 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Policies: Reinforcing Spatial Reasoning in Language Models for Content-Aware Layout Design
Feb 14, 2026We introduce LaySPA, a reinforcement learning framework that equips large language models (LLMs) with explicit and interpretable spatial reasoning for content-aware graphic layout design. LaySPA addresses two key challenges: LLMs' limited spatial reasoning and the lack of opacity in design decision making. Instead of operating at the pixel level, we reformulate layout design as a policy learning problem over a structured textual spatial environment that explicitly encodes canvas geometry, element attributes, and inter-element relationships. LaySPA produces dual-level outputs comprising interpretable reasoning traces and structured layout specifications, enabling transparent and controllable design decision making. Layout design policy is optimized via a multi-objective spatial critique that decomposes layout quality into geometric validity, relational coherence, and aesthetic consistency, and is trained using relative group optimization to stabilize learning in open-ended design spaces. Experiments demonstrate that LaySPA improves structural validity and visual quality, outperforming larger proprietary LLMs and achieving performance comparable to specialized SOTA layout generators while requiring fewer annotated samples and reduced latency.
Proc3D: Procedural 3D Generation and Parametric Editing of 3D Shapes with Large Language Models
Jan 18, 2026Generating 3D models has traditionally been a complex task requiring specialized expertise. While recent advances in generative AI have sought to automate this process, existing methods produce non-editable representation, such as meshes or point clouds, limiting their adaptability for iterative design. In this paper, we introduce Proc3D, a system designed to generate editable 3D models while enabling real-time modifications. At its core, Proc3D introduces procedural compact graph (PCG), a graph representation of 3D models, that encodes the algorithmic rules and structures necessary for generating the model. This representation exposes key parameters, allowing intuitive manual adjustments via sliders and checkboxes, as well as real-time, automated modifications through natural language prompts using Large Language Models (LLMs). We demonstrate Proc3D's capabilities using two generative approaches: GPT-4o with in-context learning (ICL) and a fine-tuned LLAMA-3 model. Experimental results show that Proc3D outperforms existing methods in editing efficiency, achieving more than 400x speedup over conventional approaches that require full regeneration for each modification. Additionally, Proc3D improves ULIP scores by 28%, a metric that evaluates the alignment between generated 3D models and text prompts. By enabling text-aligned 3D model generation along with precise, real-time parametric edits, Proc3D facilitates highly accurate text-based image editing applications.
PRISM: Learning Design Knowledge from Data for Stylistic Design Improvement
Jan 16, 2026Graphic design often involves exploring different stylistic directions, which can be time-consuming for non-experts. We address this problem of stylistically improving designs based on natural language instructions. While VLMs have shown initial success in graphic design, their pretrained knowledge on styles is often too general and misaligned with specific domain data. For example, VLMs may associate minimalism with abstract designs, whereas designers emphasize shape and color choices. Our key insight is to leverage design data -- a collection of real-world designs that implicitly capture designer's principles -- to learn design knowledge and guide stylistic improvement. We propose PRISM (PRior-Informed Stylistic Modification) that constructs and applies a design knowledge base through three stages: (1) clustering high-variance designs to capture diversity within a style, (2) summarizing each cluster into actionable design knowledge, and (3) retrieving relevant knowledge during inference to enable style-aware improvement. Experiments on the Crello dataset show that PRISM achieves the highest average rank of 1.49 (closer to 1 is better) over baselines in style alignment. User studies further validate these results, showing that PRISM is consistently preferred by designers.
ScreenLLM: Stateful Screen Schema for Efficient Action Understanding and Prediction
Mar 26, 2025Graphical User Interface (GUI) agents are autonomous systems that interpret and generate actions, enabling intelligent user assistance and automation. Effective training of these agent presents unique challenges, such as sparsity in supervision signals, scalability for large datasets, and the need for nuanced user understanding. We propose stateful screen schema, an efficient representation of GUI interactions that captures key user actions and intentions over time. Building on this foundation, we introduce ScreenLLM, a set of multimodal large language models (MLLMs) tailored for advanced UI understanding and action prediction. Extensive experiments on both open-source and proprietary models show that ScreenLLM accurately models user behavior and predicts actions. Our work lays the foundation for scalable, robust, and intelligent GUI agents that enhance user interaction in diverse software environments.
X-Reflect: Cross-Reflection Prompting for Multimodal Recommendation
Aug 27, 2024

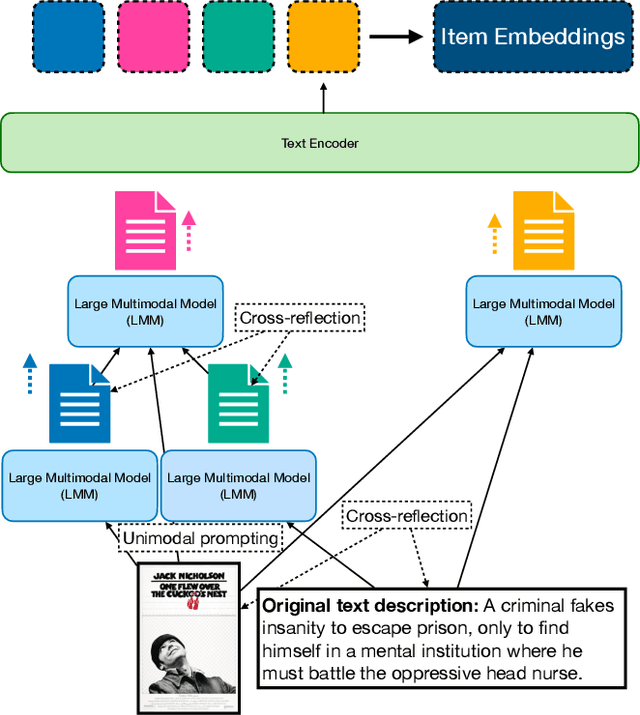
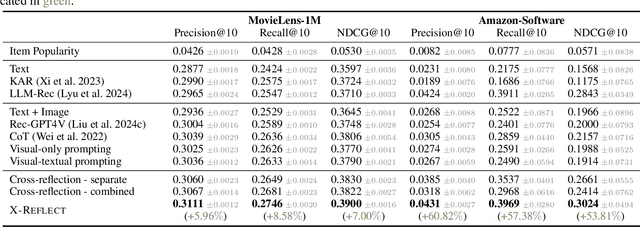
Large Language Models (LLMs) and Large Multimodal Models (LMMs) have been shown to enhance the effectiveness of enriching item descriptions, thereby improving the accuracy of recommendation systems. However, most existing approaches either rely on text-only prompting or employ basic multimodal strategies that do not fully exploit the complementary information available from both textual and visual modalities. This paper introduces a novel framework, Cross-Reflection Prompting, termed X-Reflect, designed to address these limitations by prompting LMMs to explicitly identify and reconcile supportive and conflicting information between text and images. By capturing nuanced insights from both modalities, this approach generates more comprehensive and contextually richer item representations. Extensive experiments conducted on two widely used benchmarks demonstrate that our method outperforms existing prompting baselines in downstream recommendation accuracy. Additionally, we evaluate the generalizability of our framework across different LMM backbones and the robustness of the prompting strategies, offering insights for optimization. This work underscores the importance of integrating multimodal information and presents a novel solution for improving item understanding in multimodal recommendation systems.
Large Content And Behavior Models To Understand, Simulate, And Optimize Content And Behavior
Sep 08, 2023



Shannon, in his seminal paper introducing information theory, divided the communication into three levels: technical, semantic, and effectivenss. While the technical level is concerned with accurate reconstruction of transmitted symbols, the semantic and effectiveness levels deal with the inferred meaning and its effect on the receiver. Thanks to telecommunications, the first level problem has produced great advances like the internet. Large Language Models (LLMs) make some progress towards the second goal, but the third level still remains largely untouched. The third problem deals with predicting and optimizing communication for desired receiver behavior. LLMs, while showing wide generalization capabilities across a wide range of tasks, are unable to solve for this. One reason for the underperformance could be a lack of "behavior tokens" in LLMs' training corpora. Behavior tokens define receiver behavior over a communication, such as shares, likes, clicks, purchases, retweets, etc. While preprocessing data for LLM training, behavior tokens are often removed from the corpora as noise. Therefore, in this paper, we make some initial progress towards reintroducing behavior tokens in LLM training. The trained models, other than showing similar performance to LLMs on content understanding tasks, show generalization capabilities on behavior simulation, content simulation, behavior understanding, and behavior domain adaptation. Using a wide range of tasks on two corpora, we show results on all these capabilities. We call these models Large Content and Behavior Models (LCBMs). Further, to spur more research on LCBMs, we release our new Content Behavior Corpus (CBC), a repository containing communicator, message, and corresponding receiver behavior.
VADER: Video Alignment Differencing and Retrieval
Mar 25, 2023



We propose VADER, a spatio-temporal matching, alignment, and change summarization method to help fight misinformation spread via manipulated videos. VADER matches and coarsely aligns partial video fragments to candidate videos using a robust visual descriptor and scalable search over adaptively chunked video content. A transformer-based alignment module then refines the temporal localization of the query fragment within the matched video. A space-time comparator module identifies regions of manipulation between aligned content, invariant to any changes due to any residual temporal misalignments or artifacts arising from non-editorial changes of the content. Robustly matching video to a trusted source enables conclusions to be drawn on video provenance, enabling informed trust decisions on content encountered.
Show Me What I Like: Detecting User-Specific Video Highlights Using Content-Based Multi-Head Attention
Jul 19, 2022We propose a method to detect individualized highlights for users on given target videos based on their preferred highlight clips marked on previous videos they have watched. Our method explicitly leverages the contents of both the preferred clips and the target videos using pre-trained features for the objects and the human activities. We design a multi-head attention mechanism to adaptively weigh the preferred clips based on their object- and human-activity-based contents, and fuse them using these weights into a single feature representation for each user. We compute similarities between these per-user feature representations and the per-frame features computed from the desired target videos to estimate the user-specific highlight clips from the target videos. We test our method on a large-scale highlight detection dataset containing the annotated highlights of individual users. Compared to current baselines, we observe an absolute improvement of 2-4% in the mean average precision of the detected highlights. We also perform extensive ablation experiments on the number of preferred highlight clips associated with each user as well as on the object- and human-activity-based feature representations to validate that our method is indeed both content-based and user-specific.
* 14 pages, 5 figures, 7 tables
HighlightMe: Detecting Highlights from Human-Centric Videos
Oct 05, 2021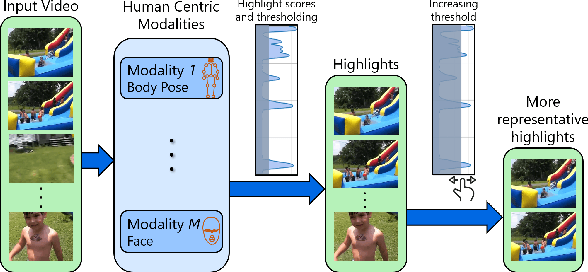
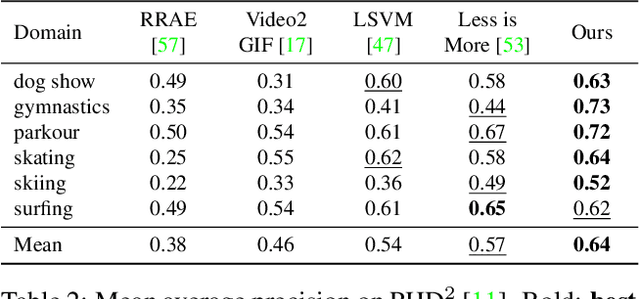
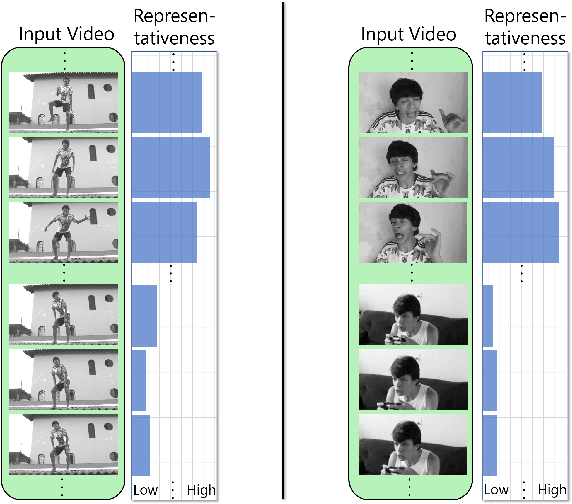

We present a domain- and user-preference-agnostic approach to detect highlightable excerpts from human-centric videos. Our method works on the graph-based representation of multiple observable human-centric modalities in the videos, such as poses and faces. We use an autoencoder network equipped with spatial-temporal graph convolutions to detect human activities and interactions based on these modalities. We train our network to map the activity- and interaction-based latent structural representations of the different modalities to per-frame highlight scores based on the representativeness of the frames. We use these scores to compute which frames to highlight and stitch contiguous frames to produce the excerpts. We train our network on the large-scale AVA-Kinetics action dataset and evaluate it on four benchmark video highlight datasets: DSH, TVSum, PHD2, and SumMe. We observe a 4-12% improvement in the mean average precision of matching the human-annotated highlights over state-of-the-art methods in these datasets, without requiring any user-provided preferences or dataset-specific fine-tuning.