 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDivide and Conquer: Reliable Multi-View Evidential Learning for Deepfake Detection
Jun 01, 2026With the evolution of generative models, deepfakes have achieved near-perfect semantic realism, leaving forensic traces only in subtle structural anomalies. However, existing single-view paradigms often fail to generalize, as dominant semantic features overwhelm subtle artifact cues within entangled representations. This imbalance leads to overconfident yet brittle predictions -- a phenomenon we term the Semantic Masking Effect. To address this challenge, we propose a reliable framework called Divide-and-Conquer Multi-View Evidential Learning (DiCoME) for Deepfake Detection. In the "Divide" phase, we employ Geometric View Purification to decompose the entangled representation space through principled geometric projection. This process suppresses semantic interference within artifact-sensitive representations, forming the foundation for decorrelated yet complementary semantic and artifact views. In the "Conquer" phase, we leverage Uncertainty-Aware Evidential Learning to synthesize these distinct views. By explicitly modeling the "epistemic conflict" between semantic and artifact cues, this mechanism provides calibrated uncertainty estimates instead of forcing rigid deterministic decisions. Extensive experiments across multiple benchmarks demonstrate that our method consistently outperforms existing approaches in generalization performance, while providing reliable uncertainty estimation for trustworthy deepfake detection. Code is available at https://github.com/kxl0825/DiCoME.git.
AMARIS: A Memory-Augmented Rubric Improvement System for Rubric-Based Reinforcement Learning
May 18, 2026Rubric-based reward shaping is an effective method for fine-tuning LLMs via RL, where structured rubrics decompose standard outcome rewards into multiple dimensions to provide richer reward signals. Recent works make the rubrics adaptive based on local signals such as the rollouts from the current step or pairwise comparisons. However, these methods discard the diagnostics produced during evaluation after immediate use and prevent the long-term accumulation and strategic reuse of evaluation knowledge. This forces the system to re-derive evaluation principles from scratch, limits its ability to detect recurring suboptimal behaviors, and forfeits the curriculum-like progression that a persistent training history would naturally support. To address these limitations, we introduce AMARIS, which grounds rubric modifications in long-term training history. At each training step, AMARIS analyzes individual rollouts, aggregates findings into step-level summaries, retrieves relevant historical context from a persistent evaluation memory through both static (recent steps) and dynamic (semantically matched) retrieval, and updates rubrics based on these accumulated analyses. This procedure runs asynchronously alongside the normal RL loop with minimal overhead. Experiments across both closed and open-ended domains show that AMARIS consistently outperforms the baselines. Ablation studies show that static and dynamic memory retrieval contributes to the performance gain and their combination provides the strongest results with moderate retrieval budgets sufficient to provide most of the gain, and that the entire pipeline adds only ~5\% time overhead through asynchronous execution. These results show that persistent evaluation memory can transform rubric-based reward shaping from a stateless, per-step heuristic into an evidence-driven loop for RL training.
A Novel Low-Complexity Dual-Domain Expectation Propagation Detection Aided AFDM for Future Communications
Mar 31, 2026This paper presents a dual-domain low-complexity expectation propagation (EP) detection framework for affine frequency division multiplexing (AFDM) systems. By analyzing the structural properties of the effective channel matrices in both the time and affine frequency (AF) domains, our key observation is the domain-specific quasi-banded sparsity patterns, including AF-domain sparsity under frequency-selective channels and time-domain sparsity under doubly-selective channels. Based on these observations, we develop an AF-domain EP (EP-AF) detector for frequency-selective channels and a time-domain EP (EP-T) detector for doubly-selective channels, respectively. By performing iterative inference in the time domain using the Gaussian approximation, the proposed EP-T detector avoids inverting the dense channel matrix in the AF domain. Furthermore, the proposed EP-AF and EP-T detectors leverage the aforementioned quasi-banded sparsity of the AF domain and time domain channel matrices, respectively, to reduce the complexity of matrix inversion from cubic to linear order. Simulation results demonstrate that the proposed low-complexity EP-AF detector achieves nearly identical error rate performance to its conventional counterpart, while the proposed low-complexity EP-T detector offers an attractive trade-off between detection performance and complexity.
Towards Semantic-based Agent Communication Networks: Vision, Technologies, and Challenges
Mar 25, 2026The International Telecommunication Union (ITU) identifies "Artificial Intelligence (AI) and Communication" as one of six key usage scenarios for 6G. Agentic AI, characterized by its ca-pabilities in multi-modal environmental sensing, complex task coordination, and continuous self-optimization, is anticipated to drive the evolution toward agent-based communication net-works. Semantic communication (SemCom), in turn, has emerged as a transformative paradigm that offers task-oriented efficiency, enhanced reliability in complex environments, and dynamic adaptation in resource allocation. However, comprehensive reviews that trace their technologi-cal evolution in the contexts of agent communications remain scarce. Addressing this gap, this paper systematically explores the role of semantics in agent communication networks. We first propose a novel architecture for semantic-based agent communication networks, structured into three layers, four entities, and four stages. Three wireless agent network layers define the logical structure and organization of entity interactions: the intention extraction and understanding layer, the semantic encoding and processing layer, and the distributed autonomy and collabora-tion layer. Across these layers, four AI agent entities, namely embodied agents, communication agents, network agents, and application agents, coexist and perform distinct tasks. Furthermore, four operational stages of semantic-enhanced agentic AI systems, namely perception, memory, reasoning, and action, form a cognitive cycle guiding agent behavior. Based on the proposed architecture, we provide a comprehensive review of the state-of-the-art on how semantics en-hance agent communication networks. Finally, we identify key challenges and present potential solutions to offer directional guidance for future research in this emerging field.
Anticipatory Planning for Multimodal AI Agents
Mar 17, 2026Recent advances in multimodal agents have improved computer-use interaction and tool-usage, yet most existing systems remain reactive, optimizing actions in isolation without reasoning about future states or long-term goals. This limits planning coherence and prevents agents from reliably solving high-level, multi-step tasks. We introduce TraceR1, a two-stage reinforcement learning framework that explicitly trains anticipatory reasoning by forecasting short-horizon trajectories before execution. The first stage performs trajectory-level reinforcement learning with rewards that enforce global consistency across predicted action sequences. The second stage applies grounded reinforcement fine-tuning, using execution feedback from frozen tool agents to refine step-level accuracy and executability. TraceR1 is evaluated across seven benchmarks, covering online computer-use, offline computer-use benchmarks, and multimodal tool-use reasoning tasks, where it achieves substantial improvements in planning stability, execution robustness, and generalization over reactive and single-stage baselines. These results show that anticipatory trajectory reasoning is a key principle for building multimodal agents that can reason, plan, and act effectively in complex real-world environments.
InfinityStory: Unlimited Video Generation with World Consistency and Character-Aware Shot Transitions
Mar 04, 2026Generating long-form storytelling videos with consistent visual narratives remains a significant challenge in video synthesis. We present a novel framework, dataset, and a model that address three critical limitations: background consistency across shots, seamless multi-subject shot-to-shot transitions, and scalability to hour-long narratives. Our approach introduces a background-consistent generation pipeline that maintains visual coherence across scenes while preserving character identity and spatial relationships. We further propose a transition-aware video synthesis module that generates smooth shot transitions for complex scenarios involving multiple subjects entering or exiting frames, going beyond the single-subject limitations of prior work. To support this, we contribute with a synthetic dataset of 10,000 multi-subject transition sequences covering underrepresented dynamic scene compositions. On VBench, InfinityStory achieves the highest Background Consistency (88.94), highest Subject Consistency (82.11), and the best overall average rank (2.80), showing improved stability, smoother transitions, and better temporal coherence.
Proc3D: Procedural 3D Generation and Parametric Editing of 3D Shapes with Large Language Models
Jan 18, 2026Generating 3D models has traditionally been a complex task requiring specialized expertise. While recent advances in generative AI have sought to automate this process, existing methods produce non-editable representation, such as meshes or point clouds, limiting their adaptability for iterative design. In this paper, we introduce Proc3D, a system designed to generate editable 3D models while enabling real-time modifications. At its core, Proc3D introduces procedural compact graph (PCG), a graph representation of 3D models, that encodes the algorithmic rules and structures necessary for generating the model. This representation exposes key parameters, allowing intuitive manual adjustments via sliders and checkboxes, as well as real-time, automated modifications through natural language prompts using Large Language Models (LLMs). We demonstrate Proc3D's capabilities using two generative approaches: GPT-4o with in-context learning (ICL) and a fine-tuned LLAMA-3 model. Experimental results show that Proc3D outperforms existing methods in editing efficiency, achieving more than 400x speedup over conventional approaches that require full regeneration for each modification. Additionally, Proc3D improves ULIP scores by 28%, a metric that evaluates the alignment between generated 3D models and text prompts. By enabling text-aligned 3D model generation along with precise, real-time parametric edits, Proc3D facilitates highly accurate text-based image editing applications.
UDPNet: Unleashing Depth-based Priors for Robust Image Dehazing
Jan 11, 2026Image dehazing has witnessed significant advancements with the development of deep learning models. However, a few methods predominantly focus on single-modal RGB features, neglecting the inherent correlation between scene depth and haze distribution. Even those that jointly optimize depth estimation and image dehazing often suffer from suboptimal performance due to inadequate utilization of accurate depth information. In this paper, we present UDPNet, a general framework that leverages depth-based priors from large-scale pretrained depth estimation model DepthAnything V2 to boost existing image dehazing models. Specifically, our architecture comprises two typical components: the Depth-Guided Attention Module (DGAM) adaptively modulates features via lightweight depth-guided channel attention, and the Depth Prior Fusion Module (DPFM) enables hierarchical fusion of multi-scale depth map features by dual sliding-window multi-head cross-attention mechanism. These modules ensure both computational efficiency and effective integration of depth priors. Moreover, the intrinsic robustness of depth priors empowers the network to dynamically adapt to varying haze densities, illumination conditions, and domain gaps across synthetic and real-world data. Extensive experimental results demonstrate the effectiveness of our UDPNet, outperforming the state-of-the-art methods on popular dehazing datasets, such as 0.85 dB PSNR improvement on the SOTS dataset, 1.19 dB on the Haze4K dataset and 1.79 dB PSNR on the NHR dataset. Our proposed solution establishes a new benchmark for depth-aware dehazing across various scenarios. Pretrained models and codes will be released at our project https://github.com/Harbinzzy/UDPNet.
Atom: Efficient On-Device Video-Language Pipelines Through Modular Reuse
Dec 18, 2025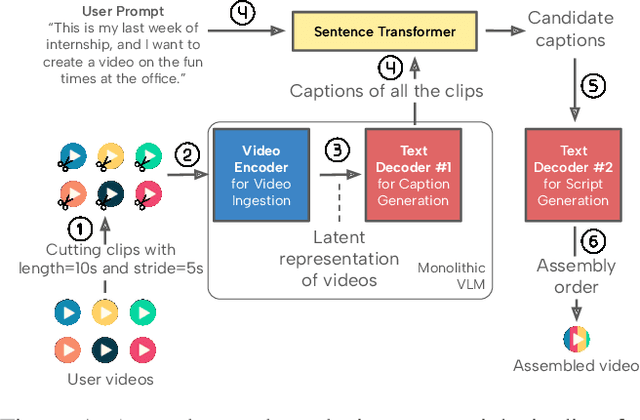
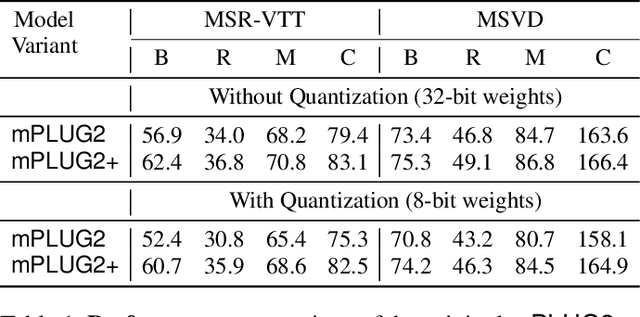
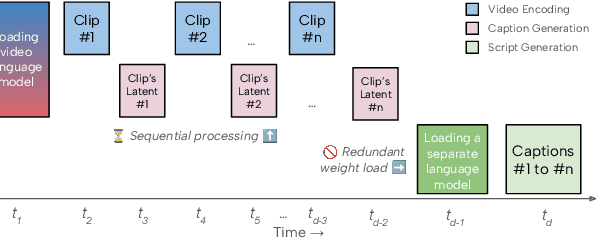
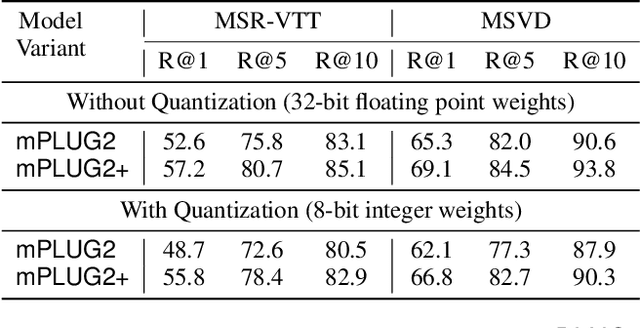
Recent advances in video-language models have enabled powerful applications like video retrieval, captioning, and assembly. However, executing such multi-stage pipelines efficiently on mobile devices remains challenging due to redundant model loads and fragmented execution. We introduce Atom, an on-device system that restructures video-language pipelines for fast and efficient execution. Atom decomposes a billion-parameter model into reusable modules, such as the visual encoder and language decoder, and reuses them across subtasks like captioning, reasoning, and indexing. This reuse-centric design eliminates repeated model loading and enables parallel execution, reducing end-to-end latency without sacrificing performance. On commodity smartphones, Atom achieves 27--33% faster execution compared to non-reuse baselines, with only marginal performance drop ($\leq$ 2.3 Recall@1 in retrieval, $\leq$ 1.5 CIDEr in captioning). These results position Atom as a practical, scalable approach for efficient video-language understanding on edge devices.
MedGEN-Bench: Contextually entangled benchmark for open-ended multimodal medical generation
Nov 18, 2025As Vision-Language Models (VLMs) increasingly gain traction in medical applications, clinicians are progressively expecting AI systems not only to generate textual diagnoses but also to produce corresponding medical images that integrate seamlessly into authentic clinical workflows. Despite the growing interest, existing medical visual benchmarks present notable limitations. They often rely on ambiguous queries that lack sufficient relevance to image content, oversimplify complex diagnostic reasoning into closed-ended shortcuts, and adopt a text-centric evaluation paradigm that overlooks the importance of image generation capabilities. To address these challenges, we introduce MedGEN-Bench, a comprehensive multimodal benchmark designed to advance medical AI research. MedGEN-Bench comprises 6,422 expert-validated image-text pairs spanning six imaging modalities, 16 clinical tasks, and 28 subtasks. It is structured into three distinct formats: Visual Question Answering, Image Editing, and Contextual Multimodal Generation. What sets MedGEN-Bench apart is its focus on contextually intertwined instructions that necessitate sophisticated cross-modal reasoning and open-ended generative outputs, moving beyond the constraints of multiple-choice formats. To evaluate the performance of existing systems, we employ a novel three-tier assessment framework that integrates pixel-level metrics, semantic text analysis, and expert-guided clinical relevance scoring. Using this framework, we systematically assess 10 compositional frameworks, 3 unified models, and 5 VLMs.