 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistically controllable microstructure reconstruction framework for heterogeneous materials using sliced-Wasserstein metric and neural networks
Nov 18, 2025Heterogeneous porous materials play a crucial role in various engineering systems. Microstructure characterization and reconstruction provide effective means for modeling these materials, which are critical for conducting physical property simulations, structure-property linkage studies, and enhancing their performance across different applications. To achieve superior controllability and applicability with small sample sizes, we propose a statistically controllable microstructure reconstruction framework that integrates neural networks with sliced-Wasserstein metric. Specifically, our approach leverages local pattern distribution for microstructure characterization and employs a controlled sampling strategy to generate target distributions that satisfy given conditional parameters. A neural network-based model establishes the mapping from the input distribution to the target local pattern distribution, enabling microstructure reconstruction. Combinations of sliced-Wasserstein metric and gradient optimization techniques minimize the distance between these distributions, leading to a stable and reliable model. Our method can perform stochastic and controllable reconstruction tasks even with small sample sizes. Additionally, it can generate large-size (e.g. 512 and 1024) 3D microstructures using a chunking strategy. By introducing spatial location masks, our method excels at generating spatially heterogeneous and complex microstructures. We conducted experiments on stochastic reconstruction, controllable reconstruction, heterogeneous reconstruction, and large-size microstructure reconstruction across various materials. Comparative analysis through visualization, statistical measures, and physical property simulations demonstrates the effectiveness, providing new insights and possibilities for research on structure-property linkage and material inverse design.
Perception- and Fidelity-aware Reduced-Reference Super-Resolution Image Quality Assessment
May 15, 2024



With the advent of image super-resolution (SR) algorithms, how to evaluate the quality of generated SR images has become an urgent task. Although full-reference methods perform well in SR image quality assessment (SR-IQA), their reliance on high-resolution (HR) images limits their practical applicability. Leveraging available reconstruction information as much as possible for SR-IQA, such as low-resolution (LR) images and the scale factors, is a promising way to enhance assessment performance for SR-IQA without HR for reference. In this letter, we attempt to evaluate the perceptual quality and reconstruction fidelity of SR images considering LR images and scale factors. Specifically, we propose a novel dual-branch reduced-reference SR-IQA network, \ie, Perception- and Fidelity-aware SR-IQA (PFIQA). The perception-aware branch evaluates the perceptual quality of SR images by leveraging the merits of global modeling of Vision Transformer (ViT) and local relation of ResNet, and incorporating the scale factor to enable comprehensive visual perception. Meanwhile, the fidelity-aware branch assesses the reconstruction fidelity between LR and SR images through their visual perception. The combination of the two branches substantially aligns with the human visual system, enabling a comprehensive SR image evaluation. Experimental results indicate that our PFIQA outperforms current state-of-the-art models across three widely-used SR-IQA benchmarks. Notably, PFIQA excels in assessing the quality of real-world SR images.
Efficient Meta-Learning Enabled Lightweight Multiscale Few-Shot Object Detection in Remote Sensing Images
Apr 29, 2024



Presently, the task of few-shot object detection (FSOD) in remote sensing images (RSIs) has become a focal point of attention. Numerous few-shot detectors, particularly those based on two-stage detectors, face challenges when dealing with the multiscale complexities inherent in RSIs. Moreover, these detectors present impractical characteristics in real-world applications, mainly due to their unwieldy model parameters when handling large amount of data. In contrast, we recognize the advantages of one-stage detectors, including high detection speed and a global receptive field. Consequently, we choose the YOLOv7 one-stage detector as a baseline and subject it to a novel meta-learning training framework. This transformation allows the detector to adeptly address FSOD tasks while capitalizing on its inherent advantage of lightweight. Additionally, we thoroughly investigate the samples generated by the meta-learning strategy and introduce a novel meta-sampling approach to retain samples produced by our designed meta-detection head. Coupled with our devised meta-cross loss, we deliberately utilize ``negative samples" that are often overlooked to extract valuable knowledge from them. This approach serves to enhance detection accuracy and efficiently refine the overall meta-learning strategy. To validate the effectiveness of our proposed detector, we conducted performance comparisons with current state-of-the-art detectors using the DIOR and NWPU VHR-10.v2 datasets, yielding satisfactory results.
Attention-based 3D CNN with Multi-layer Features for Alzheimer's Disease Diagnosis using Brain Images
Aug 10, 2023Structural MRI and PET imaging play an important role in the diagnosis of Alzheimer's disease (AD), showing the morphological changes and glucose metabolism changes in the brain respectively. The manifestations in the brain image of some cognitive impairment patients are relatively inconspicuous, for example, it still has difficulties in achieving accurate diagnosis through sMRI in clinical practice. With the emergence of deep learning, convolutional neural network (CNN) has become a valuable method in AD-aided diagnosis, but some CNN methods cannot effectively learn the features of brain image, making the diagnosis of AD still presents some challenges. In this work, we propose an end-to-end 3D CNN framework for AD diagnosis based on ResNet, which integrates multi-layer features obtained under the effect of the attention mechanism to better capture subtle differences in brain images. The attention maps showed our model can focus on key brain regions related to the disease diagnosis. Our method was verified in ablation experiments with two modality images on 792 subjects from the ADNI database, where AD diagnostic accuracies of 89.71% and 91.18% were achieved based on sMRI and PET respectively, and also outperformed some state-of-the-art methods.
* 4 pages, 4 figures
Multi-modal Graph Neural Network for Early Diagnosis of Alzheimer's Disease from sMRI and PET Scans
Jul 31, 2023



In recent years, deep learning models have been applied to neuroimaging data for early diagnosis of Alzheimer's disease (AD). Structural magnetic resonance imaging (sMRI) and positron emission tomography (PET) images provide structural and functional information about the brain, respectively. Combining these features leads to improved performance than using a single modality alone in building predictive models for AD diagnosis. However, current multi-modal approaches in deep learning, based on sMRI and PET, are mostly limited to convolutional neural networks, which do not facilitate integration of both image and phenotypic information of subjects. We propose to use graph neural networks (GNN) that are designed to deal with problems in non-Euclidean domains. In this study, we demonstrate how brain networks can be created from sMRI or PET images and be used in a population graph framework that can combine phenotypic information with imaging features of these brain networks. Then, we present a multi-modal GNN framework where each modality has its own branch of GNN and a technique is proposed to combine the multi-modal data at both the level of node vectors and adjacency matrices. Finally, we perform late fusion to combine the preliminary decisions made in each branch and produce a final prediction. As multi-modality data becomes available, multi-source and multi-modal is the trend of AD diagnosis. We conducted explorative experiments based on multi-modal imaging data combined with non-imaging phenotypic information for AD diagnosis and analyzed the impact of phenotypic information on diagnostic performance. Results from experiments demonstrated that our proposed multi-modal approach improves performance for AD diagnosis, and this study also provides technical reference and support the need for multivariate multi-modal diagnosis methods.
A fast and flexible algorithm for microstructure reconstruction combining simulated annealing and deep learning
Apr 25, 2023



The microstructure analyses of porous media have considerable research value for the study of macroscopic properties. As the premise of conducting these analyses, the accurate reconstruction of microstructure digital model is also an important component of the research. Computational reconstruction algorithms of microstructure have attracted much attention due to their low cost and excellent performance. However, it is still a challenge for computational reconstruction algorithms to achieve faster and more efficient reconstruction. The bottleneck lies in computational reconstruction algorithms, they are either too slow (traditional reconstruction algorithms) or not flexible to the training process (deep learning reconstruction algorithms). To address these limitations, we proposed a fast and flexible computational reconstruction algorithm, neural networks based on improved simulated annealing framework (ISAF-NN). The proposed algorithm is flexible and can complete training and reconstruction in a short time with only one two-dimensional image. By adjusting the size of input, it can also achieve reconstruction of arbitrary size. Finally, the proposed algorithm is experimentally performed on a variety of isotropic and anisotropic materials to verify the effectiveness and generalization.
Multiscale reconstruction of porous media based on multiple dictionaries learning
May 16, 2022



Digital modeling of the microstructure is important for studying the physical and transport properties of porous media. Multiscale modeling for porous media can accurately characterize macro-pores and micro-pores in a large-FoV (field of view) high-resolution three-dimensional pore structure model. This paper proposes a multiscale reconstruction algorithm based on multiple dictionaries learning, in which edge patterns and micro-pore patterns from homology high-resolution pore structure are introduced into low-resolution pore structure to build a fine multiscale pore structure model. The qualitative and quantitative comparisons of the experimental results show that the results of multiscale reconstruction are similar to the real high-resolution pore structure in terms of complex pore geometry and pore surface morphology. The geometric, topological and permeability properties of multiscale reconstruction results are almost identical to those of the real high-resolution pore structures. The experiments also demonstrate the proposal algorithm is capable of multiscale reconstruction without regard to the size of the input. This work provides an effective method for fine multiscale modeling of porous media.
Real-World Single Image Super-Resolution: A Brief Review
Mar 03, 2021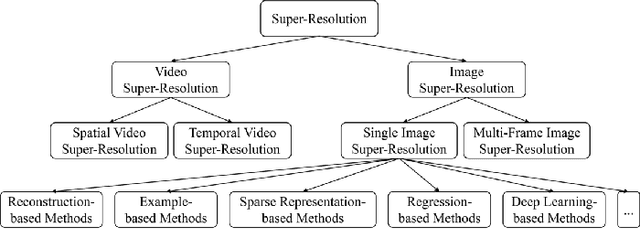

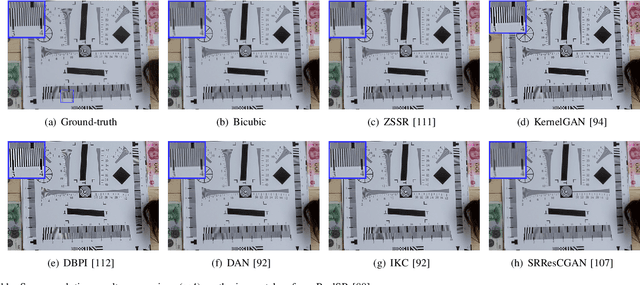
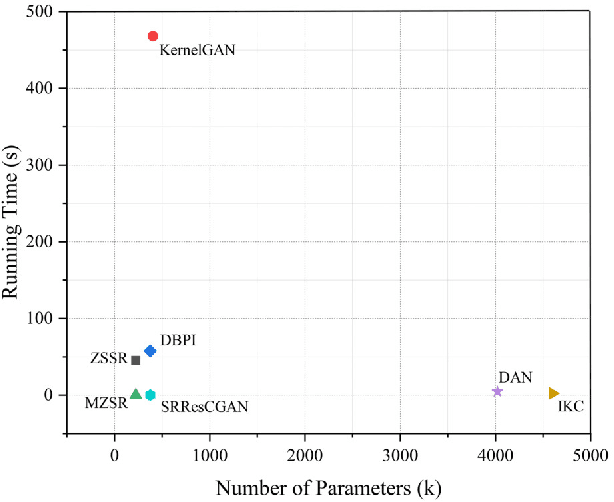
Single image super-resolution (SISR), which aims to reconstruct a high-resolution (HR) image from a low-resolution (LR) observation, has been an active research topic in the area of image processing in recent decades. Particularly, deep learning-based super-resolution (SR) approaches have drawn much attention and have greatly improved the reconstruction performance on synthetic data. Recent studies show that simulation results on synthetic data usually overestimate the capacity to super-resolve real-world images. In this context, more and more researchers devote themselves to develop SR approaches for realistic images. This article aims to make a comprehensive review on real-world single image super-resolution (RSISR). More specifically, this review covers the critical publically available datasets and assessment metrics for RSISR, and four major categories of RSISR methods, namely the degradation modeling-based RSISR, image pairs-based RSISR, domain translation-based RSISR, and self-learning-based RSISR. Comparisons are also made among representative RSISR methods on benchmark datasets, in terms of both reconstruction quality and computational efficiency. Besides, we discuss challenges and promising research topics on RSISR.
FTGAN: A Fully-trained Generative Adversarial Networks for Text to Face Generation
Apr 11, 2019
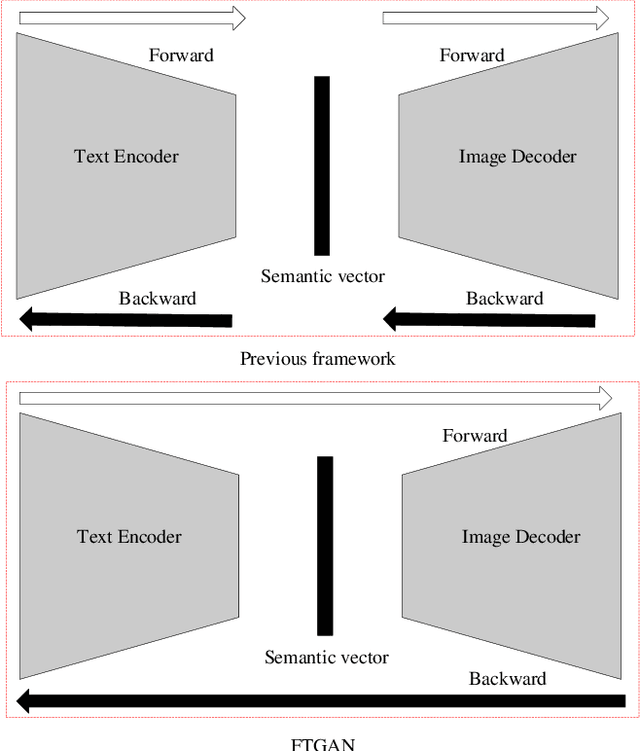
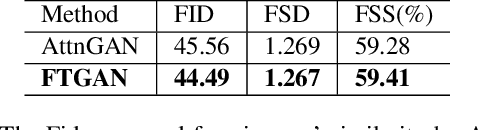
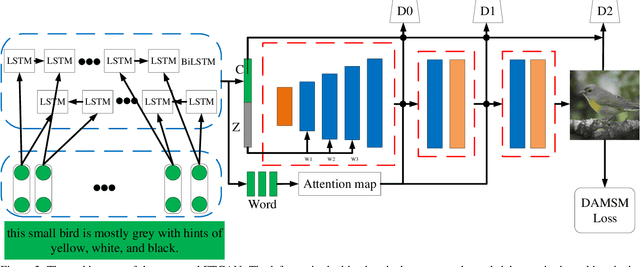
As a sub-domain of text-to-image synthesis, text-to-face generation has huge potentials in public safety domain. With lack of dataset, there are almost no related research focusing on text-to-face synthesis. In this paper, we propose a fully-trained Generative Adversarial Network (FTGAN) that trains the text encoder and image decoder at the same time for fine-grained text-to-face generation. With a novel fully-trained generative network, FTGAN can synthesize higher-quality images and urge the outputs of the FTGAN are more relevant to the input sentences. In addition, we build a dataset called SCU-Text2face for text-to-face synthesis. Through extensive experiments, the FTGAN shows its superiority in boosting both generated images' quality and similarity to the input descriptions. The proposed FTGAN outperforms the previous state of the art, boosting the best reported Inception Score to 4.63 on the CUB dataset. On SCU-text2face, the face images generated by our proposed FTGAN just based on the input descriptions is of average 59% similarity to the ground-truth, which set a baseline for text-to-face synthesis.
Accurate and Fast reconstruction of Porous Media from Extremely Limited Information Using Conditional Generative Adversarial Network
Apr 04, 2019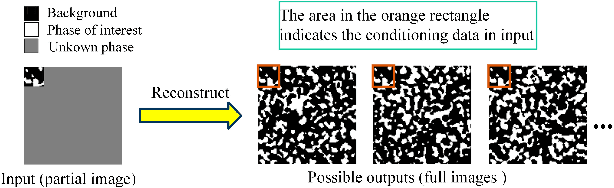
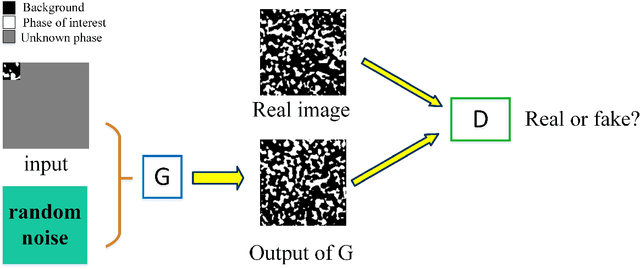
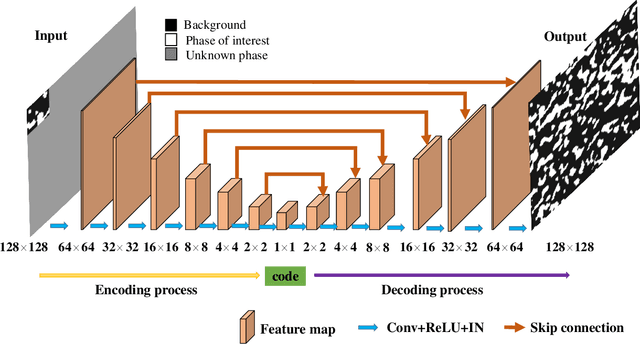
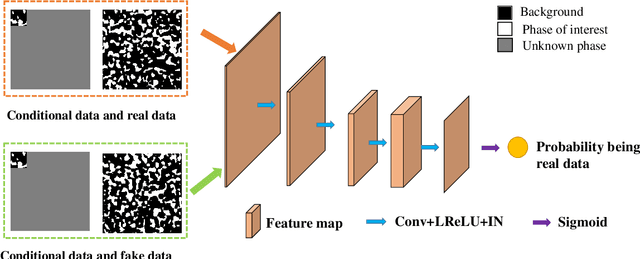
Porous media are ubiquitous in both nature and engineering applications, thus their modelling and understanding is of vital importance. In contrast to direct acquisition of three-dimensional (3D) images of such medium, obtaining its sub-region (s) like two-dimensional (2D) images or several small areas could be much feasible. Therefore, reconstructing whole images from the limited information is a primary technique in such cases. Specially, in practice the given data cannot generally be determined by users and may be incomplete or partially informed, thus making existing reconstruction methods inaccurate or even ineffective. To overcome this shortcoming, in this study we proposed a deep learning-based framework for reconstructing full image from its much smaller sub-area(s). Particularly, conditional generative adversarial network (CGAN) is utilized to learn the mapping between input (partial image) and output (full image). To preserve the reconstruction accuracy, two simple but effective objective functions are proposed and then coupled with the other two functions to jointly constrain the training procedure. Due to the inherent essence of this ill-posed problem, a Gaussian noise is introduced for producing reconstruction diversity, thus allowing for providing multiple candidate outputs. Extensively tested on a variety of porous materials and demonstrated by both visual inspection and quantitative comparison, the method is shown to be accurate, stable yet fast ($\sim0.08s$ for a $128 \times 128$ image reconstruction). We highlight that the proposed approach can be readily extended, such as incorporating any user-define conditional data and an arbitrary number of object functions into reconstruction, and being coupled with other reconstruction methods.