 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentNoiseBench: Benchmarking Robustness of Tool-Using LLM Agents Under Noisy Condition
Feb 11, 2026Recent advances in large language models have enabled LLM-based agents to achieve strong performance on a variety of benchmarks. However, their performance in real-world deployments often that observed on benchmark settings, especially in complex and imperfect environments. This discrepancy largely arises because prevailing training and evaluation paradigms are typically built on idealized assumptions, overlooking the inherent stochasticity and noise present in real-world interactions. To bridge this gap, we introduce AgentNoiseBench, a framework for systematically evaluating the robustness of agentic models under noisy environments. We first conduct an in-depth analysis of biases and uncertainties in real-world scenarios and categorize environmental noise into two primary types: user-noise and tool-noise. Building on this analysis, we develop an automated pipeline that injects controllable noise into existing agent-centric benchmarks while preserving task solvability. Leveraging this pipeline, we perform extensive evaluations across a wide range of models with diverse architectures and parameter scales. Our results reveal consistent performance variations under different noise conditions, highlighting the sensitivity of current agentic models to realistic environmental perturbations.
SafeMLRM: Demystifying Safety in Multi-modal Large Reasoning Models
Apr 09, 2025The rapid advancement of multi-modal large reasoning models (MLRMs) -- enhanced versions of multimodal language models (MLLMs) equipped with reasoning capabilities -- has revolutionized diverse applications. However, their safety implications remain underexplored. While prior work has exposed critical vulnerabilities in unimodal reasoning models, MLRMs introduce distinct risks from cross-modal reasoning pathways. This work presents the first systematic safety analysis of MLRMs through large-scale empirical studies comparing MLRMs with their base MLLMs. Our experiments reveal three critical findings: (1) The Reasoning Tax: Acquiring reasoning capabilities catastrophically degrades inherited safety alignment. MLRMs exhibit 37.44% higher jailbreaking success rates than base MLLMs under adversarial attacks. (2) Safety Blind Spots: While safety degradation is pervasive, certain scenarios (e.g., Illegal Activity) suffer 25 times higher attack rates -- far exceeding the average 3.4 times increase, revealing scenario-specific vulnerabilities with alarming cross-model and datasets consistency. (3) Emergent Self-Correction: Despite tight reasoning-answer safety coupling, MLRMs demonstrate nascent self-correction -- 16.9% of jailbroken reasoning steps are overridden by safe answers, hinting at intrinsic safeguards. These findings underscore the urgency of scenario-aware safety auditing and mechanisms to amplify MLRMs' self-correction potential. To catalyze research, we open-source OpenSafeMLRM, the first toolkit for MLRM safety evaluation, providing unified interface for mainstream models, datasets, and jailbreaking methods. Our work calls for immediate efforts to harden reasoning-augmented AI, ensuring its transformative potential aligns with ethical safeguards.
A Feature Matching Method Based on Multi-Level Refinement Strategy
Feb 25, 2024



Feature matching is a fundamental and crucial process in visual SLAM, and precision has always been a challenging issue in feature matching. In this paper, based on a multi-level fine matching strategy, we propose a new feature matching method called KTGP-ORB. This method utilizes the similarity of local appearance in the Hamming space generated by feature descriptors to establish initial correspondences. It combines the constraint of local image motion smoothness, uses the GMS algorithm to enhance the accuracy of initial matches, and finally employs the PROSAC algorithm to optimize matches, achieving precise matching based on global grayscale information in Euclidean space. Experimental results demonstrate that the KTGP-ORB method reduces the error by an average of 29.92% compared to the ORB algorithm in complex scenes with illumination variations and blur.
An Image Enhancement Method for Improving Small Intestinal Villi Clarity
Feb 25, 2024



This paper presents, for the first time, an image enhancement methodology designed to enhance the clarity of small intestinal villi in Wireless Capsule Endoscopy (WCE) images. This method first separates the low-frequency and high-frequency components of small intestinal villi images using guided filtering. Subsequently, an adaptive light gain factor is generated based on the low-frequency component, and an adaptive gradient gain factor is derived from the convolution results of the Laplacian operator in different regions of small intestinal villi images. The obtained light gain factor and gradient gain factor are then combined to enhance the high-frequency components. Finally, the enhanced high-frequency component is fused with the original image to achieve adaptive sharpening of the edges of WCE small intestinal villi images. The experiments affirm that, compared to established WCE image enhancement methods, our approach not only accentuates the edge details of WCE small intestine villi images but also skillfully suppresses noise amplification, thereby preventing the occurrence of edge overshooting.
An Error-Matching Exclusion Method for Accelerating Visual SLAM
Feb 25, 2024



In Visual SLAM, achieving accurate feature matching consumes a significant amount of time, severely impacting the real-time performance of the system. This paper proposes an accelerated method for Visual SLAM by integrating GMS (Grid-based Motion Statistics) with RANSAC (Random Sample Consensus) for the removal of mismatched features. The approach first utilizes the GMS algorithm to estimate the quantity of matched pairs within the neighborhood and ranks the matches based on their confidence. Subsequently, the Random Sample Consensus (RANSAC) algorithm is employed to further eliminate mismatched features. To address the time-consuming issue of randomly selecting all matched pairs, this method transforms it into the problem of prioritizing sample selection from high-confidence matches. This enables the iterative solution of the optimal model. Experimental results demonstrate that the proposed method achieves a comparable accuracy to the original GMS-RANSAC while reducing the average runtime by 24.13% on the KITTI, TUM desk, and TUM doll datasets.
A Robust Error-Resistant View Selection Method for 3D Reconstruction
Feb 25, 2024



To address the issue of increased triangulation uncertainty caused by selecting views with small camera baselines in Structure from Motion (SFM) view selection, this paper proposes a robust error-resistant view selection method. The method utilizes a triangulation-based computation to obtain an error-resistant model, which is then used to construct an error-resistant matrix. The sorting results of each row in the error-resistant matrix determine the candidate view set for each view. By traversing the candidate view sets of all views and completing the missing views based on the error-resistant matrix, the integrity of 3D reconstruction is ensured. Experimental comparisons between this method and the exhaustive method with the highest accuracy in the COLMAP program are conducted in terms of average reprojection error and absolute trajectory error in the reconstruction results. The proposed method demonstrates an average reduction of 29.40% in reprojection error accuracy and 5.07% in absolute trajectory error on the TUM dataset and DTU dataset.
A Highlight Removal Method for Capsule Endoscopy Images
Feb 25, 2024The images captured by Wireless Capsule Endoscopy (WCE) always exhibit specular reflections, and removing highlights while preserving the color and texture in the region remains a challenge. To address this issue, this paper proposes a highlight removal method for capsule endoscopy images. Firstly, the confidence and feature terms of the highlight region's edges are computed, where confidence is obtained by the ratio of known pixels in the RGB space's R channel to the B channel within a window centered on the highlight region's edge pixel, and feature terms are acquired by multiplying the gradient vector of the highlight region's edge pixel with the iso-intensity line. Subsequently, the confidence and feature terms are assigned different weights and summed to obtain the priority of all highlight region's edge pixels, and the pixel with the highest priority is identified. Then, the variance of the highlight region's edge pixels is used to adjust the size of the sample block window, and the best-matching block is searched in the known region based on the RGB color similarity and distance between the sample block and the window centered on the pixel with the highest priority. Finally, the pixels in the best-matching block are copied to the highest priority highlight removal region to achieve the goal of removing the highlight region. Experimental results demonstrate that the proposed method effectively removes highlights from WCE images, with a lower coefficient of variation in the highlight removal region compared to the Crinimisi algorithm and DeepGin method. Additionally, the color and texture in the highlight removal region are similar to those in the surrounding areas, and the texture is continuous.
Region Feature Descriptor Adapted to High Affine Transformations
Feb 25, 2024To address the issue of feature descriptors being ineffective in representing grayscale feature information when images undergo high affine transformations, leading to a rapid decline in feature matching accuracy, this paper proposes a region feature descriptor based on simulating affine transformations using classification. The proposed method initially categorizes images with different affine degrees to simulate affine transformations and generate a new set of images. Subsequently, it calculates neighborhood information for feature points on this new image set. Finally, the descriptor is generated by combining the grayscale histogram of the maximum stable extremal region to which the feature point belongs and the normalized position relative to the grayscale centroid of the feature point's region. Experimental results, comparing feature matching metrics under affine transformation scenarios, demonstrate that the proposed descriptor exhibits higher precision and robustness compared to existing classical descriptors. Additionally, it shows robustness when integrated with other descriptors.
Hierarchical Forgery Classifier On Multi-modality Face Forgery Clues
Dec 30, 2022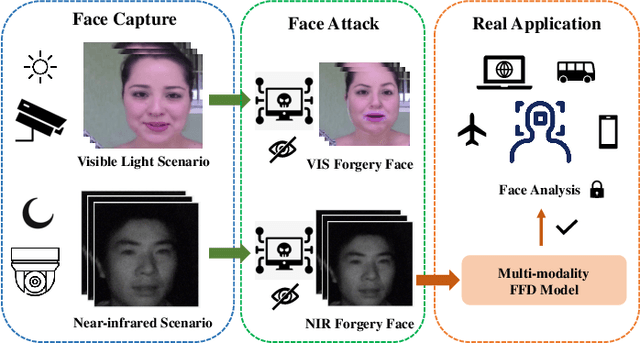
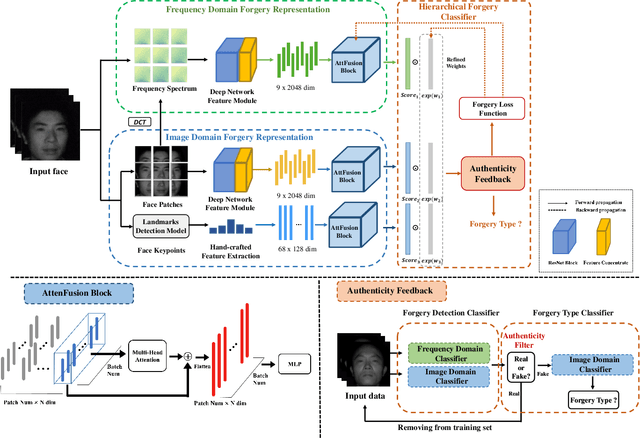


Face forgery detection plays an important role in personal privacy and social security. With the development of adversarial generative models, high-quality forgery images become more and more indistinguishable from real to humans. Existing methods always regard as forgery detection task as the common binary or multi-label classification, and ignore exploring diverse multi-modality forgery image types, e.g. visible light spectrum and near-infrared scenarios. In this paper, we propose a novel Hierarchical Forgery Classifier for Multi-modality Face Forgery Detection (HFC-MFFD), which could effectively learn robust patches-based hybrid domain representation to enhance forgery authentication in multiple-modality scenarios. The local spatial hybrid domain feature module is designed to explore strong discriminative forgery clues both in the image and frequency domain in local distinct face regions. Furthermore, the specific hierarchical face forgery classifier is proposed to alleviate the class imbalance problem and further boost detection performance. Experimental results on representative multi-modality face forgery datasets demonstrate the superior performance of the proposed HFC-MFFD compared with state-of-the-art algorithms. The source code and models are publicly available at https://github.com/EdWhites/HFC-MFFD.
Spatial-Temporal Frequency Forgery Clue for Video Forgery Detection in VIS and NIR Scenario
Jul 05, 2022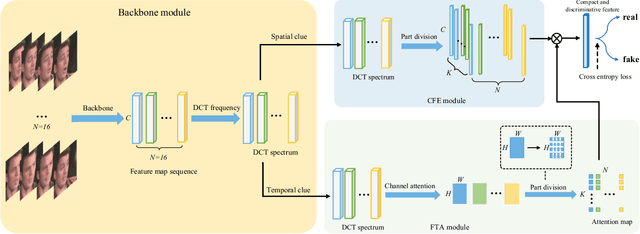
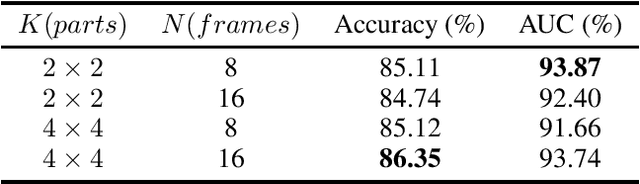
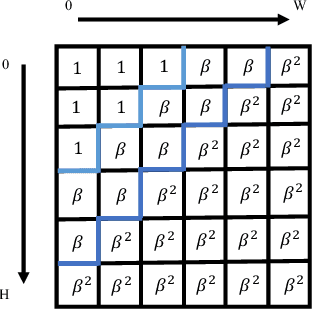
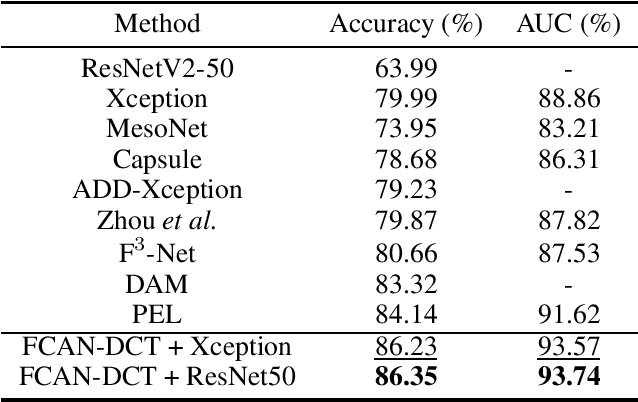
In recent years, with the rapid development of face editing and generation, more and more fake videos are circulating on social media, which has caused extreme public concerns. Existing face forgery detection methods based on frequency domain find that the GAN forged images have obvious grid-like visual artifacts in the frequency spectrum compared to the real images. But for synthesized videos, these methods only confine to single frame and pay little attention to the most discriminative part and temporal frequency clue among different frames. To take full advantage of the rich information in video sequences, this paper performs video forgery detection on both spatial and temporal frequency domains and proposes a Discrete Cosine Transform-based Forgery Clue Augmentation Network (FCAN-DCT) to achieve a more comprehensive spatial-temporal feature representation. FCAN-DCT consists of a backbone network and two branches: Compact Feature Extraction (CFE) module and Frequency Temporal Attention (FTA) module. We conduct thorough experimental assessments on two visible light (VIS) based datasets WildDeepfake and Celeb-DF (v2), and our self-built video forgery dataset DeepfakeNIR, which is the first video forgery dataset on near-infrared modality. The experimental results demonstrate the effectiveness of our method on detecting forgery videos in both VIS and NIR scenarios.