 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSubspace Fusion Sensing for Cooperative ISAC
Mar 09, 2026This paper proposes a subspace fusion sensing algorithm for cooperative integrated sensing and communication. First, we stack the received signals from access points (APs) into a third-order tensor and construct the equivalent virtual antenna (EVA) array via tensor unfolding. Then, a data association-free subspace-based fusion sensing algorithm is developed utilizing the EVA arrays from distributed APs. A derivation of Cramer-Rao lower bound (CRLB) is also presented. Finally, simulation results validate the effectiveness of the proposed algorithm compared to traditional techniques.
ESCT3D: Efficient and Selectively Controllable Text-Driven 3D Content Generation with Gaussian Splatting
Apr 14, 2025In recent years, significant advancements have been made in text-driven 3D content generation. However, several challenges remain. In practical applications, users often provide extremely simple text inputs while expecting high-quality 3D content. Generating optimal results from such minimal text is a difficult task due to the strong dependency of text-to-3D models on the quality of input prompts. Moreover, the generation process exhibits high variability, making it difficult to control. Consequently, multiple iterations are typically required to produce content that meets user expectations, reducing generation efficiency. To address this issue, we propose GPT-4V for self-optimization, which significantly enhances the efficiency of generating satisfactory content in a single attempt. Furthermore, the controllability of text-to-3D generation methods has not been fully explored. Our approach enables users to not only provide textual descriptions but also specify additional conditions, such as style, edges, scribbles, poses, or combinations of multiple conditions, allowing for more precise control over the generated 3D content. Additionally, during training, we effectively integrate multi-view information, including multi-view depth, masks, features, and images, to address the common Janus problem in 3D content generation. Extensive experiments demonstrate that our method achieves robust generalization, facilitating the efficient and controllable generation of high-quality 3D content.
Resource Allocation for Channel Estimation in Reconfigurable Intelligent Surface-Aided Multi-Cell Networks
Feb 09, 2024Reconfigurable intelligent surface (RIS) is a promising solution to deal with the blockage-sensitivity of millimeter wave band and reduce the high energy consumption caused by network densification. However, deploying large scale RISs may not bring expected performance gain due to significant channel estimation overhead and non-negligible reflected interference. In this paper, we derive the analytical expressions of the coverage probability, area spectrum efficiency (ASE) and energy efficiency (EE) of a downlink RIS-aided multi-cell network. In order to optimize the network performance, we investigate the conditions for the optimal number of training symbols of each antenna-to-antenna and antenna-to-element path (referred to as the optimal unit training overhead) in channel estimation. Our study shows that: 1) RIS deployment is not `the more, the better', only when blockage objects are dense should one deploy more RISs; 2) the coverage probability is maximized when the unit training overhead is designed as large as possible; 3) however, the ASE-and-EE-optimal unit training overhead exists. It is a monotonically increasing function of the frame length and a monotonically decreasing function of the average signal-to-noise-ratio (in the high signal-to-noise-ratio region). Additionally, the optimal unit training overhead is smaller when communication ends deploy particularly few or many antennas.
FTGAN: A Fully-trained Generative Adversarial Networks for Text to Face Generation
Apr 11, 2019
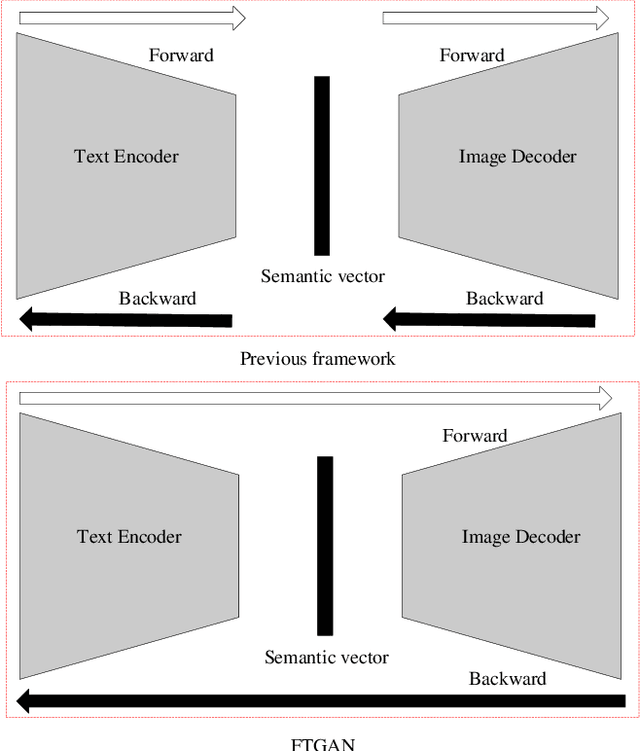
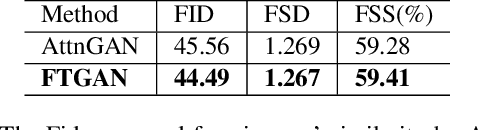
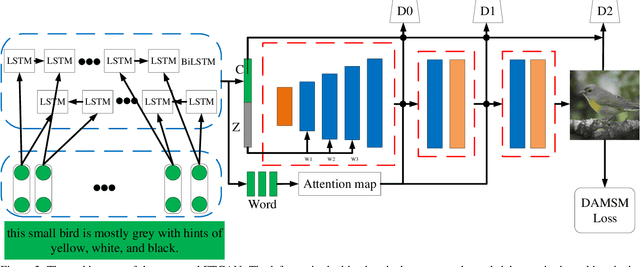
As a sub-domain of text-to-image synthesis, text-to-face generation has huge potentials in public safety domain. With lack of dataset, there are almost no related research focusing on text-to-face synthesis. In this paper, we propose a fully-trained Generative Adversarial Network (FTGAN) that trains the text encoder and image decoder at the same time for fine-grained text-to-face generation. With a novel fully-trained generative network, FTGAN can synthesize higher-quality images and urge the outputs of the FTGAN are more relevant to the input sentences. In addition, we build a dataset called SCU-Text2face for text-to-face synthesis. Through extensive experiments, the FTGAN shows its superiority in boosting both generated images' quality and similarity to the input descriptions. The proposed FTGAN outperforms the previous state of the art, boosting the best reported Inception Score to 4.63 on the CUB dataset. On SCU-text2face, the face images generated by our proposed FTGAN just based on the input descriptions is of average 59% similarity to the ground-truth, which set a baseline for text-to-face synthesis.