 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeESCT3D: Efficient and Selectively Controllable Text-Driven 3D Content Generation with Gaussian Splatting
Apr 14, 2025In recent years, significant advancements have been made in text-driven 3D content generation. However, several challenges remain. In practical applications, users often provide extremely simple text inputs while expecting high-quality 3D content. Generating optimal results from such minimal text is a difficult task due to the strong dependency of text-to-3D models on the quality of input prompts. Moreover, the generation process exhibits high variability, making it difficult to control. Consequently, multiple iterations are typically required to produce content that meets user expectations, reducing generation efficiency. To address this issue, we propose GPT-4V for self-optimization, which significantly enhances the efficiency of generating satisfactory content in a single attempt. Furthermore, the controllability of text-to-3D generation methods has not been fully explored. Our approach enables users to not only provide textual descriptions but also specify additional conditions, such as style, edges, scribbles, poses, or combinations of multiple conditions, allowing for more precise control over the generated 3D content. Additionally, during training, we effectively integrate multi-view information, including multi-view depth, masks, features, and images, to address the common Janus problem in 3D content generation. Extensive experiments demonstrate that our method achieves robust generalization, facilitating the efficient and controllable generation of high-quality 3D content.
Template Matters: Understanding the Role of Instruction Templates in Multimodal Language Model Evaluation and Training
Dec 11, 2024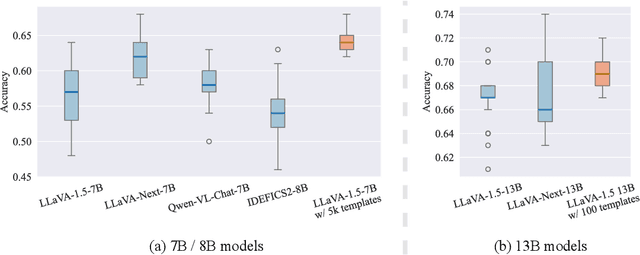
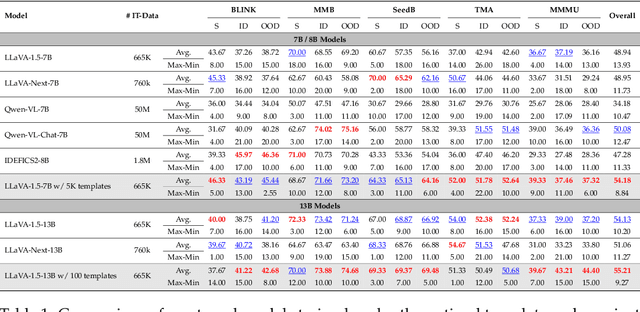

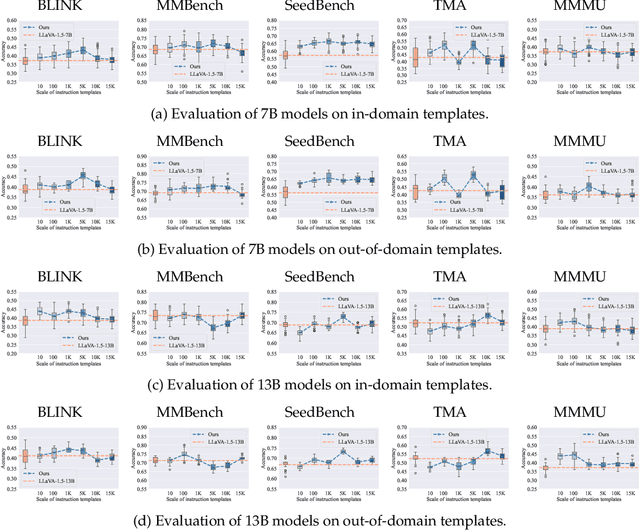
Current multimodal language models (MLMs) evaluation and training approaches overlook the influence of instruction format, presenting an elephant-in-the-room problem. Previous research deals with this problem by manually crafting instructions, failing to yield significant insights due to limitations in diversity and scalability. In this work, we propose a programmatic instruction template generator capable of producing over 39B unique template combinations by filling randomly sampled positional synonyms into weighted sampled meta templates, enabling us to comprehensively examine the MLM's performance across diverse instruction templates. Our experiments across eight common MLMs on five benchmark datasets reveal that MLMs have high template sensitivities with at most 29% performance gaps between different templates. We further augment the instruction tuning dataset of LLaVA-1.5 with our template generator and perform instruction tuning on LLaVA-1.5-7B and LLaVA-1.5-13B. Models tuned on our augmented dataset achieve the best overall performance when compared with the same scale MLMs tuned on at most 75 times the scale of our augmented dataset, highlighting the importance of instruction templates in MLM training. The code is available at https://github.com/shijian2001/TemplateMatters .
AI-Driven Day-to-Day Route Choice
Dec 04, 2024



Understanding travelers' route choices can help policymakers devise optimal operational and planning strategies for both normal and abnormal circumstances. However, existing choice modeling methods often rely on predefined assumptions and struggle to capture the dynamic and adaptive nature of travel behavior. Recently, Large Language Models (LLMs) have emerged as a promising alternative, demonstrating remarkable ability to replicate human-like behaviors across various fields. Despite this potential, their capacity to accurately simulate human route choice behavior in transportation contexts remains doubtful. To satisfy this curiosity, this paper investigates the potential of LLMs for route choice modeling by introducing an LLM-empowered agent, "LLMTraveler." This agent integrates an LLM as its core, equipped with a memory system that learns from past experiences and makes decisions by balancing retrieved data and personality traits. The study systematically evaluates the LLMTraveler's ability to replicate human-like decision-making through two stages: (1) analyzing its route-switching behavior in single origin-destination (OD) pair congestion game scenarios, where it demonstrates patterns align with laboratory data but are not fully explained by traditional models, and (2) testing its capacity to model day-to-day (DTD) adaptive learning behaviors on the Ortuzar and Willumsen (OW) network, producing results comparable to Multinomial Logit (MNL) and Reinforcement Learning (RL) models. These experiments demonstrate that the framework can partially replicate human-like decision-making in route choice while providing natural language explanations for its decisions. This capability offers valuable insights for transportation policymaking, such as simulating traveler responses to new policies or changes in the network.
POPDG: Popular 3D Dance Generation with PopDanceSet
May 06, 2024Generating dances that are both lifelike and well-aligned with music continues to be a challenging task in the cross-modal domain. This paper introduces PopDanceSet, the first dataset tailored to the preferences of young audiences, enabling the generation of aesthetically oriented dances. And it surpasses the AIST++ dataset in music genre diversity and the intricacy and depth of dance movements. Moreover, the proposed POPDG model within the iDDPM framework enhances dance diversity and, through the Space Augmentation Algorithm, strengthens spatial physical connections between human body joints, ensuring that increased diversity does not compromise generation quality. A streamlined Alignment Module is also designed to improve the temporal alignment between dance and music. Extensive experiments show that POPDG achieves SOTA results on two datasets. Furthermore, the paper also expands on current evaluation metrics. The dataset and code are available at https://github.com/Luke-Luo1/POPDG.
Disentangled Diffusion-Based 3D Human Pose Estimation with Hierarchical Spatial and Temporal Denoiser
Mar 07, 2024



Recently, diffusion-based methods for monocular 3D human pose estimation have achieved state-of-the-art (SOTA) performance by directly regressing the 3D joint coordinates from the 2D pose sequence. Although some methods decompose the task into bone length and bone direction prediction based on the human anatomical skeleton to explicitly incorporate more human body prior constraints, the performance of these methods is significantly lower than that of the SOTA diffusion-based methods. This can be attributed to the tree structure of the human skeleton. Direct application of the disentangled method could amplify the accumulation of hierarchical errors, propagating through each hierarchy. Meanwhile, the hierarchical information has not been fully explored by the previous methods. To address these problems, a Disentangled Diffusion-based 3D Human Pose Estimation method with Hierarchical Spatial and Temporal Denoiser is proposed, termed DDHPose. In our approach: (1) We disentangle the 3D pose and diffuse the bone length and bone direction during the forward process of the diffusion model to effectively model the human pose prior. A disentanglement loss is proposed to supervise diffusion model learning. (2) For the reverse process, we propose Hierarchical Spatial and Temporal Denoiser (HSTDenoiser) to improve the hierarchical modeling of each joint. Our HSTDenoiser comprises two components: the Hierarchical-Related Spatial Transformer (HRST) and the Hierarchical-Related Temporal Transformer (HRTT). HRST exploits joint spatial information and the influence of the parent joint on each joint for spatial modeling, while HRTT utilizes information from both the joint and its hierarchical adjacent joints to explore the hierarchical temporal correlations among joints.
More than Correlation: Do Large Language Models Learn Causal Representations of Space?
Dec 26, 2023Recent work found high mutual information between the learned representations of large language models (LLMs) and the geospatial property of its input, hinting an emergent internal model of space. However, whether this internal space model has any causal effects on the LLMs' behaviors was not answered by that work, led to criticism of these findings as mere statistical correlation. Our study focused on uncovering the causality of the spatial representations in LLMs. In particular, we discovered the potential spatial representations in DeBERTa, GPT-Neo using representational similarity analysis and linear and non-linear probing. Our casual intervention experiments showed that the spatial representations influenced the model's performance on next word prediction and a downstream task that relies on geospatial information. Our experiments suggested that the LLMs learn and use an internal model of space in solving geospatial related tasks.
On the diminishing return of labeling clinical reports
Oct 27, 2020
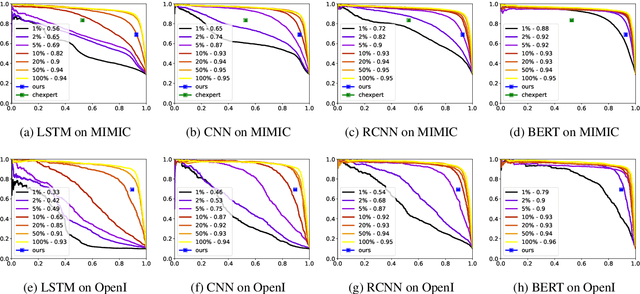


Ample evidence suggests that better machine learning models may be steadily obtained by training on increasingly larger datasets on natural language processing (NLP) problems from non-medical domains. Whether the same holds true for medical NLP has by far not been thoroughly investigated. This work shows that this is indeed not always the case. We reveal the somehow counter-intuitive observation that performant medical NLP models may be obtained with small amount of labeled data, quite the opposite to the common belief, most likely due to the domain specificity of the problem. We show quantitatively the effect of training data size on a fixed test set composed of two of the largest public chest x-ray radiology report datasets on the task of abnormality classification. The trained models not only make use of the training data efficiently, but also outperform the current state-of-the-art rule-based systems by a significant margin.
Learning to estimate label uncertainty for automatic radiology report parsing
Oct 01, 2019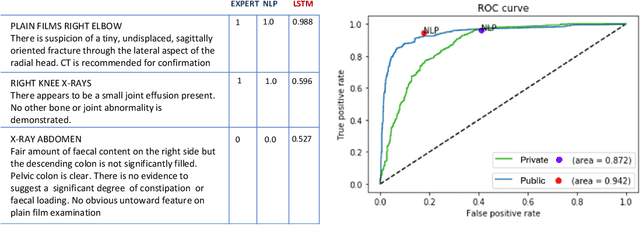
Bootstrapping labels from radiology reports has become the scalable alternative to provide inexpensive ground truth for medical imaging. Because of the domain specific nature, state-of-the-art report labeling tools are predominantly rule-based. These tools, however, typically yield a binary 0 or 1 prediction that indicates the presence or absence of abnormalities. These hard targets are then used as ground truth to train image models in the downstream, forcing models to express high degree of certainty even on cases where specificity is low. This could negatively impact the statistical efficiency of image models. We address such an issue by training a Bidirectional Long-Short Term Memory Network to augment heuristic-based discrete labels of X-ray reports from all body regions and achieve performance comparable or better than domain-specific NLP, but with additional uncertainty estimates which enable finer downstream image model training.
Caveats in Generating Medical Imaging Labels from Radiology Reports
May 06, 2019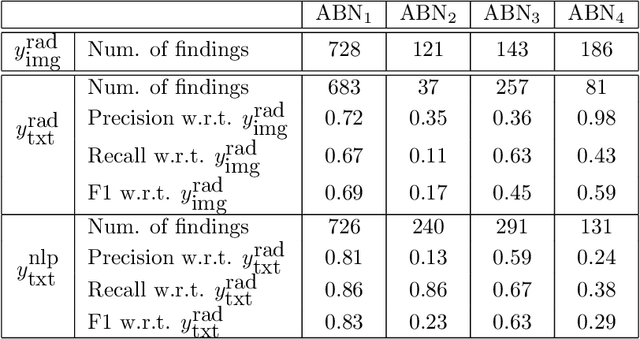
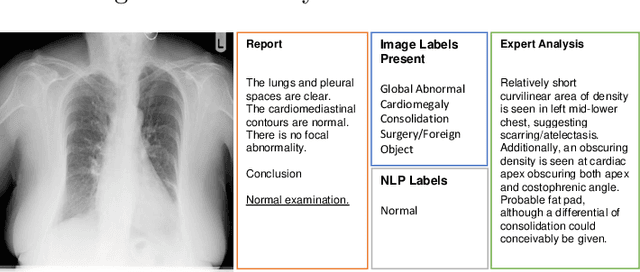
Acquiring high-quality annotations in medical imaging is usually a costly process. Automatic label extraction with natural language processing (NLP) has emerged as a promising workaround to bypass the need of expert annotation. Despite the convenience, the limitation of such an approximation has not been carefully examined and is not well understood. With a challenging set of 1,000 chest X-ray studies and their corresponding radiology reports, we show that there exists a surprisingly large discrepancy between what radiologists visually perceive and what they clinically report. Furthermore, with inherently flawed report as ground truth, the state-of-the-art medical NLP fails to produce high-fidelity labels.
A Strong Baseline for Domain Adaptation and Generalization in Medical Imaging
Apr 02, 2019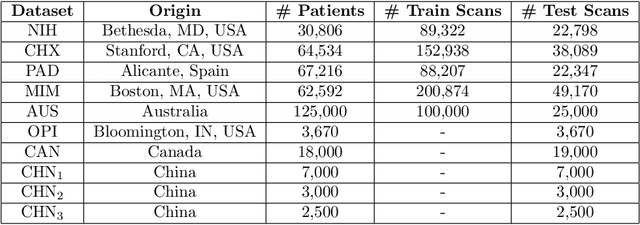
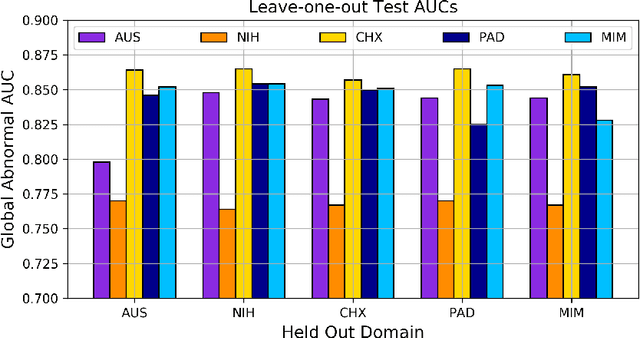
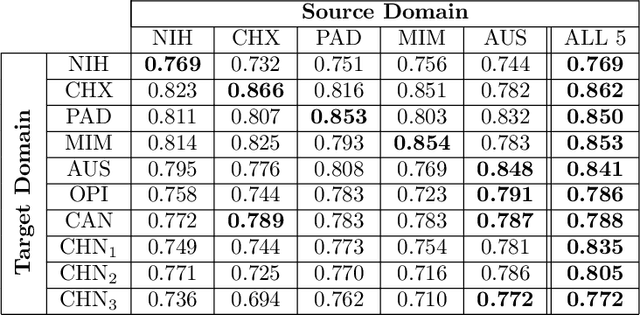
This work provides a strong baseline for the problem of multi-source multi-target domain adaptation and generalization in medical imaging. Using a diverse collection of ten chest X-ray datasets, we empirically demonstrate the benefits of training medical imaging deep learning models on varied patient populations for generalization to out-of-sample domains.