 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBetter Schedules for Low Precision Training of Deep Neural Networks
Mar 04, 2024Low precision training can significantly reduce the computational overhead of training deep neural networks (DNNs). Though many such techniques exist, cyclic precision training (CPT), which dynamically adjusts precision throughout training according to a cyclic schedule, achieves particularly impressive improvements in training efficiency, while actually improving DNN performance. Existing CPT implementations take common learning rate schedules (e.g., cyclical cosine schedules) and use them for low precision training without adequate comparisons to alternative scheduling options. We define a diverse suite of CPT schedules and analyze their performance across a variety of DNN training regimes, some of which are unexplored in the low precision training literature (e.g., node classification with graph neural networks). From these experiments, we discover alternative CPT schedules that offer further improvements in training efficiency and model performance, as well as derive a set of best practices for choosing CPT schedules. Going further, we find that a correlation exists between model performance and training cost, and that changing the underlying CPT schedule can control the tradeoff between these two variables. To explain the direct correlation between model performance and training cost, we draw a connection between quantized training and critical learning periods, suggesting that aggressive quantization is a form of learning impairment that can permanently damage model performance.
* 20 pages, 8 figures, 1 table, ACML 2023
Cold Start Streaming Learning for Deep Networks
Nov 09, 2022The ability to dynamically adapt neural networks to newly-available data without performance deterioration would revolutionize deep learning applications. Streaming learning (i.e., learning from one data example at a time) has the potential to enable such real-time adaptation, but current approaches i) freeze a majority of network parameters during streaming and ii) are dependent upon offline, base initialization procedures over large subsets of data, which damages performance and limits applicability. To mitigate these shortcomings, we propose Cold Start Streaming Learning (CSSL), a simple, end-to-end approach for streaming learning with deep networks that uses a combination of replay and data augmentation to avoid catastrophic forgetting. Because CSSL updates all model parameters during streaming, the algorithm is capable of beginning streaming from a random initialization, making base initialization optional. Going further, the algorithm's simplicity allows theoretical convergence guarantees to be derived using analysis of the Neural Tangent Random Feature (NTRF). In experiments, we find that CSSL outperforms existing baselines for streaming learning in experiments on CIFAR100, ImageNet, and Core50 datasets. Additionally, we propose a novel multi-task streaming learning setting and show that CSSL performs favorably in this domain. Put simply, CSSL performs well and demonstrates that the complicated, multi-step training pipelines adopted by most streaming methodologies can be replaced with a simple, end-to-end learning approach without sacrificing performance.
PipeGCN: Efficient Full-Graph Training of Graph Convolutional Networks with Pipelined Feature Communication
Mar 20, 2022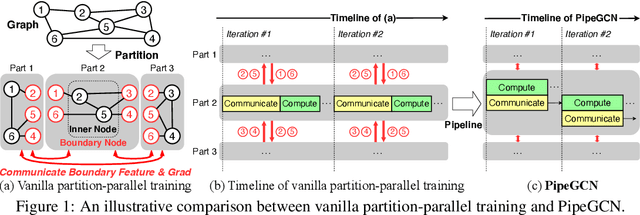

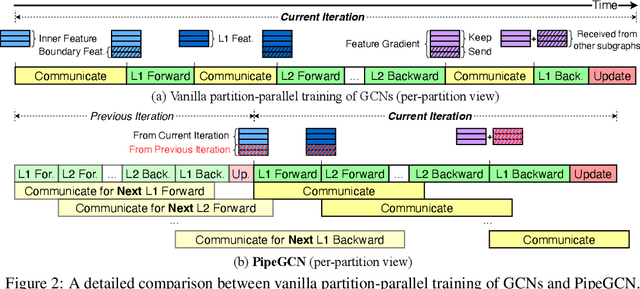

Graph Convolutional Networks (GCNs) is the state-of-the-art method for learning graph-structured data, and training large-scale GCNs requires distributed training across multiple accelerators such that each accelerator is able to hold a partitioned subgraph. However, distributed GCN training incurs prohibitive overhead of communicating node features and feature gradients among partitions for every GCN layer during each training iteration, limiting the achievable training efficiency and model scalability. To this end, we propose PipeGCN, a simple yet effective scheme that hides the communication overhead by pipelining inter-partition communication with intra-partition computation. It is non-trivial to pipeline for efficient GCN training, as communicated node features/gradients will become stale and thus can harm the convergence, negating the pipeline benefit. Notably, little is known regarding the convergence rate of GCN training with both stale features and stale feature gradients. This work not only provides a theoretical convergence analysis but also finds the convergence rate of PipeGCN to be close to that of the vanilla distributed GCN training without any staleness. Furthermore, we develop a smoothing method to further improve PipeGCN's convergence. Extensive experiments show that PipeGCN can largely boost the training throughput (1.7x~28.5x) while achieving the same accuracy as its vanilla counterpart and existing full-graph training methods. The code is available at https://github.com/RICE-EIC/PipeGCN.
i-SpaSP: Structured Neural Pruning via Sparse Signal Recovery
Dec 07, 2021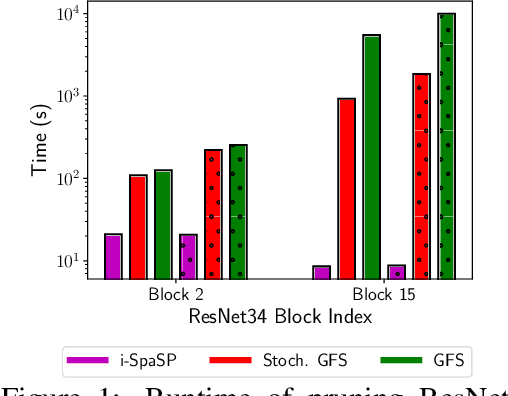

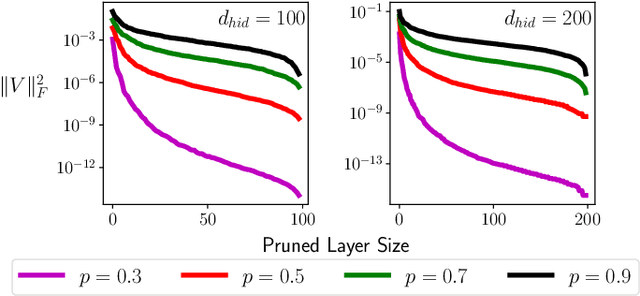
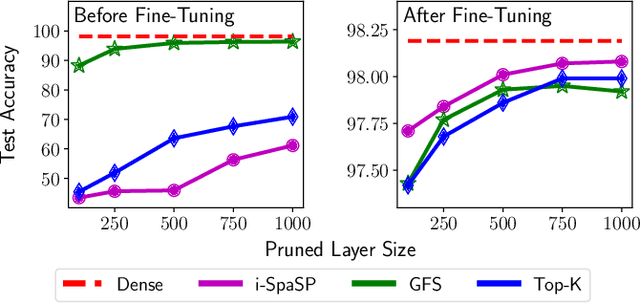
We propose a novel, structured pruning algorithm for neural networks -- the iterative, Sparse Structured Pruning algorithm, dubbed as i-SpaSP. Inspired by ideas from sparse signal recovery, i-SpaSP operates by iteratively identifying a larger set of important parameter groups (e.g., filters or neurons) within a network that contribute most to the residual between pruned and dense network output, then thresholding these groups based on a smaller, pre-defined pruning ratio. For both two-layer and multi-layer network architectures with ReLU activations, we show the error induced by pruning with i-SpaSP decays polynomially, where the degree of this polynomial becomes arbitrarily large based on the sparsity of the dense network's hidden representations. In our experiments, i-SpaSP is evaluated across a variety of datasets (i.e., MNIST and ImageNet) and architectures (i.e., feed forward networks, ResNet34, and MobileNetV2), where it is shown to discover high-performing sub-networks and improve upon the pruning efficiency of provable baseline methodologies by several orders of magnitude. Put simply, i-SpaSP is easy to implement with automatic differentiation, achieves strong empirical results, comes with theoretical convergence guarantees, and is efficient, thus distinguishing itself as one of the few computationally efficient, practical, and provable pruning algorithms.
Provably Efficient Lottery Ticket Discovery
Jul 31, 2021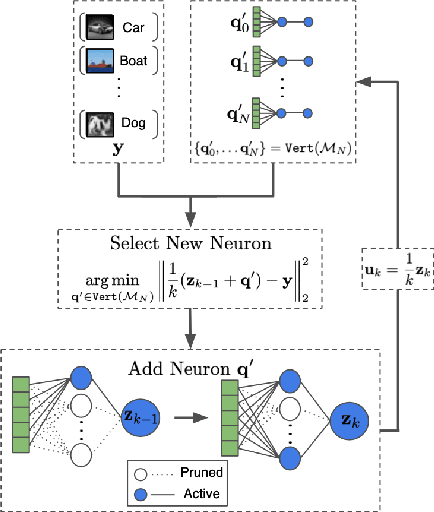
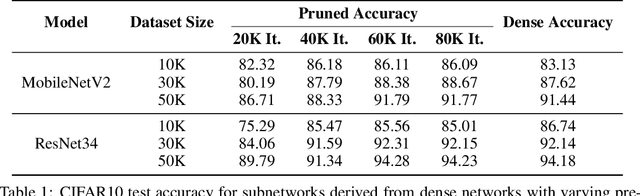
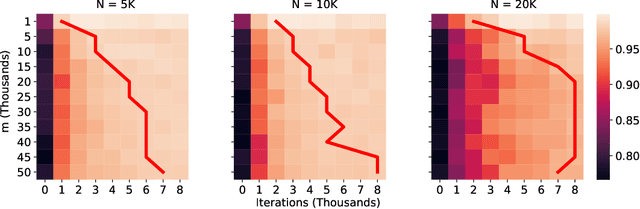

The lottery ticket hypothesis (LTH) claims that randomly-initialized, dense neural networks contain (sparse) subnetworks that, when trained an equal amount in isolation, can match the dense network's performance. Although LTH is useful for discovering efficient network architectures, its three-step process -- pre-training, pruning, and re-training -- is computationally expensive, as the dense model must be fully pre-trained. Luckily, "early-bird" tickets can be discovered within neural networks that are minimally pre-trained, allowing for the creation of efficient, LTH-inspired training procedures. Yet, no theoretical foundation of this phenomenon exists. We derive an analytical bound for the number of pre-training iterations that must be performed for a winning ticket to be discovered, thus providing a theoretical understanding of when and why such early-bird tickets exist. By adopting a greedy forward selection pruning strategy, we directly connect the pruned network's performance to the loss of the dense network from which it was derived, revealing a threshold in the number of pre-training iterations beyond which high-performing subnetworks are guaranteed to exist. We demonstrate the validity of our theoretical results across a variety of architectures and datasets, including multi-layer perceptrons (MLPs) trained on MNIST and several deep convolutional neural network (CNN) architectures trained on CIFAR10 and ImageNet.
Exceeding the Limits of Visual-Linguistic Multi-Task Learning
Jul 27, 2021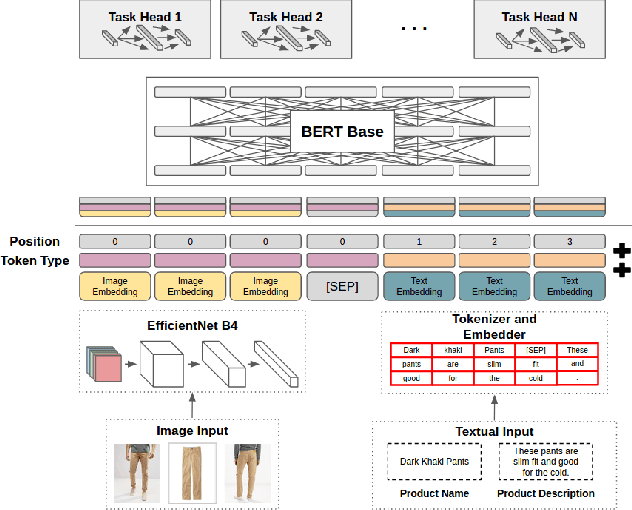
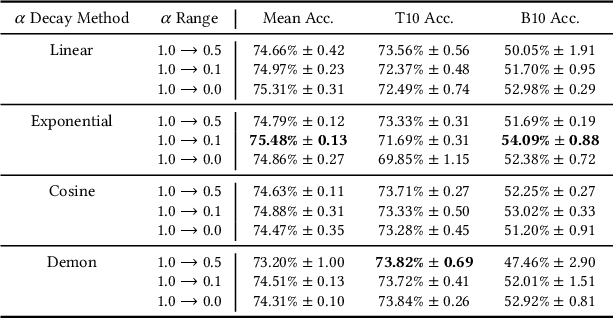
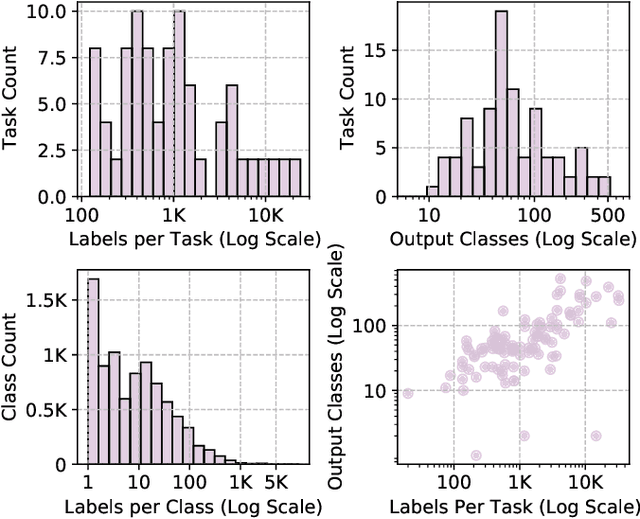
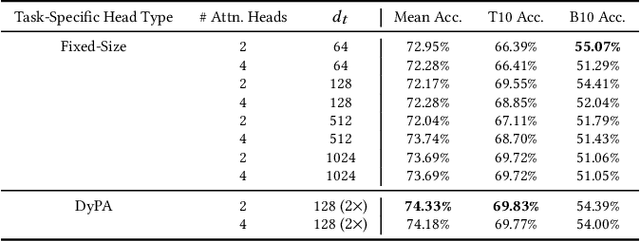
By leveraging large amounts of product data collected across hundreds of live e-commerce websites, we construct 1000 unique classification tasks that share similarly-structured input data, comprised of both text and images. These classification tasks focus on learning the product hierarchy of different e-commerce websites, causing many of them to be correlated. Adopting a multi-modal transformer model, we solve these tasks in unison using multi-task learning (MTL). Extensive experiments are presented over an initial 100-task dataset to reveal best practices for "large-scale MTL" (i.e., MTL with more than 100 tasks). From these experiments, a final, unified methodology is derived, which is composed of both best practices and new proposals such as DyPa, a simple heuristic for automatically allocating task-specific parameters to tasks that could benefit from extra capacity. Using our large-scale MTL methodology, we successfully train a single model across all 1000 tasks in our dataset while using minimal task specific parameters, thereby showing that it is possible to extend several orders of magnitude beyond current efforts in MTL.
ResIST: Layer-Wise Decomposition of ResNets for Distributed Training
Jul 02, 2021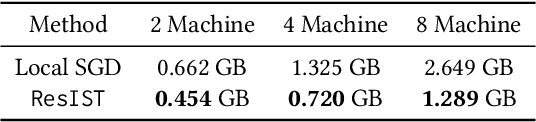
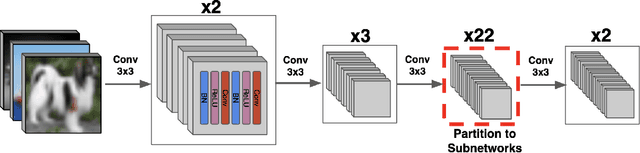
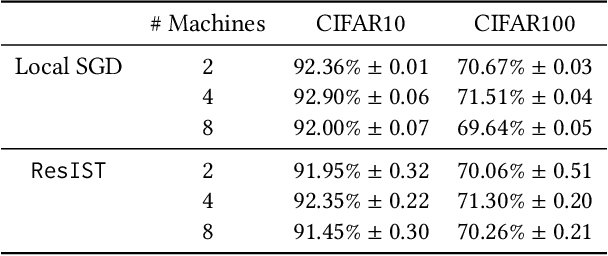
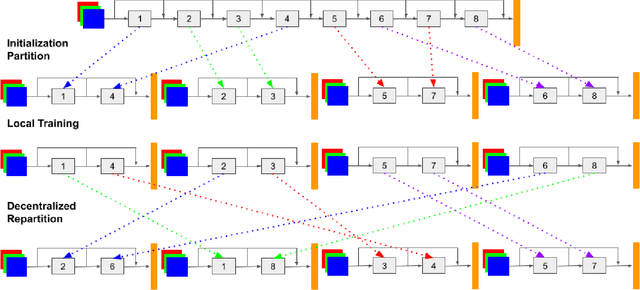
We propose {\rm \texttt{ResIST}}, a novel distributed training protocol for Residual Networks (ResNets). {\rm \texttt{ResIST}} randomly decomposes a global ResNet into several shallow sub-ResNets that are trained independently in a distributed manner for several local iterations, before having their updates synchronized and aggregated into the global model. In the next round, new sub-ResNets are randomly generated and the process repeats. By construction, per iteration, {\rm \texttt{ResIST}} communicates only a small portion of network parameters to each machine and never uses the full model during training. Thus, {\rm \texttt{ResIST}} reduces the communication, memory, and time requirements of ResNet training to only a fraction of the requirements of previous methods. In comparison to common protocols like data-parallel training and data-parallel training with local SGD, {\rm \texttt{ResIST}} yields a decrease in wall-clock training time, while being competitive with respect to model performance.
GIST: Distributed Training for Large-Scale Graph Convolutional Networks
Feb 20, 2021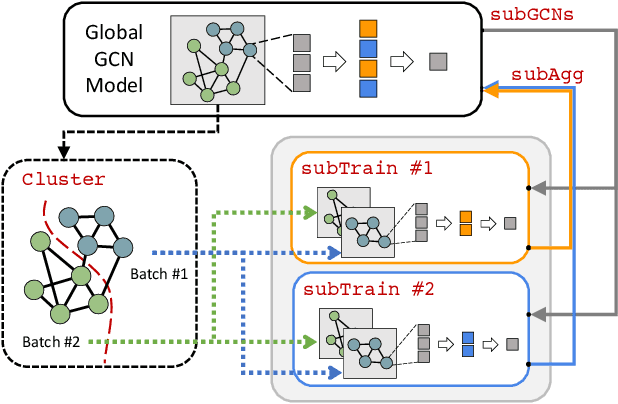
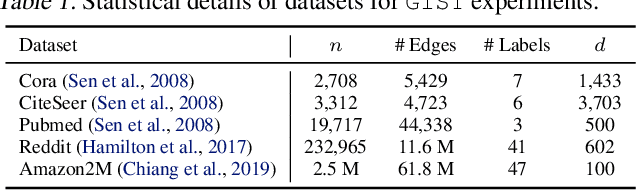
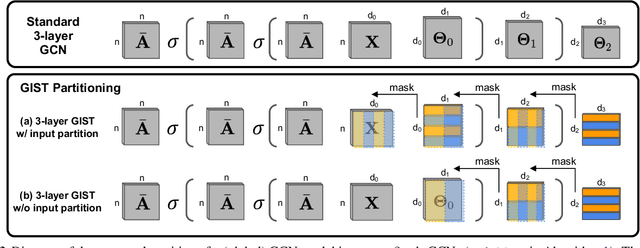
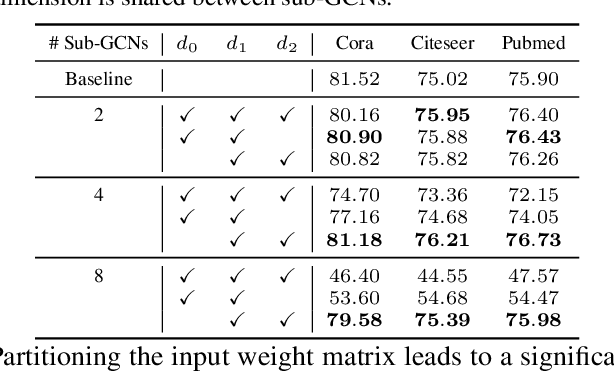
The graph convolutional network (GCN) is a go-to solution for machine learning on graphs, but its training is notoriously difficult to scale in terms of both the size of the graph and the number of model parameters. These limitations are in stark contrast to the increasing scale (in data size and model size) of experiments in deep learning research. In this work, we propose GIST, a novel distributed approach that enables efficient training of wide (overparameterized) GCNs on large graphs. GIST is a hybrid layer and graph sampling method, which disjointly partitions the global model into several, smaller sub-GCNs that are independently trained across multiple GPUs in parallel. This distributed framework improves model performance and significantly decreases wall-clock training time. GIST seeks to enable large-scale GCN experimentation with the goal of bridging the existing gap in scale between graph machine learning and deep learning.
Data Augmentation for Deep Transfer Learning
Nov 28, 2019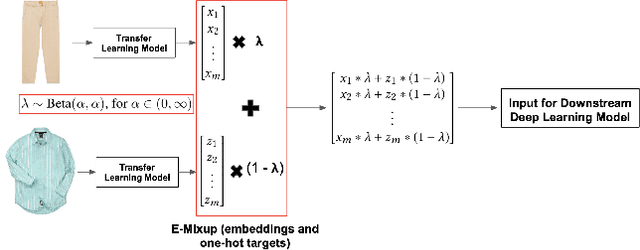
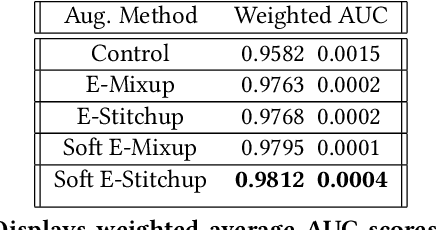
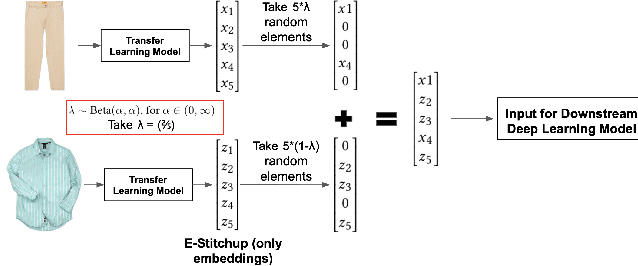
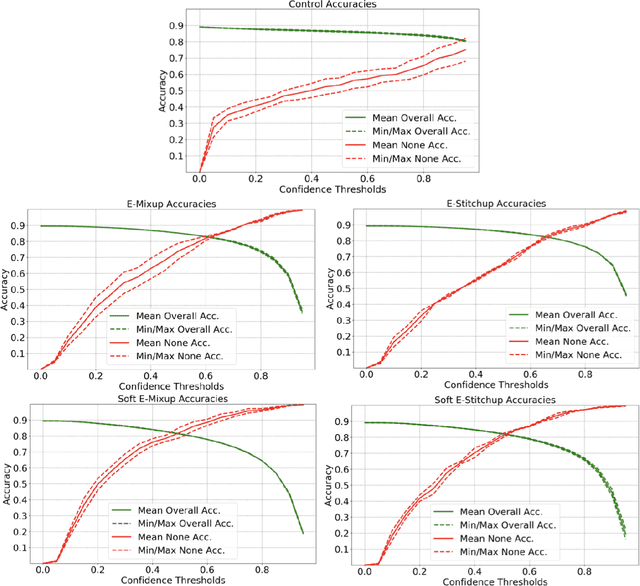
Current approaches to deep learning are beginning to rely heavily on transfer learning as an effective method for reducing overfitting, improving model performance, and quickly learning new tasks. Similarly, such pre-trained models are often used to create embedding representations for various types of data, such as text and images, which can then be fed as input into separate, downstream models. However, in cases where such transfer learning models perform poorly (i.e., for data outside of the training distribution), one must resort to fine-tuning such models, or even retraining them completely. Currently, no form of data augmentation has been proposed that can be applied directly to embedding inputs to improve downstream model performance. In this work, we introduce four new types of data augmentation that are generally applicable to embedding inputs, thus making them useful in both Natural Language Processing (NLP) and Computer Vision (CV) applications. For models trained on downstream tasks with such embedding inputs, these augmentation methods are shown to improve the AUC score of the models from a score of 0.9582 to 0.9812 and significantly increase the model's ability to identify classes of data that are not seen during training.
Functional Generative Design of Mechanisms with Recurrent Neural Networks and Novelty Search
Mar 25, 2019
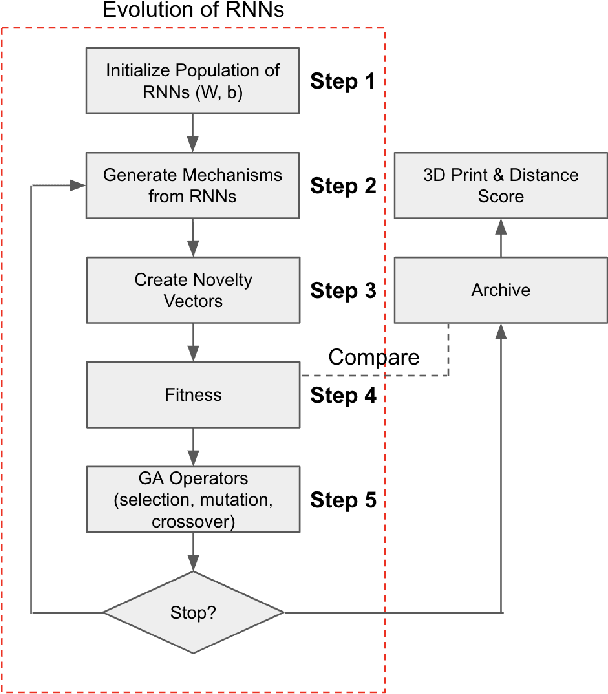
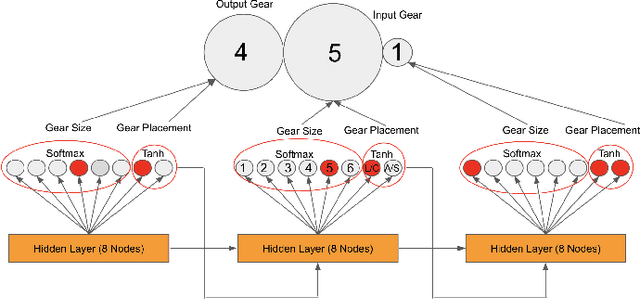

Consumer-grade 3D printers have made it easier to fabricate aesthetic objects and static assemblies, opening the door to automated design of such objects. However, while static designs are easily produced with 3D printing, functional designs with moving parts are more difficult to generate: The search space is too high-dimensional, the resolution of the 3D-printed parts is not adequate, and it is difficult to predict the physical behavior of imperfect 3D-printed mechanisms. An example challenge is to produce a diverse set of reliable and effective gear mechanisms that could be used after production without extensive post-processing. To meet this challenge, an indirect encoding based on a Recurrent Neural Network (RNN) is created and evolved using novelty search. The elite solutions of each generation are 3D printed to evaluate their functional performance on a physical test platform. The system is able to discover sequential design rules that are difficult to discover with other methods. Compared to direct encoding evolved with Genetic Algorithms (GAs), its designs are geometrically more diverse and functionally more effective. It therefore forms a promising foundation for the generative design of 3D-printed, functional mechanisms.