 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResIST: Layer-Wise Decomposition of ResNets for Distributed Training
Paper and Code
Jul 02, 2021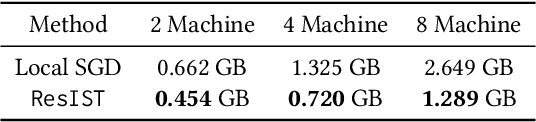
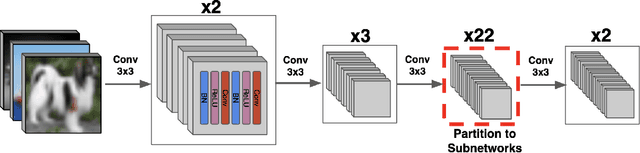
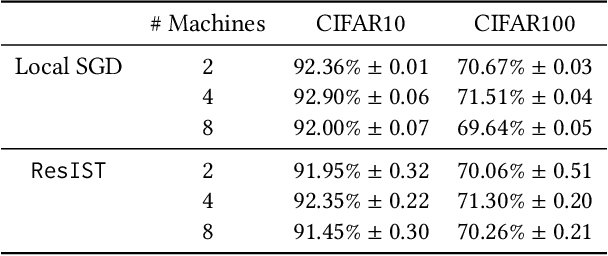
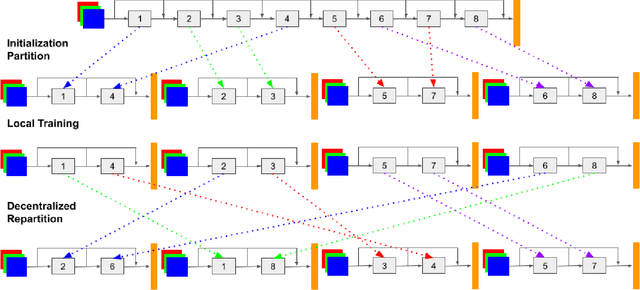
We propose {\rm \texttt{ResIST}}, a novel distributed training protocol for Residual Networks (ResNets). {\rm \texttt{ResIST}} randomly decomposes a global ResNet into several shallow sub-ResNets that are trained independently in a distributed manner for several local iterations, before having their updates synchronized and aggregated into the global model. In the next round, new sub-ResNets are randomly generated and the process repeats. By construction, per iteration, {\rm \texttt{ResIST}} communicates only a small portion of network parameters to each machine and never uses the full model during training. Thus, {\rm \texttt{ResIST}} reduces the communication, memory, and time requirements of ResNet training to only a fraction of the requirements of previous methods. In comparison to common protocols like data-parallel training and data-parallel training with local SGD, {\rm \texttt{ResIST}} yields a decrease in wall-clock training time, while being competitive with respect to model performance.