 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTapered Off-Policy REINFORCE: Stable and efficient reinforcement learning for LLMs
Mar 19, 2025We propose a new algorithm for fine-tuning large language models using reinforcement learning. Tapered Off-Policy REINFORCE (TOPR) uses an asymmetric, tapered variant of importance sampling to speed up learning while maintaining stable learning dynamics, even without the use of KL regularization. TOPR can be applied in a fully offline fashion, allows the handling of positive and negative examples in a unified framework, and benefits from the implementational simplicity that is typical of Monte Carlo algorithms. We demonstrate the effectiveness of our approach with a series of experiments on the GSM8K and MATH reasoning benchmarks, finding performance gains for training both a model for solution generation and as a generative verifier. We show that properly leveraging positive and negative examples alike in the off-policy regime simultaneously increases test-time accuracy and training data efficiency, all the while avoiding the ``wasted inference'' that comes with discarding negative examples. We find that this advantage persists over multiple iterations of training and can be amplified by dataset curation techniques, enabling us to match 70B-parameter model performance with 8B language models. As a corollary to this work, we find that REINFORCE's baseline parameter plays an important and unexpected role in defining dataset composition in the presence of negative examples, and is consequently critical in driving off-policy performance.
Sequence-Augmented SE(3)-Flow Matching For Conditional Protein Backbone Generation
May 30, 2024Proteins are essential for almost all biological processes and derive their diverse functions from complex 3D structures, which are in turn determined by their amino acid sequences. In this paper, we exploit the rich biological inductive bias of amino acid sequences and introduce FoldFlow-2, a novel sequence-conditioned SE(3)-equivariant flow matching model for protein structure generation. FoldFlow-2 presents substantial new architectural features over the previous FoldFlow family of models including a protein large language model to encode sequence, a new multi-modal fusion trunk that combines structure and sequence representations, and a geometric transformer based decoder. To increase diversity and novelty of generated samples -- crucial for de-novo drug design -- we train FoldFlow-2 at scale on a new dataset that is an order of magnitude larger than PDB datasets of prior works, containing both known proteins in PDB and high-quality synthetic structures achieved through filtering. We further demonstrate the ability to align FoldFlow-2 to arbitrary rewards, e.g. increasing secondary structures diversity, by introducing a Reinforced Finetuning (ReFT) objective. We empirically observe that FoldFlow-2 outperforms previous state-of-the-art protein structure-based generative models, improving over RFDiffusion in terms of unconditional generation across all metrics including designability, diversity, and novelty across all protein lengths, as well as exhibiting generalization on the task of equilibrium conformation sampling. Finally, we demonstrate that a fine-tuned FoldFlow-2 makes progress on challenging conditional design tasks such as designing scaffolds for the VHH nanobody.
GSNs : Generative Stochastic Networks
Mar 23, 2015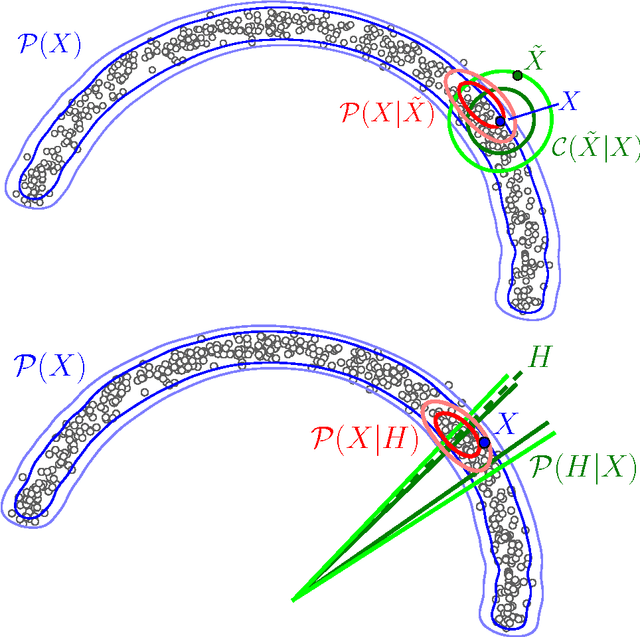


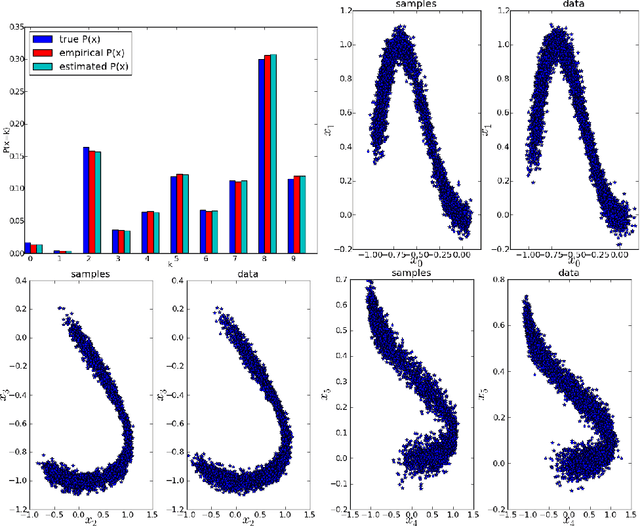
We introduce a novel training principle for probabilistic models that is an alternative to maximum likelihood. The proposed Generative Stochastic Networks (GSN) framework is based on learning the transition operator of a Markov chain whose stationary distribution estimates the data distribution. Because the transition distribution is a conditional distribution generally involving a small move, it has fewer dominant modes, being unimodal in the limit of small moves. Thus, it is easier to learn, more like learning to perform supervised function approximation, with gradients that can be obtained by back-propagation. The theorems provided here generalize recent work on the probabilistic interpretation of denoising auto-encoders and provide an interesting justification for dependency networks and generalized pseudolikelihood (along with defining an appropriate joint distribution and sampling mechanism, even when the conditionals are not consistent). We study how GSNs can be used with missing inputs and can be used to sample subsets of variables given the rest. Successful experiments are conducted, validating these theoretical results, on two image datasets and with a particular architecture that mimics the Deep Boltzmann Machine Gibbs sampler but allows training to proceed with backprop, without the need for layerwise pretraining.