black-box constraint or likelihood function $r(\mathbf{x})$. We state and prove the asymptotic correctness of a data-free learning objective, relative trajectory balance, for training a diffusion model that samples from this posterior, a problem that existing methods solve only approximately or in restricted cases. Relative trajectory balance arises from the generative flow network perspective on diffusion models, which allows the use of deep reinforcement learning techniques to improve mode coverage. Experiments illustrate the broad potential of unbiased inference of arbitrary posteriors under diffusion priors: in vision (classifier guidance), language (infilling under a discrete diffusion LLM), and multimodal data (text-to-image generation). Beyond generative modeling, we apply relative trajectory balance to the problem of continuous control with a score-based behavior prior, achieving state-of-the-art results on benchmarks in offline reinforcement learning.
Sequence-Augmented SE(3)-Flow Matching For Conditional Protein Backbone Generation
May 30, 2024Proteins are essential for almost all biological processes and derive their diverse functions from complex 3D structures, which are in turn determined by their amino acid sequences. In this paper, we exploit the rich biological inductive bias of amino acid sequences and introduce FoldFlow-2, a novel sequence-conditioned SE(3)-equivariant flow matching model for protein structure generation. FoldFlow-2 presents substantial new architectural features over the previous FoldFlow family of models including a protein large language model to encode sequence, a new multi-modal fusion trunk that combines structure and sequence representations, and a geometric transformer based decoder. To increase diversity and novelty of generated samples -- crucial for de-novo drug design -- we train FoldFlow-2 at scale on a new dataset that is an order of magnitude larger than PDB datasets of prior works, containing both known proteins in PDB and high-quality synthetic structures achieved through filtering. We further demonstrate the ability to align FoldFlow-2 to arbitrary rewards, e.g. increasing secondary structures diversity, by introducing a Reinforced Finetuning (ReFT) objective. We empirically observe that FoldFlow-2 outperforms previous state-of-the-art protein structure-based generative models, improving over RFDiffusion in terms of unconditional generation across all metrics including designability, diversity, and novelty across all protein lengths, as well as exhibiting generalization on the task of equilibrium conformation sampling. Finally, we demonstrate that a fine-tuned FoldFlow-2 makes progress on challenging conditional design tasks such as designing scaffolds for the VHH nanobody.
Generative Active Learning for the Search of Small-molecule Protein Binders
May 02, 2024



Despite substantial progress in machine learning for scientific discovery in recent years, truly de novo design of small molecules which exhibit a property of interest remains a significant challenge. We introduce LambdaZero, a generative active learning approach to search for synthesizable molecules. Powered by deep reinforcement learning, LambdaZero learns to search over the vast space of molecules to discover candidates with a desired property. We apply LambdaZero with molecular docking to design novel small molecules that inhibit the enzyme soluble Epoxide Hydrolase 2 (sEH), while enforcing constraints on synthesizability and drug-likeliness. LambdaZero provides an exponential speedup in terms of the number of calls to the expensive molecular docking oracle, and LambdaZero de novo designed molecules reach docking scores that would otherwise require the virtual screening of a hundred billion molecules. Importantly, LambdaZero discovers novel scaffolds of synthesizable, drug-like inhibitors for sEH. In in vitro experimental validation, a series of ligands from a generated quinazoline-based scaffold were synthesized, and the lead inhibitor N-(4,6-di(pyrrolidin-1-yl)quinazolin-2-yl)-N-methylbenzamide (UM0152893) displayed sub-micromolar enzyme inhibition of sEH.
On diffusion models for amortized inference: Benchmarking and improving stochastic control and sampling
Feb 13, 2024
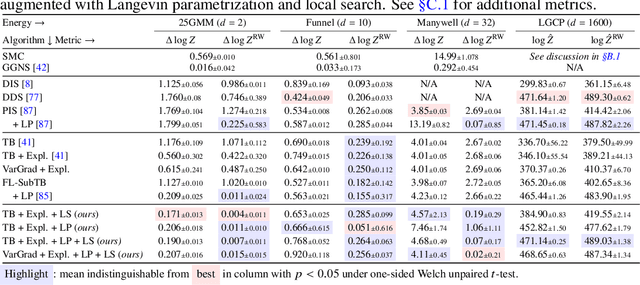
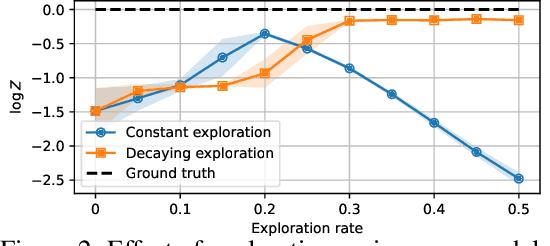
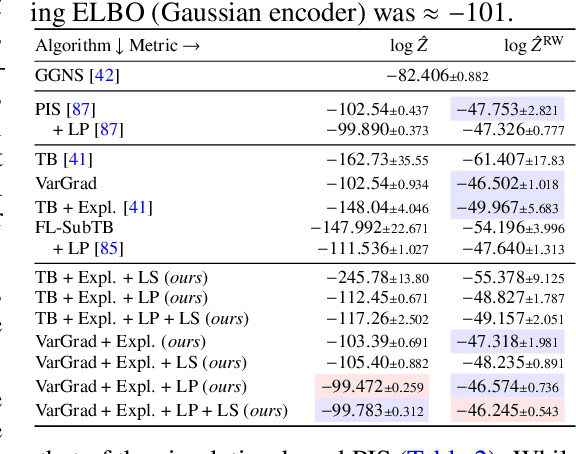
We study the problem of training diffusion models to sample from a distribution with a given unnormalized density or energy function. We benchmark several diffusion-structured inference methods, including simulation-based variational approaches and off-policy methods (continuous generative flow networks). Our results shed light on the relative advantages of existing algorithms while bringing into question some claims from past work. We also propose a novel exploration strategy for off-policy methods, based on local search in the target space with the use of a replay buffer, and show that it improves the quality of samples on a variety of target distributions. Our code for the sampling methods and benchmarks studied is made public at https://github.com/GFNOrg/gfn-diffusion as a base for future work on diffusion models for amortized inference.