 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuperThoughts: Reasoning Tokens in Superposition
Jun 11, 2026Long Chain-of-Thought (CoT) reasoning improves LLM problem-solving but is computationally expensive due to sequential token generation. While recent works explore reasoning in continuous latent spaces to bypass discrete token generation, they often struggle with training stability and fail to scale to complex, long-horizon tasks due to lack of supervision signal. We propose SuperThoughts, which compresses pairs of consecutive CoT tokens into single latent representations and decodes two tokens per step via a lightweight Multi-Token Prediction (MTP) module. This preserves discrete token supervision at training time while doubling throughput at inference time. We finetune Qwen2.5-Math-1.5B-Instruct, Qwen2.5-Math-7B-Instruct, Qwen2.5-Math-14B-Instruct, and evaluate on MATH500, AMC, OlympiadBench, and GPQA-Diamond. With a confidence-based adaptive mechanism that falls back to standard decoding when uncertain, SuperThoughts achieves $\sim$20--30\% CoT length reduction while maintaining accuracy with minimal degradation (1-2 points accuracy drop on most tasks).
AdaPaD: Adaptive Parallel Deflation for PEFT with Self-Correcting Rank Discovery
May 11, 2026Fine-tuning large language models with LoRA requires choosing a rank r before training starts. Existing approaches either extract rank-1 components sequentially, freezing each component's error permanently into every subsequent residual, or optimize the full low-rank factorization jointly with guarantees that describe only the joint update, not individual rank-1 directions. We present AdaPaD (Adaptive Parallel Deflation), which trains all rank-1 components simultaneously: each worker refines its component against a deflation target built from the latest estimates of all predecessors, and as those estimates improve, the targets improve too. We call this property self-correction: deflation errors converge to zero over rounds rather than persisting as fixed residuals. On top of this backbone, AdaPaD adds advance learning (private pre-training before activation) and per-module dynamic rank discovery (importance-based growth until a shared budget is exhausted), making the rank distribution an output rather than an input. We prove that every component's error decays exponentially after a warm-up period, with a generalization bound that splits into a vanishing algorithmic term and an irreducible statistical floor. Empirically, AdaPaD is competitive with adaptive-rank LoRA baselines on GLUE with DeBERTaV3-base at matched parameter budgets, and competitive with fixed-rank LoRA on Qwen3-0.6B SQuAD/SQuAD v2 while deploying an adapter that is on average 30.7% smaller.
SGD at the Edge of Stability: The Stochastic Sharpness Gap
Apr 22, 2026When training neural networks with full-batch gradient descent (GD) and step size $η$, the largest eigenvalue of the Hessian -- the sharpness $S(\boldsymbolθ)$ -- rises to $2/η$ and hovers there, a phenomenon termed the Edge of Stability (EoS). \citet{damian2023selfstab} showed that this behavior is explained by a self-stabilization mechanism driven by third-order structure of the loss, and that GD implicitly follows projected gradient descent (PGD) on the constraint $ S(\boldsymbolθ)\leq 2/η$. For mini-batch stochastic gradient descent (SGD), the sharpness stabilizes below $2/η$, with the gap widening as the batch size decreases; yet no theoretical explanation exists for this suppression. We introduce stochastic self-stabilization, extending the self-stabilization framework to SGD. Our key insight is that gradient noise injects variance into the oscillatory dynamics along the top Hessian eigenvector, strengthening the cubic sharpness-reducing force and shifting the equilibrium below $2/η$. Following the approach of \citet{damian2023selfstab}, we define stochastic predicted dynamics relative to a moving projected gradient descent trajectory and prove a stochastic coupling theorem that bounds the deviation of SGD from these predictions. We derive a closed-form equilibrium sharpness gap: $ΔS = ηβσ_{\boldsymbol{u}}^{2}/(4α)$, where $α$ is the progressive sharpening rate, $β$ is the self-stabilization strength, and $σ_{ \boldsymbol{u}}^{2}$ is the gradient noise variance projected onto the top eigenvector. This formula predicts that smaller batch sizes yield flatter solutions and recovers GD when the batch equals the full dataset.
Exploiting Low-Rank Structure in Max-K-Cut Problems
Feb 23, 2026We approach the Max-3-Cut problem through the lens of maximizing complex-valued quadratic forms and demonstrate that low-rank structure in the objective matrix can be exploited, leading to alternative algorithms to classical semidefinite programming (SDP) relaxations and heuristic techniques. We propose an algorithm for maximizing these quadratic forms over a domain of size $K$ that enumerates and evaluates a set of $O\left(n^{2r-1}\right)$ candidate solutions, where $n$ is the dimension of the matrix and $r$ represents the rank of an approximation of the objective. We prove that this candidate set is guaranteed to include the exact maximizer when $K=3$ (corresponding to Max-3-Cut) and the objective is low-rank, and provide approximation guarantees when the objective is a perturbation of a low-rank matrix. This construction results in a family of novel, inherently parallelizable and theoretically-motivated algorithms for Max-3-Cut. Extensive experimental results demonstrate that our approach achieves performance comparable to existing algorithms across a wide range of graphs, while being highly scalable.
GHOST: Unmasking Phantom States in Mamba2 via Grouped Hidden-state Output-aware Selection & Truncation
Feb 11, 2026While Mamba2's expanded state dimension enhances temporal modeling, it incurs substantial inference overhead that saturates bandwidth during autoregressive generation. Standard pruning methods fail to address this bottleneck: unstructured sparsity leaves activations dense, magnitude-based selection ignores runtime dynamics, and gradient-based methods impose prohibitive costs. We introduce GHOST (Grouped Hidden-state Output-aware Selection and Truncation), a structured pruning framework that approximates control-theoretic balanced truncation using only forward-pass statistics. By jointly measuring controllability and observability, GHOST rivals the fidelity of gradient-based methods without requiring backpropagation. As a highlight, on models ranging from 130M to 2.7B parameters, our approach achieves a 50\% state-dimension reduction with approximately 1 perplexity point increase on WikiText-2. Code is available at https://anonymous.4open.science/r/mamba2_ghost-7BCB/.
Completion of partial structures using Patterson maps with the CrysFormer machine learning model
Nov 13, 2025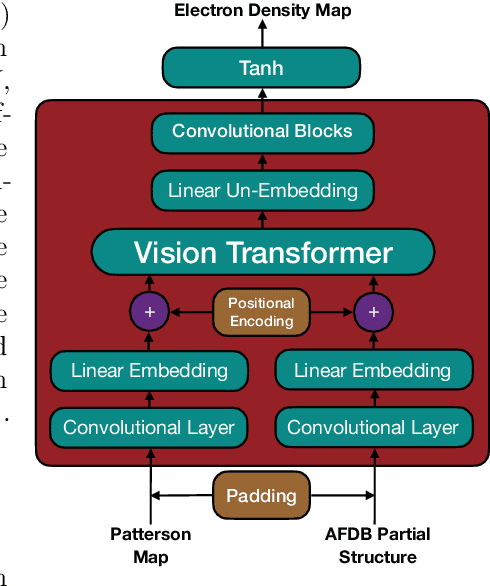
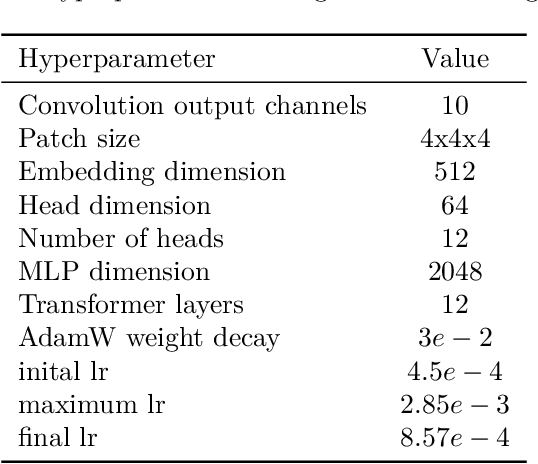
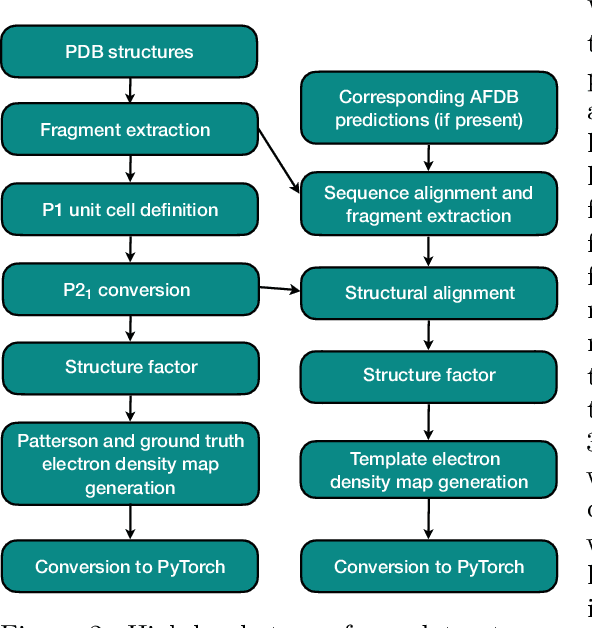
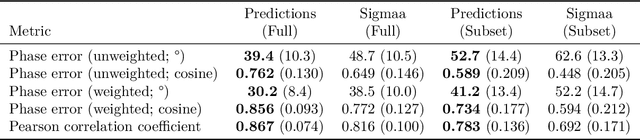
Protein structure determination has long been one of the primary challenges of structural biology, to which deep machine learning (ML)-based approaches have increasingly been applied. However, these ML models generally do not incorporate the experimental measurements directly, such as X-ray crystallographic diffraction data. To this end, we explore an approach that more tightly couples these traditional crystallographic and recent ML-based methods, by training a hybrid 3-d vision transformer and convolutional network on inputs from both domains. We make use of two distinct input constructs / Patterson maps, which are directly obtainable from crystallographic data, and ``partial structure'' template maps derived from predicted structures deposited in the AlphaFold Protein Structure Database with subsequently omitted residues. With these, we predict electron density maps that are then post-processed into atomic models through standard crystallographic refinement processes. Introducing an initial dataset of small protein fragments taken from Protein Data Bank entries and placing them in hypothetical crystal settings, we demonstrate that our method is effective at both improving the phases of the crystallographic structure factors and completing the regions missing from partial structure templates, as well as improving the agreement of the electron density maps with the ground truth atomic structures.
TwIST: Rigging the Lottery in Transformers with Independent Subnetwork Training
Nov 06, 2025We introduce TwIST, a distributed training framework for efficient large language model (LLM) sparsification. TwIST trains multiple subnetworks in parallel, periodically aggregates their parameters, and resamples new subnetworks during training. This process identifies high-quality subnetworks ("golden tickets") without requiring post-training procedures such as calibration or Hessian-based recovery. As a result, TwIST enables zero-cost pruning at deployment time while achieving perplexity competitive with state-of-the-art post-training sparsification methods. The benefits are most pronounced under aggressive sparsity (e.g., 50%+), where TwIST significantly outperforms baseline methods; for example, reaching 23.14 PPL compared to 31.64 for the closest prior approach. Unlike unstructured pruning, TwIST produces structured, dense matrices that offer practical inference speedups and memory reductions on commodity hardware (e.g., CPUs) that do not support efficient sparse computation. TwIST provides an efficient training-time path to deployable sparse LLMs without additional fine-tuning or recovery overhead.
Three Birds with One Stone: Improving Performance, Convergence, and System Throughput with Nest
Oct 10, 2025



Variational quantum algorithms (VQAs) have the potential to demonstrate quantum utility on near-term quantum computers. However, these algorithms often get executed on the highest-fidelity qubits and computers to achieve the best performance, causing low system throughput. Recent efforts have shown that VQAs can be run on low-fidelity qubits initially and high-fidelity qubits later on to still achieve good performance. We take this effort forward and show that carefully varying the qubit fidelity map of the VQA over its execution using our technique, Nest, does not just (1) improve performance (i.e., help achieve close to optimal results), but also (2) lead to faster convergence. We also use Nest to co-locate multiple VQAs concurrently on the same computer, thus (3) increasing the system throughput, and therefore, balancing and optimizing three conflicting metrics simultaneously.
Guided by the Experts: Provable Feature Learning Dynamic of Soft-Routed Mixture-of-Experts
Oct 08, 2025

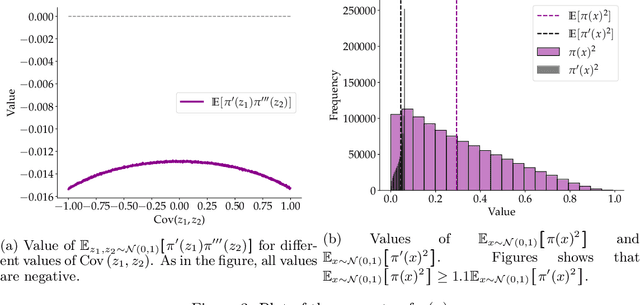
Mixture-of-Experts (MoE) architectures have emerged as a cornerstone of modern AI systems. In particular, MoEs route inputs dynamically to specialized experts whose outputs are aggregated through weighted summation. Despite their widespread application, theoretical understanding of MoE training dynamics remains limited to either separate expert-router optimization or only top-1 routing scenarios with carefully constructed datasets. This paper advances MoE theory by providing convergence guarantees for joint training of soft-routed MoE models with non-linear routers and experts in a student-teacher framework. We prove that, with moderate over-parameterization, the student network undergoes a feature learning phase, where the router's learning process is ``guided'' by the experts, that recovers the teacher's parameters. Moreover, we show that a post-training pruning can effectively eliminate redundant neurons, followed by a provably convergent fine-tuning process that reaches global optimality. To our knowledge, our analysis is the first to bring novel insights in understanding the optimization landscape of the MoE architecture.
One Rank at a Time: Cascading Error Dynamics in Sequential Learning
May 28, 2025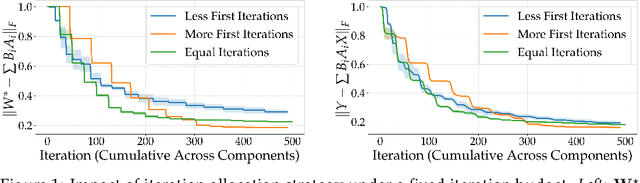
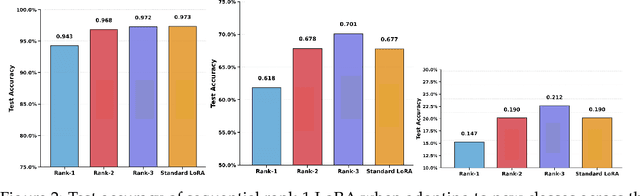
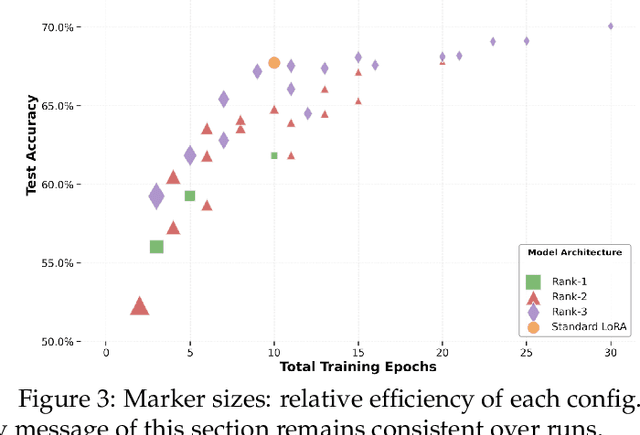
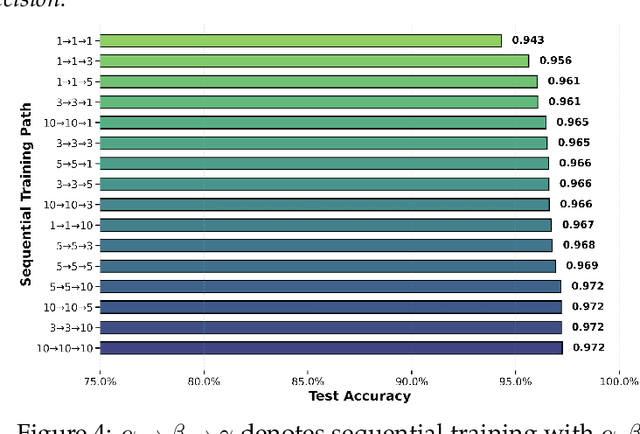
Sequential learning -- where complex tasks are broken down into simpler, hierarchical components -- has emerged as a paradigm in AI. This paper views sequential learning through the lens of low-rank linear regression, focusing specifically on how errors propagate when learning rank-1 subspaces sequentially. We present an analysis framework that decomposes the learning process into a series of rank-1 estimation problems, where each subsequent estimation depends on the accuracy of previous steps. Our contribution is a characterization of the error propagation in this sequential process, establishing bounds on how errors -- e.g., due to limited computational budgets and finite precision -- affect the overall model accuracy. We prove that these errors compound in predictable ways, with implications for both algorithmic design and stability guarantees.