 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Network Inference under Imperfect Detection and its Application to Ecological Networks
Apr 20, 2026Recovering latent structure from count data has received considerable attention in network inference, particularly when one seeks both cross-group interactions and within-group similarity patterns in bipartite networks, which is widely used in ecology research. Such networks are often sparse and inherently imperfect in their detection. Existing models mainly focus on interaction recovery, while the induced similarity graphs are much less studied. Moreover, sparsity is often not controlled, and scale is unbalanced, leading to oversparse or poorly rescaled estimates with degrading structural recovery. To address these issues, we propose a framework for structured sparse nonnegative low-rank factorization with detection probability estimation. We impose nonconvex $\ell_{1/2}$ regularization on the latent similarity and connectivity structures to promote sparsity within-group similarity and cross-group connectivity with better relative scale. The resulting optimization problem is nonconvex and nonsmooth. To solve it, we develop an ADMM-based algorithm with adaptive penalization and scale-aware initialization and establish its asymptotic feasibility and KKT stationarity of cluster points under mild regularity conditions. Experiments on synthetic and real-world ecological datasets demonstrate improved recovery of latent factors and similarity/connectivity structure relative to existing baselines.
Fréchet Regression on the Bures-Wasserstein Manifold
Apr 04, 2026Fréchet regression, or conditional Barycenters, is a flexible framework for modeling relationships between covariates (usually Euclidean) and response variables on general metric spaces, e.g., probability distributions or positive definite matrices. However, in contrast to classical barycenter problems, computing conditional counterparts in many non-Euclidean spaces remains an open challenge, as they yield non-convex optimization problems with an affine structure. In this work, we study the existence and computation of conditional barycenters, specifically in the space of positive-definite matrices with the Bures-Wasserstein metric. We provide a sufficient condition for the existence of a minimizer of the conditional barycenter problem that characterizes the regression range of extrapolation. Moreover, we further characterize the optimization landscape, proving that under this condition, the objective is free of local maxima. Additionally, we develop a projection-free and provably correct algorithm for the approximate computation of first-order stationary points. Finally, we provide a stochastic reformulation that enables the use of off-the-shelf stochastic Riemannian optimization methods for large-scale setups. Numerical experiments validate the performance of the proposed methods on regression problems of real-world biological networks and on large-scale synthetic Diffusion Tensor Imaging problems.
Gromov-Wasserstein Graph Coarsening
Nov 11, 2025We study the problem of graph coarsening within the Gromov-Wasserstein geometry. Specifically, we propose two algorithms that leverage a novel representation of the distortion induced by merging pairs of nodes. The first method, termed Greedy Pair Coarsening (GPC), iteratively merges pairs of nodes that locally minimize a measure of distortion until the desired size is achieved. The second method, termed $k$-means Greedy Pair Coarsening (KGPC), leverages clustering based on pairwise distortion metrics to directly merge clusters of nodes. We provide conditions guaranteeing optimal coarsening for our methods and validate their performance on six large-scale datasets and a downstream clustering task. Results show that the proposed methods outperform existing approaches on a wide range of parameters and scenarios.
ADMM for Downlink Beamforming in Cell-Free Massive MIMO Systems
Sep 09, 2024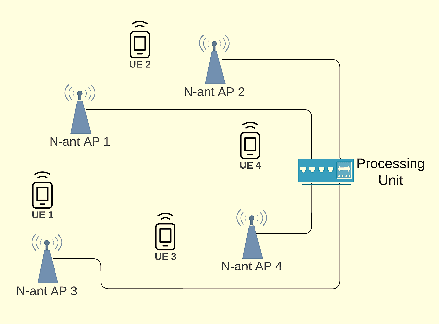

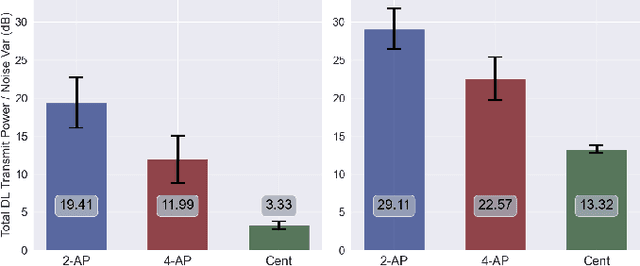
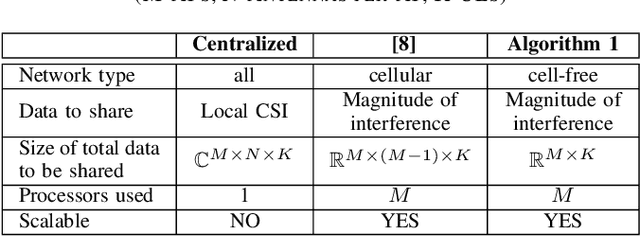
In cell-free massive MIMO systems with multiple distributed access points (APs) serving multiple users over the same time-frequency resources, downlink beamforming is done through spatial precoding. Precoding vectors can be optimally designed to use the minimum downlink transmit power while satisfying a quality-of-service requirement for each user. However, existing centralized solutions to beamforming optimization pose challenges such as high communication overhead and processing delay. On the other hand, distributed approaches either require data exchange over the network that scales with the number of antennas or solve the problem for cellular systems where every user is served by only one AP. In this paper, we formulate a multi-user beamforming optimization problem to minimize the total transmit power subject to per-user SINR requirements and propose a distributed optimization algorithm based on the alternating direction method of multipliers (ADMM) to solve it. In our method, every AP solves an iterative optimization problem using its local channel state information. APs only need to share a real-valued vector of interference terms with the size of the number of users. Through simulation results, we demonstrate that our proposed algorithm solves the optimization problem within tens of ADMM iterations and can effectively satisfy per-user SINR constraints.
Efficient Path Planning with Soft Homology Constraints
Jun 27, 2024



We study the problem of path planning with soft homology constraints on a surface topologically equivalent to a disk with punctures. Specifically, we propose an algorithm, named $\Hstar$, for the efficient computation of a path homologous to a user-provided reference path. We show that the algorithm can generate a suite of paths in distinct homology classes, from the overall shortest path to the shortest path homologous to the reference path, ordered both by path length and similarity to the reference path. Rollout is shown to improve the results produced by the algorithm. Experiments demonstrate that $\Hstar$ can be an efficient alternative to optimal methods, especially for configuration spaces with many obstacles.
An Optimal Transport Approach for Network Regression
Jun 18, 2024We study the problem of network regression, where one is interested in how the topology of a network changes as a function of Euclidean covariates. We build upon recent developments in generalized regression models on metric spaces based on Fr\'echet means and propose a network regression method using the Wasserstein metric. We show that when representing graphs as multivariate Gaussian distributions, the network regression problem requires the computation of a Riemannian center of mass (i.e., Fr\'echet means). Fr\'echet means with non-negative weights translates into a barycenter problem and can be efficiently computed using fixed point iterations. Although the convergence guarantees of fixed-point iterations for the computation of Wasserstein affine averages remain an open problem, we provide evidence of convergence in a large number of synthetic and real-data scenarios. Extensive numerical results show that the proposed approach improves existing procedures by accurately accounting for graph size, topology, and sparsity in synthetic experiments. Additionally, real-world experiments using the proposed approach result in higher Coefficient of Determination ($R^{2}$) values and lower mean squared prediction error (MSPE), cementing improved prediction capabilities in practice.
A Moreau Envelope Approach for LQR Meta-Policy Estimation
Mar 26, 2024

We study the problem of policy estimation for the Linear Quadratic Regulator (LQR) in discrete-time linear time-invariant uncertain dynamical systems. We propose a Moreau Envelope-based surrogate LQR cost, built from a finite set of realizations of the uncertain system, to define a meta-policy efficiently adjustable to new realizations. Moreover, we design an algorithm to find an approximate first-order stationary point of the meta-LQR cost function. Numerical results show that the proposed approach outperforms naive averaging of controllers on new realizations of the linear system. We also provide empirical evidence that our method has better sample complexity than Model-Agnostic Meta-Learning (MAML) approaches.
Decentralized and Equitable Optimal Transport
Mar 12, 2024

This paper considers the decentralized (discrete) optimal transport (D-OT) problem. In this setting, a network of agents seeks to design a transportation plan jointly, where the cost function is the sum of privately held costs for each agent. We reformulate the D-OT problem as a constraint-coupled optimization problem and propose a single-loop decentralized algorithm with an iteration complexity of O(1/{\epsilon}) that matches existing centralized first-order approaches. Moreover, we propose the decentralized equitable optimal transport (DE-OT) problem. In DE-OT, in addition to cooperatively designing a transportation plan that minimizes transportation costs, agents seek to ensure equity in their individual costs. The iteration complexity of the proposed method to solve DE-OT is also O(1/{\epsilon}). This rate improves existing centralized algorithms, where the best iteration complexity obtained is O(1/{\epsilon}^2).
PIDformer: Transformer Meets Control Theory
Feb 25, 2024



In this work, we address two main shortcomings of transformer architectures: input corruption and rank collapse in their output representation. We unveil self-attention as an autonomous state-space model that inherently promotes smoothness in its solutions, leading to lower-rank outputs and diminished representation capacity. Moreover, the steady-state solution of the model is sensitive to input perturbations. We incorporate a Proportional-Integral-Derivative (PID) closed-loop feedback control system with a reference point into the model to improve robustness and representation capacity. This integration aims to preserve high-frequency details while bolstering model stability, rendering it more noise-resilient. The resulting controlled state-space model is theoretically proven robust and adept at addressing the rank collapse. Motivated by this control framework, we derive a novel class of transformers, PID-controlled Transformer (PIDformer), aimed at improving robustness and mitigating the rank-collapse issue inherent in softmax transformers. We empirically evaluate the model for advantages and robustness against baseline transformers across various practical tasks, including object classification, image segmentation, and language modeling.
Improving Denoising Diffusion Probabilistic Models via Exploiting Shared Representations
Nov 27, 2023In this work, we address the challenge of multi-task image generation with limited data for denoising diffusion probabilistic models (DDPM), a class of generative models that produce high-quality images by reversing a noisy diffusion process. We propose a novel method, SR-DDPM, that leverages representation-based techniques from few-shot learning to effectively learn from fewer samples across different tasks. Our method consists of a core meta architecture with shared parameters, i.e., task-specific layers with exclusive parameters. By exploiting the similarity between diverse data distributions, our method can scale to multiple tasks without compromising the image quality. We evaluate our method on standard image datasets and show that it outperforms both unconditional and conditional DDPM in terms of FID and SSIM metrics.