 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentArk: Distilling Multi-Agent Intelligence into a Single LLM Agent
Feb 03, 2026While large language model (LLM) multi-agent systems achieve superior reasoning performance through iterative debate, practical deployment is limited by their high computational cost and error propagation. This paper proposes AgentArk, a novel framework to distill multi-agent dynamics into the weights of a single model, effectively transforming explicit test-time interactions into implicit model capabilities. This equips a single agent with the intelligence of multi-agent systems while remaining computationally efficient. Specifically, we investigate three hierarchical distillation strategies across various models, tasks, scaling, and scenarios: reasoning-enhanced fine-tuning; trajectory-based augmentation; and process-aware distillation. By shifting the burden of computation from inference to training, the distilled models preserve the efficiency of one agent while exhibiting strong reasoning and self-correction performance of multiple agents. They further demonstrate enhanced robustness and generalization across diverse reasoning tasks. We hope this work can shed light on future research on efficient and robust multi-agent development. Our code is at https://github.com/AIFrontierLab/AgentArk.
MASCOT: Towards Multi-Agent Socio-Collaborative Companion Systems
Jan 20, 2026Multi-agent systems (MAS) have recently emerged as promising socio-collaborative companions for emotional and cognitive support. However, these systems frequently suffer from persona collapse--where agents revert to generic, homogenized assistant behaviors--and social sycophancy, which produces redundant, non-constructive dialogue. We propose MASCOT, a generalizable framework for multi-perspective socio-collaborative companions. MASCOT introduces a novel bi-level optimization strategy to harmonize individual and collective behaviors: 1) Persona-Aware Behavioral Alignment, an RLAIF-driven pipeline that finetunes individual agents for strict persona fidelity to prevent identity loss; and 2) Collaborative Dialogue Optimization, a meta-policy guided by group-level rewards to ensure diverse and productive discourse. Extensive evaluations across psychological support and workplace domains demonstrate that MASCOT significantly outperforms state-of-the-art baselines, achieving improvements of up to +14.1 in Persona Consistency and +10.6 in Social Contribution. Our framework provides a practical roadmap for engineering the next generation of socially intelligent multi-agent systems.
SlideAgent: Hierarchical Agentic Framework for Multi-Page Visual Document Understanding
Oct 30, 2025
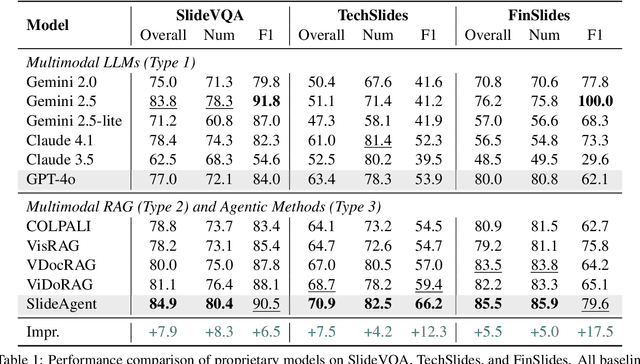


Multi-page visual documents such as manuals, brochures, presentations, and posters convey key information through layout, colors, icons, and cross-slide references. While large language models (LLMs) offer opportunities in document understanding, current systems struggle with complex, multi-page visual documents, particularly in fine-grained reasoning over elements and pages. We introduce SlideAgent, a versatile agentic framework for understanding multi-modal, multi-page, and multi-layout documents, especially slide decks. SlideAgent employs specialized agents and decomposes reasoning into three specialized levels-global, page, and element-to construct a structured, query-agnostic representation that captures both overarching themes and detailed visual or textual cues. During inference, SlideAgent selectively activates specialized agents for multi-level reasoning and integrates their outputs into coherent, context-aware answers. Extensive experiments show that SlideAgent achieves significant improvement over both proprietary (+7.9 overall) and open-source models (+9.8 overall).
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
Topological Structure Learning Should Be A Research Priority for LLM-Based Multi-Agent Systems
May 29, 2025Large Language Model-based Multi-Agent Systems (MASs) have emerged as a powerful paradigm for tackling complex tasks through collaborative intelligence. Nevertheless, the question of how agents should be structurally organized for optimal cooperation remains largely unexplored. In this position paper, we aim to gently redirect the focus of the MAS research community toward this critical dimension: develop topology-aware MASs for specific tasks. Specifically, the system consists of three core components - agents, communication links, and communication patterns - that collectively shape its coordination performance and efficiency. To this end, we introduce a systematic, three-stage framework: agent selection, structure profiling, and topology synthesis. Each stage would trigger new research opportunities in areas such as language models, reinforcement learning, graph learning, and generative modeling; together, they could unleash the full potential of MASs in complicated real-world applications. Then, we discuss the potential challenges and opportunities in the evaluation of multiple systems. We hope our perspective and framework can offer critical new insights in the era of agentic AI.
Reasoning Is Not All You Need: Examining LLMs for Multi-Turn Mental Health Conversations
May 28, 2025Limited access to mental healthcare, extended wait times, and increasing capabilities of Large Language Models (LLMs) has led individuals to turn to LLMs for fulfilling their mental health needs. However, examining the multi-turn mental health conversation capabilities of LLMs remains under-explored. Existing evaluation frameworks typically focus on diagnostic accuracy and win-rates and often overlook alignment with patient-specific goals, values, and personalities required for meaningful conversations. To address this, we introduce MedAgent, a novel framework for synthetically generating realistic, multi-turn mental health sensemaking conversations and use it to create the Mental Health Sensemaking Dialogue (MHSD) dataset, comprising over 2,200 patient-LLM conversations. Additionally, we present MultiSenseEval, a holistic framework to evaluate the multi-turn conversation abilities of LLMs in healthcare settings using human-centric criteria. Our findings reveal that frontier reasoning models yield below-par performance for patient-centric communication and struggle at advanced diagnostic capabilities with average score of 31%. Additionally, we observed variation in model performance based on patient's persona and performance drop with increasing turns in the conversation. Our work provides a comprehensive synthetic data generation framework, a dataset and evaluation framework for assessing LLMs in multi-turn mental health conversations.
The Influence of Text Variation on User Engagement in Cross-Platform Content Sharing
Apr 26, 2025In today's cross-platform social media landscape, understanding factors that drive engagement for multimodal content, especially text paired with visuals, remains complex. This study investigates how rewriting Reddit post titles adapted from YouTube video titles affects user engagement. First, we build and analyze a large dataset of Reddit posts sharing YouTube videos, revealing that 21% of post titles are minimally modified. Statistical analysis demonstrates that title rewrites measurably improve engagement. Second, we design a controlled, multi-phase experiment to rigorously isolate the effects of textual variations by neutralizing confounding factors like video popularity, timing, and community norms. Comprehensive statistical tests reveal that effective title rewrites tend to feature emotional resonance, lexical richness, and alignment with community-specific norms. Lastly, pairwise ranking prediction experiments using a fine-tuned BERT classifier achieves 74% accuracy, significantly outperforming near-random baselines, including GPT-4o. These results validate that our controlled dataset effectively minimizes confounding effects, allowing advanced models to both learn and demonstrate the impact of textual features on engagement. By bridging quantitative rigor with qualitative insights, this study uncovers engagement dynamics and offers a robust framework for future cross-platform, multimodal content strategies.
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Mar 27, 2025The era of intelligent agents is upon us, driven by revolutionary advancements in large language models. Large Language Model (LLM) agents, with goal-driven behaviors and dynamic adaptation capabilities, potentially represent a critical pathway toward artificial general intelligence. This survey systematically deconstructs LLM agent systems through a methodology-centered taxonomy, linking architectural foundations, collaboration mechanisms, and evolutionary pathways. We unify fragmented research threads by revealing fundamental connections between agent design principles and their emergent behaviors in complex environments. Our work provides a unified architectural perspective, examining how agents are constructed, how they collaborate, and how they evolve over time, while also addressing evaluation methodologies, tool applications, practical challenges, and diverse application domains. By surveying the latest developments in this rapidly evolving field, we offer researchers a structured taxonomy for understanding LLM agents and identify promising directions for future research. The collection is available at https://github.com/luo-junyu/Awesome-Agent-Papers.
ScreenLLM: Stateful Screen Schema for Efficient Action Understanding and Prediction
Mar 26, 2025Graphical User Interface (GUI) agents are autonomous systems that interpret and generate actions, enabling intelligent user assistance and automation. Effective training of these agent presents unique challenges, such as sparsity in supervision signals, scalability for large datasets, and the need for nuanced user understanding. We propose stateful screen schema, an efficient representation of GUI interactions that captures key user actions and intentions over time. Building on this foundation, we introduce ScreenLLM, a set of multimodal large language models (MLLMs) tailored for advanced UI understanding and action prediction. Extensive experiments on both open-source and proprietary models show that ScreenLLM accurately models user behavior and predicts actions. Our work lays the foundation for scalable, robust, and intelligent GUI agents that enhance user interaction in diverse software environments.
Protein Large Language Models: A Comprehensive Survey
Feb 21, 2025Protein-specific large language models (Protein LLMs) are revolutionizing protein science by enabling more efficient protein structure prediction, function annotation, and design. While existing surveys focus on specific aspects or applications, this work provides the first comprehensive overview of Protein LLMs, covering their architectures, training datasets, evaluation metrics, and diverse applications. Through a systematic analysis of over 100 articles, we propose a structured taxonomy of state-of-the-art Protein LLMs, analyze how they leverage large-scale protein sequence data for improved accuracy, and explore their potential in advancing protein engineering and biomedical research. Additionally, we discuss key challenges and future directions, positioning Protein LLMs as essential tools for scientific discovery in protein science. Resources are maintained at https://github.com/Yijia-Xiao/Protein-LLM-Survey.