 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFSDETR: Frequency-Spatial Feature Enhancement for Small Object Detection
Apr 16, 2026Small object detection remains a significant challenge due to feature degradation from downsampling, mutual occlusion in dense clusters, and complex background interference. To address these issues, this paper proposes FSDETR, a frequency-spatial feature enhancement framework built upon the RT-DETR baseline. By establishing a collaborative modeling mechanism, the method effectively leverages complementary structural information. Specifically, a Spatial Hierarchical Attention Block (SHAB) captures both local details and global dependencies to strengthen semantic representation. Furthermore, to mitigate occlusion in dense scenes, the Deformable Attention-based Intra-scale Feature Interaction (DA-AIFI) focuses on informative regions via dynamic sampling. Finally, the Frequency-Spatial Feature Pyramid Network (FSFPN) integrates frequency filtering with spatial edge extraction via the Cross-domain Frequency-Spatial Block (CFSB) to preserve fine-grained details. Experimental results show that with only 14.7M parameters, FSDETR achieves 13.9% APS on VisDrone 2019 and 48.95% AP50 tiny on TinyPerson, showing strong performance on small-object benchmarks. The code and models are available at https://github.com/YT3DVision/FSDETR.
SEP-YOLO: Fourier-Domain Feature Representation for Transparent Object Instance Segmentation
Mar 03, 2026Transparent object instance segmentation presents significant challenges in computer vision, due to the inherent properties of transparent objects, including boundary blur, low contrast, and high dependence on background context. Existing methods often fail as they depend on strong appearance cues and clear boundaries. To address these limitations, we propose SEP-YOLO, a novel framework that integrates a dual-domain collaborative mechanism for transparent object instance segmentation. Our method incorporates a Frequency Domain Detail Enhancement Module, which separates and enhances weak highfrequency boundary components via learnable complex weights. We further design a multi-scale spatial refinement stream, which consists of a Content-Aware Alignment Neck and a Multi-scale Gated Refinement Block, to ensure precise feature alignment and boundary localization in deep semantic features. We also provide high-quality instance-level annotations for the Trans10K dataset, filling the critical data gap in transparent object instance segmentation. Extensive experiments on the Trans10K and GVD datasets show that SEP-YOLO achieves state-of-the-art (SOTA) performance.
MVGD-Net: A Novel Motion-aware Video Glass Surface Detection Network
Jan 20, 2026Glass surface ubiquitous in both daily life and professional environments presents a potential threat to vision-based systems, such as robot and drone navigation. To solve this challenge, most recent studies have shown significant interest in Video Glass Surface Detection (VGSD). We observe that objects in the reflection (or transmission) layer appear farther from the glass surfaces. Consequently, in video motion scenarios, the notable reflected (or transmitted) objects on the glass surface move slower than objects in non-glass regions within the same spatial plane, and this motion inconsistency can effectively reveal the presence of glass surfaces. Based on this observation, we propose a novel network, named MVGD-Net, for detecting glass surfaces in videos by leveraging motion inconsistency cues. Our MVGD-Net features three novel modules: the Cross-scale Multimodal Fusion Module (CMFM) that integrates extracted spatial features and estimated optical flow maps, the History Guided Attention Module (HGAM) and Temporal Cross Attention Module (TCAM), both of which further enhances temporal features. A Temporal-Spatial Decoder (TSD) is also introduced to fuse the spatial and temporal features for generating the glass region mask. Furthermore, for learning our network, we also propose a large-scale dataset, which comprises 312 diverse glass scenarios with a total of 19,268 frames. Extensive experiments demonstrate that our MVGD-Net outperforms relevant state-of-the-art methods.
A Lightweight Multi-Scale Attention Framework for Real-Time Spinal Endoscopic Instance Segmentation
Dec 26, 2025Real-time instance segmentation for spinal endoscopy is important for identifying and protecting critical anatomy during surgery, but it is difficult because of the narrow field of view, specular highlights, smoke/bleeding, unclear boundaries, and large scale changes. Deployment is also constrained by limited surgical hardware, so the model must balance accuracy and speed and remain stable under small-batch (even batch-1) training. We propose LMSF-A, a lightweight multi-scale attention framework co-designed across backbone, neck, and head. The backbone uses a C2f-Pro module that combines RepViT-style re-parameterized convolution (RVB) with efficient multi-scale attention (EMA), enabling multi-branch training while collapsing into a single fast path for inference. The neck improves cross-scale consistency and boundary detail using Scale-Sequence Feature Fusion (SSFF) and Triple Feature Encoding (TFE), which strengthens high-resolution features. The head adopts a Lightweight Multi-task Shared Head (LMSH) with shared convolutions and GroupNorm to reduce parameters and support batch-1 stability. We also release the clinically reviewed PELD dataset (61 patients, 610 images) with instance masks for adipose tissue, bone, ligamentum flavum, and nerve. Experiments show that LMSF-A is highly competitive (or even better than) in all evaluation metrics and much lighter than most instance segmentation methods requiring only 1.8M parameters and 8.8 GFLOPs, and it generalizes well to a public teeth benchmark. Code and dataset: https://github.com/hhwmortal/PELD-Instance-segmentation.
Knowledge Editing for Large Language Model with Knowledge Neuronal Ensemble
Dec 30, 2024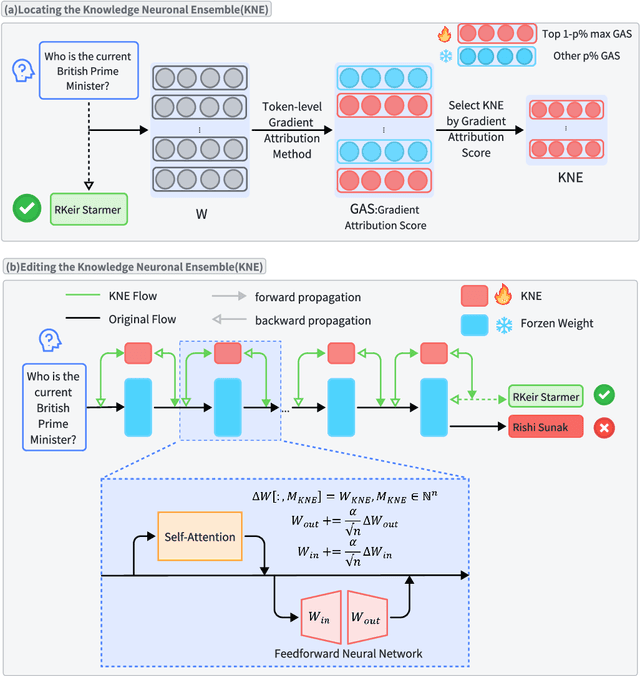
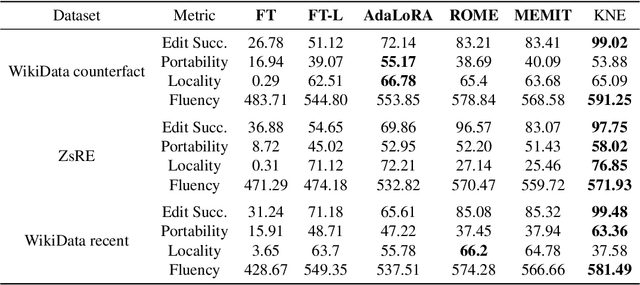
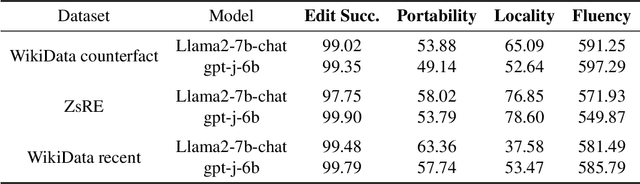
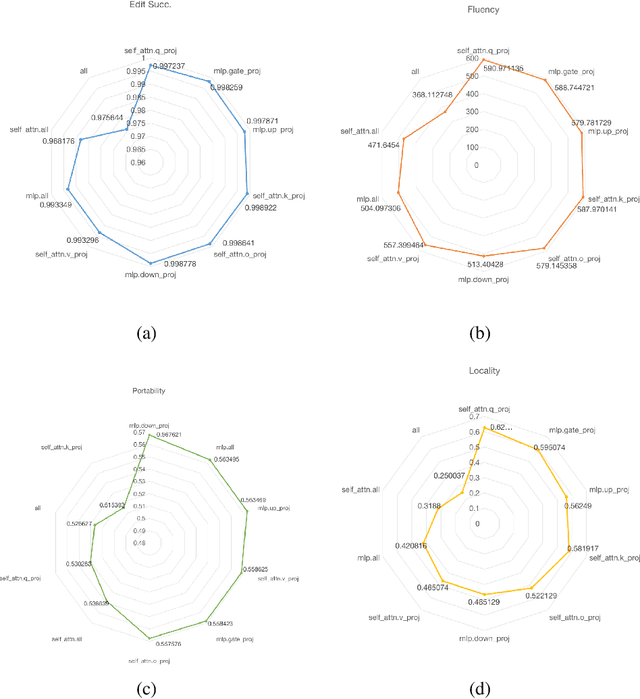
As real-world knowledge is constantly evolving, ensuring the timeliness and accuracy of a model's knowledge is crucial. This has made knowledge editing in large language models increasingly important. However, existing knowledge editing methods face several challenges, including parameter localization coupling, imprecise localization, and a lack of dynamic interaction across layers. In this paper, we propose a novel knowledge editing method called Knowledge Neuronal Ensemble (KNE). A knowledge neuronal ensemble represents a group of neurons encoding specific knowledge, thus mitigating the issue of frequent parameter modification caused by coupling in parameter localization. The KNE method enhances the precision and accuracy of parameter localization by computing gradient attribution scores for each parameter at each layer. During the editing process, only the gradients and losses associated with the knowledge neuronal ensemble are computed, with error backpropagation performed accordingly, ensuring dynamic interaction and collaborative updates among parameters. Experimental results on three widely used knowledge editing datasets show that the KNE method significantly improves the accuracy of knowledge editing and achieves, or even exceeds, the performance of the best baseline methods in portability and locality metrics.
k-HyperEdge Medoids for Clustering Ensemble
Dec 11, 2024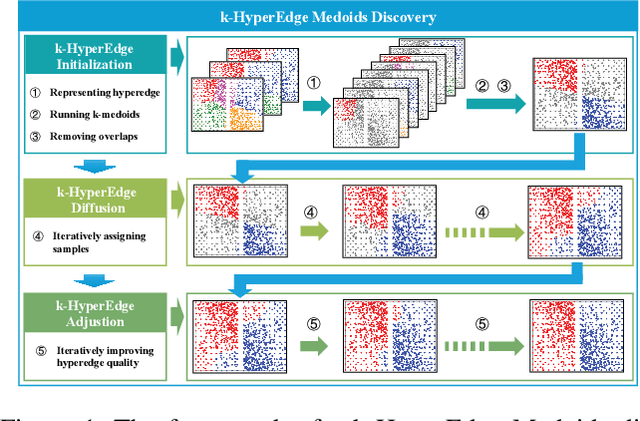
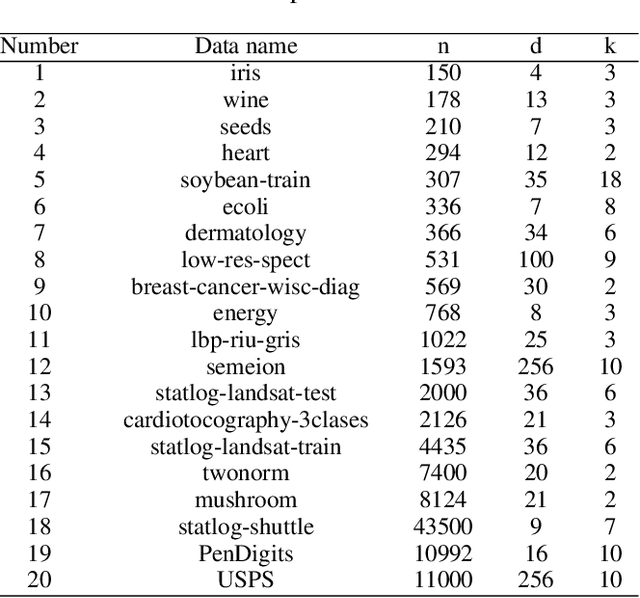
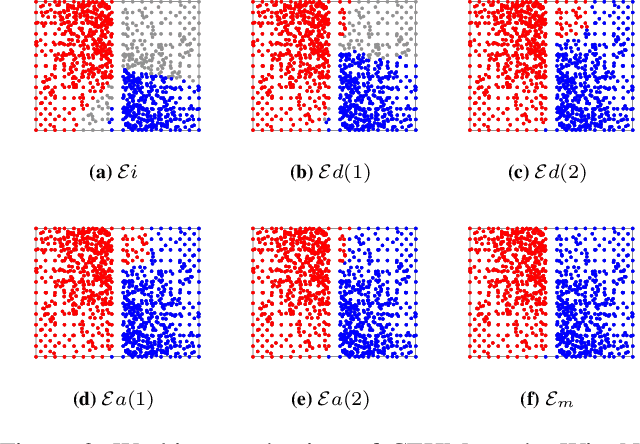
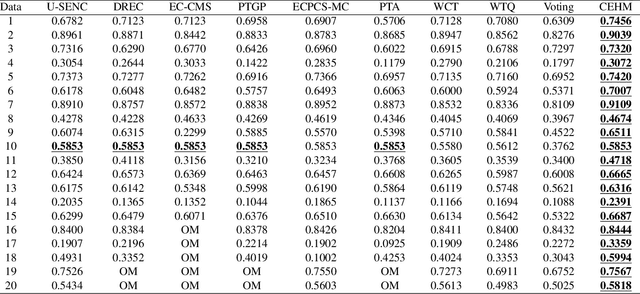
Clustering ensemble has been a popular research topic in data science due to its ability to improve the robustness of the single clustering method. Many clustering ensemble methods have been proposed, most of which can be categorized into clustering-view and sample-view methods. The clustering-view method is generally efficient, but it could be affected by the unreliability that existed in base clustering results. The sample-view method shows good performance, while the construction of the pairwise sample relation is time-consuming. In this paper, the clustering ensemble is formulated as a k-HyperEdge Medoids discovery problem and a clustering ensemble method based on k-HyperEdge Medoids that considers the characteristics of the above two types of clustering ensemble methods is proposed. In the method, a set of hyperedges is selected from the clustering view efficiently, then the hyperedges are diffused and adjusted from the sample view guided by a hyperedge loss function to construct an effective k-HyperEdge Medoid set. The loss function is mainly reduced by assigning samples to the hyperedge with the highest degree of belonging. Theoretical analyses show that the solution can approximate the optimal, the assignment method can gradually reduce the loss function, and the estimation of the belonging degree is statistically reasonable. Experiments on artificial data show the working mechanism of the proposed method. The convergence of the method is verified by experimental analysis of twenty data sets. The effectiveness and efficiency of the proposed method are also verified on these data, with nine representative clustering ensemble algorithms as reference.
MDeRainNet: An Efficient Neural Network for Rain Streak Removal from Macro-pixel Images
Jun 15, 2024



Since rainy weather always degrades image quality and poses significant challenges to most computer vision-based intelligent systems, image de-raining has been a hot research topic. Fortunately, in a rainy light field (LF) image, background obscured by rain streaks in one sub-view may be visible in the other sub-views, and implicit depth information and recorded 4D structural information may benefit rain streak detection and removal. However, existing LF image rain removal methods either do not fully exploit the global correlations of 4D LF data or only utilize partial sub-views, resulting in sub-optimal rain removal performance and no-equally good quality for all de-rained sub-views. In this paper, we propose an efficient network, called MDeRainNet, for rain streak removal from LF images. The proposed network adopts a multi-scale encoder-decoder architecture, which directly works on Macro-pixel images (MPIs) to improve the rain removal performance. To fully model the global correlation between the spatial and the angular information, we propose an Extended Spatial-Angular Interaction (ESAI) module to merge them, in which a simple and effective Transformer-based Spatial-Angular Interaction Attention (SAIA) block is also proposed for modeling long-range geometric correlations and making full use of the angular information. Furthermore, to improve the generalization performance of our network on real-world rainy scenes, we propose a novel semi-supervised learning framework for our MDeRainNet, which utilizes multi-level KL loss to bridge the domain gap between features of synthetic and real-world rain streaks and introduces colored-residue image guided contrastive regularization to reconstruct rain-free images. Extensive experiments conducted on synthetic and real-world LFIs demonstrate that our method outperforms the state-of-the-art methods both quantitatively and qualitatively.
Unified End-to-End V2X Cooperative Autonomous Driving
May 07, 2024

V2X cooperation, through the integration of sensor data from both vehicles and infrastructure, is considered a pivotal approach to advancing autonomous driving technology. Current research primarily focuses on enhancing perception accuracy, often overlooking the systematic improvement of accident prediction accuracy through end-to-end learning, leading to insufficient attention to the safety issues of autonomous driving. To address this challenge, this paper introduces the UniE2EV2X framework, a V2X-integrated end-to-end autonomous driving system that consolidates key driving modules within a unified network. The framework employs a deformable attention-based data fusion strategy, effectively facilitating cooperation between vehicles and infrastructure. The main advantages include: 1) significantly enhancing agents' perception and motion prediction capabilities, thereby improving the accuracy of accident predictions; 2) ensuring high reliability in the data fusion process; 3) superior end-to-end perception compared to modular approaches. Furthermore, We implement the UniE2EV2X framework on the challenging DeepAccident, a simulation dataset designed for V2X cooperative driving.
Distributed Robust Learning based Formation Control of Mobile Robots based on Bioinspired Neural Dynamics
Mar 23, 2024



This paper addresses the challenges of distributed formation control in multiple mobile robots, introducing a novel approach that enhances real-world practicability. We first introduce a distributed estimator using a variable structure and cascaded design technique, eliminating the need for derivative information to improve the real time performance. Then, a kinematic tracking control method is developed utilizing a bioinspired neural dynamic-based approach aimed at providing smooth control inputs and effectively resolving the speed jump issue. Furthermore, to address the challenges for robots operating with completely unknown dynamics and disturbances, a learning-based robust dynamic controller is developed. This controller provides real time parameter estimates while maintaining its robustness against disturbances. The overall stability of the proposed method is proved with rigorous mathematical analysis. At last, multiple comprehensive simulation studies have shown the advantages and effectiveness of the proposed method.
Region Feature Descriptor Adapted to High Affine Transformations
Feb 25, 2024To address the issue of feature descriptors being ineffective in representing grayscale feature information when images undergo high affine transformations, leading to a rapid decline in feature matching accuracy, this paper proposes a region feature descriptor based on simulating affine transformations using classification. The proposed method initially categorizes images with different affine degrees to simulate affine transformations and generate a new set of images. Subsequently, it calculates neighborhood information for feature points on this new image set. Finally, the descriptor is generated by combining the grayscale histogram of the maximum stable extremal region to which the feature point belongs and the normalized position relative to the grayscale centroid of the feature point's region. Experimental results, comparing feature matching metrics under affine transformation scenarios, demonstrate that the proposed descriptor exhibits higher precision and robustness compared to existing classical descriptors. Additionally, it shows robustness when integrated with other descriptors.