 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnvironment-Robust Representation Learning with Empirical Bayes
Jun 03, 2026We consider multi-environment prediction problems. We assume the environments change the distribution of a latent variable, while the mechanisms generating observed covariates and targets remain stable conditional on that variable. For example, hospitals or clinical cohorts may differ in the prevalence of latent patient states, even though the relationships between those states, physiological measurements, and outcomes remain unchanged. Given a dataset from multiple environments, we formulate a Bayesian model for such problems and derive the corresponding variational objective. We show that this objective decomposes into per-environment terms and an additional cross-environment balancing term induced by the model's structure. We use an empirical Bayes method to set the prior and incorporate it into the objective. Based on this objective, we develop an amortized variational algorithm for posterior approximation, and use the resulting learned latent variables to form predictions in new environments.We study our approach through simulations and real-world studies of astronomical source identification, microbiome-based disease detection, and ICU sepsis prediction. Across these settings, our method outperforms previous approaches for prediction in new environments.
SciCustom: A Framework for Custom Evaluation of Scientific Capabilities in Large Language Models
May 19, 2026Large language models (LLMs) are increasingly applied to scientific research, yet existing evaluations often fail to reflect the fine-grained capabilities required in practice. Most benchmarks are manually curated or domain-generic, limiting scalability and alignment with real scientific use cases. In this paper, we propose a new framework named SciCustom to address the problem. It enables the custom construction of benchmarks from large-scale scientific data to evaluate application-specific scientific capabilities in LLMs. SciCustom first organizes scientific knowledge into ontology-grounded knowledge units with controlled granularity and trains a tagger to map large-scale data instances into this knowledge space. Given a custom requirement, relevant knowledge units are identified via voting-based multi-model consensus. These units enable relevance-aware benchmark retrieval via binary search, followed by proxy subset selection and data-grounded benchmark generation for efficient evaluation. Experiments in chemistry and healthcare demonstrate that SciCustom reveals fine-grained differences in LLM scientific capabilities that standard benchmarks overlook, while requiring neither expert annotation nor synthetic question generation. This work provides a scalable and application-aware foundation for benchmarking scientific capabilities in LLMs. The source code is available at https://github.com/yjwtheonly/SciCustom.
Switch Attention: Towards Dynamic and Fine-grained Hybrid Transformers
Mar 27, 2026The attention mechanism has been the core component in modern transformer architectures. However, the computation of standard full attention scales quadratically with the sequence length, serving as a major bottleneck in long-context language modeling. Sliding window attention restricts the context length for better efficiency at the cost of narrower receptive fields. While existing efforts attempt to take the benefits from both sides by building hybrid models, they often resort to static, heuristically designed alternating patterns that limit efficient allocation of computation in various scenarios. In this paper, we propose Switch Attention (SwiAttn), a novel hybrid transformer that enables dynamic and fine-grained routing between full attention and sliding window attention. For each token at each transformer layer, SwiAttn dynamically routes the computation to either a full-attention branch for global information aggregation or a sliding-window branch for efficient local pattern matching. An adaptive regularization objective is designed to encourage the model towards efficiency. Moreover, we adopt continual pretraining to optimize the model, transferring the full attention architecture to the hybrid one. Extensive experiments are conducted on twenty-three benchmark datasets across both regular (4K) and long (32K) context lengths, demonstrating the effectiveness of the proposed method.
Multi-Domain Causal Empirical Bayes Under Linear Mixing
Mar 19, 2026Causal representation learning (CRL) aims to learn low-dimensional causal latent variables from high-dimensional observations. While identifiability has been extensively studied for CRL, estimation has been less explored. In this paper, we explore the use of empirical Bayes (EB) to estimate causal representations. In particular, we consider the problem of learning from data from multiple domains, where differences between domains are modeled by interventions in a shared underlying causal model. Multi-domain CRL naturally poses a simultaneous inference problem that EB is designed to tackle. Here, we propose an EB $f$-modeling algorithm that improves the quality of learned causal variables by exploiting invariant structure within and across domains. Specifically, we consider a linear measurement model and interventional priors arising from a shared acyclic SCM. When the graph and intervention targets are known, we develop an EM-style algorithm based on causally structured score matching. We further discuss EB $\rmg$-modeling in the context of existing CRL approaches. In experiments on synthetic data, our proposed method achieves more accurate estimation than other methods for CRL.
Rapid Adaptation of Particle Dynamics for Generalized Deformable Object Mobile Manipulation
Mar 18, 2026We address the challenge of learning to manipulate deformable objects with unknown dynamics. In non-rigid objects, the dynamics parameters define how they react to interactions -- how they stretch, bend, compress, and move -- and they are critical to determining the optimal actions to perform a manipulation task successfully. In other robotic domains, such as legged locomotion and in-hand rigid object manipulation, state-of-the-art approaches can handle unknown dynamics using Rapid Motor Adaptation (RMA). Through a supervised procedure in simulation that encodes each rigid object's dynamics, such as mass and position, these approaches learn a policy that conditions actions on a vector of latent dynamic parameters inferred from sequences of state-actions. However, in deformable object manipulation, the object's dynamics not only includes its mass and position, but also how the shape of the object changes. Our key insight is that the recent ground-truth particle positions of a deformable object in simulation capture changes in the object's shape, making it possible to extend RMA to deformable object manipulation. This key insight allows us to develop RAPiD, a two-phase method that learns to perform real-robot deformable object mobile manipulation by: 1) learning a visuomotor policy conditioned on the object's dynamics embedding, which is encoded from the object's privileged information in simulation, such as its mass and ground-truth particle positions, and 2) learning to infer this embedding using non-privileged information instead, such as robot visual observations and actions, so that the learned policy can transfer to the real world. On a mobile manipulator with 22 degrees of freedom, RAPiD enables over 80%+ success rates across two vision-based deformable object mobile manipulation tasks in the real world, under various object dynamics, categories, and instances.
Bayesian Empirical Bayes: Simultaneous Inference from Probabilistic Symmetries
Dec 22, 2025
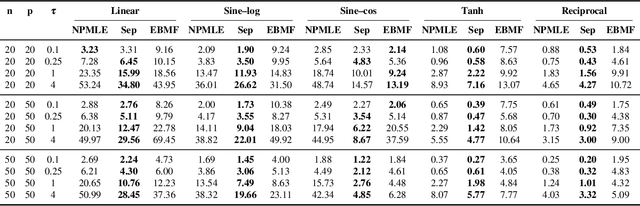

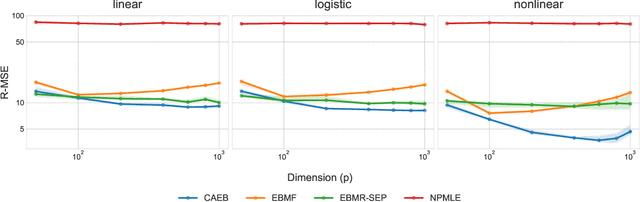
Empirical Bayes (EB) improves the accuracy of simultaneous inference "by learning from the experience of others" (Efron, 2012). Classical EB theory focuses on latent variables that are iid draws from a fitted prior (Efron, 2019). Modern applications, however, feature complex structure, like arrays, spatial processes, or covariates. How can we apply EB ideas to these settings? We propose a generalized approach to empirical Bayes based on the notion of probabilistic symmetry. Our method pairs a simultaneous inference problem-with an unknown prior-to a symmetry assumption on the joint distribution of the latent variables. Each symmetry implies an ergodic decomposition, which we use to derive a corresponding empirical Bayes method. We call this methodBayesian empirical Bayes (BEB). We show how BEB recovers the classical methods of empirical Bayes, which implicitly assume exchangeability. We then use it to extend EB to other probabilistic symmetries: (i) EB matrix recovery for arrays and graphs; (ii) covariate-assisted EB for conditional data; (iii) EB spatial regression under shift invariance. We develop scalable algorithms based on variational inference and neural networks. In simulations, BEB outperforms existing approaches to denoising arrays and spatial data. On real data, we demonstrate BEB by denoising a cancer gene-expression matrix and analyzing spatial air-quality data from New York City.
Theory and computation for structured variational inference
Nov 13, 2025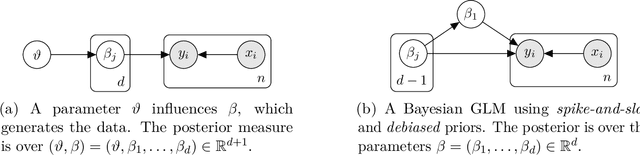
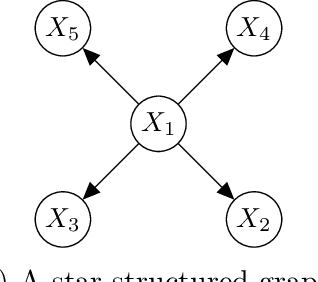
Structured variational inference constitutes a core methodology in modern statistical applications. Unlike mean-field variational inference, the approximate posterior is assumed to have interdependent structure. We consider the natural setting of star-structured variational inference, where a root variable impacts all the other ones. We prove the first results for existence, uniqueness, and self-consistency of the variational approximation. In turn, we derive quantitative approximation error bounds for the variational approximation to the posterior, extending prior work from the mean-field setting to the star-structured setting. We also develop a gradient-based algorithm with provable guarantees for computing the variational approximation using ideas from optimal transport theory. We explore the implications of our results for Gaussian measures and hierarchical Bayesian models, including generalized linear models with location family priors and spike-and-slab priors with one-dimensional debiasing. As a by-product of our analysis, we develop new stability results for star-separable transport maps which might be of independent interest.
A Survey on Efficient Large Language Model Training: From Data-centric Perspectives
Oct 29, 2025Post-training of Large Language Models (LLMs) is crucial for unlocking their task generalization potential and domain-specific capabilities. However, the current LLM post-training paradigm faces significant data challenges, including the high costs of manual annotation and diminishing marginal returns on data scales. Therefore, achieving data-efficient post-training has become a key research question. In this paper, we present the first systematic survey of data-efficient LLM post-training from a data-centric perspective. We propose a taxonomy of data-efficient LLM post-training methods, covering data selection, data quality enhancement, synthetic data generation, data distillation and compression, and self-evolving data ecosystems. We summarize representative approaches in each category and outline future research directions. By examining the challenges in data-efficient LLM post-training, we highlight open problems and propose potential research avenues. We hope our work inspires further exploration into maximizing the potential of data utilization in large-scale model training. Paper List: https://github.com/luo-junyu/Awesome-Data-Efficient-LLM
GET-USE: Learning Generalized Tool Usage for Bimanual Mobile Manipulation via Simulated Embodiment Extensions
Oct 29, 2025The ability to use random objects as tools in a generalizable manner is a missing piece in robots' intelligence today to boost their versatility and problem-solving capabilities. State-of-the-art robotic tool usage methods focused on procedurally generating or crowd-sourcing datasets of tools for a task to learn how to grasp and manipulate them for that task. However, these methods assume that only one object is provided and that it is possible, with the correct grasp, to perform the task; they are not capable of identifying, grasping, and using the best object for a task when many are available, especially when the optimal tool is absent. In this work, we propose GeT-USE, a two-step procedure that learns to perform real-robot generalized tool usage by learning first to extend the robot's embodiment in simulation and then transferring the learned strategies to real-robot visuomotor policies. Our key insight is that by exploring a robot's embodiment extensions (i.e., building new end-effectors) in simulation, the robot can identify the general tool geometries most beneficial for a task. This learned geometric knowledge can then be distilled to perform generalized tool usage tasks by selecting and using the best available real-world object as tool. On a real robot with 22 degrees of freedom (DOFs), GeT-USE outperforms state-of-the-art methods by 30-60% success rates across three vision-based bimanual mobile manipulation tool-usage tasks.
Stability of Mean-Field Variational Inference
Jun 09, 2025Mean-field variational inference (MFVI) is a widely used method for approximating high-dimensional probability distributions by product measures. This paper studies the stability properties of the mean-field approximation when the target distribution varies within the class of strongly log-concave measures. We establish dimension-free Lipschitz continuity of the MFVI optimizer with respect to the target distribution, measured in the 2-Wasserstein distance, with Lipschitz constant inversely proportional to the log-concavity parameter. Under additional regularity conditions, we further show that the MFVI optimizer depends differentiably on the target potential and characterize the derivative by a partial differential equation. Methodologically, we follow a novel approach to MFVI via linearized optimal transport: the non-convex MFVI problem is lifted to a convex optimization over transport maps with a fixed base measure, enabling the use of calculus of variations and functional analysis. We discuss several applications of our results to robust Bayesian inference and empirical Bayes, including a quantitative Bernstein--von Mises theorem for MFVI, as well as to distributed stochastic control.