 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSciDA: Scientific Dynamic Assessor of LLMs
Jun 15, 2025Advancement in Large Language Models (LLMs) reasoning capabilities enables them to solve scientific problems with enhanced efficacy. Thereby, a high-quality benchmark for comprehensive and appropriate assessment holds significance, while existing ones either confront the risk of data contamination or lack involved disciplines. To be specific, due to the data source overlap of LLMs training and static benchmark, the keys or number pattern of answers inadvertently memorized (i.e. data contamination), leading to systematic overestimation of their reasoning capabilities, especially numerical reasoning. We propose SciDA, a multidisciplinary benchmark that consists exclusively of over 1k Olympic-level numerical computation problems, allowing randomized numerical initializations for each inference round to avoid reliance on fixed numerical patterns. We conduct a series of experiments with both closed-source and open-source top-performing LLMs, and it is observed that the performance of LLMs drop significantly under random numerical initialization. Thus, we provide truthful and unbiased assessments of the numerical reasoning capabilities of LLMs. The data is available at https://huggingface.co/datasets/m-a-p/SciDA
Flaming-hot Initiation with Regular Execution Sampling for Large Language Models
Oct 28, 2024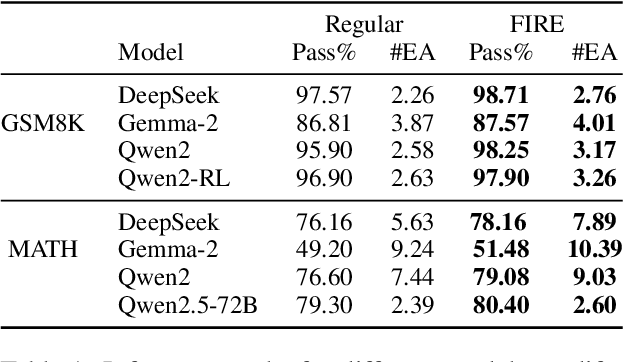


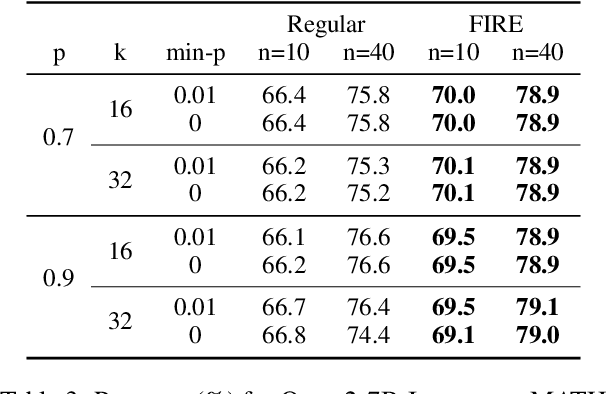
Since the release of ChatGPT, large language models (LLMs) have demonstrated remarkable capabilities across various domains. A key challenge in developing these general capabilities is efficiently sourcing diverse, high-quality data. This becomes especially critical in reasoning-related tasks with sandbox checkers, such as math or code, where the goal is to generate correct solutions to specific problems with higher probability. In this work, we introduce Flaming-hot Initiation with Regular Execution (FIRE) sampling, a simple yet highly effective method to efficiently find good responses. Our empirical findings show that FIRE sampling enhances inference-time generation quality and also benefits training in the alignment stage. Furthermore, we explore how FIRE sampling improves performance by promoting diversity and analyze the impact of employing FIRE at different positions within a response.
Process Supervision-Guided Policy Optimization for Code Generation
Oct 23, 2024
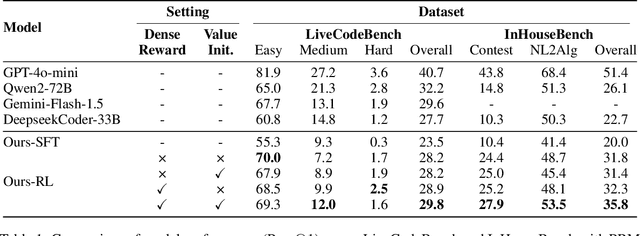

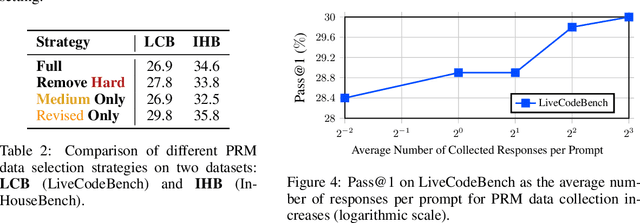
Reinforcement Learning (RL) with unit test feedback has enhanced large language models (LLMs) code generation, but relies on sparse rewards provided only after complete code evaluation, limiting learning efficiency and incremental improvements. When generated code fails all unit tests, no learning signal is received, hindering progress on complex tasks. To address this, we propose a Process Reward Model (PRM) that delivers dense, line-level feedback on code correctness during generation, mimicking human code refinement and providing immediate guidance. We explore various strategies for training PRMs and integrating them into the RL framework, finding that using PRMs both as dense rewards and for value function initialization significantly boosts performance. Our approach increases our in-house LLM's pass rate from 28.2% to 29.8% on LiveCodeBench and from 31.8% to 35.8% on our internal benchmark. Our experimental results highlight the effectiveness of PRMs in enhancing RL-driven code generation, especially for long-horizon scenarios.
Enhancing Multi-Step Reasoning Abilities of Language Models through Direct Q-Function Optimization
Oct 11, 2024



Reinforcement Learning (RL) plays a crucial role in aligning large language models (LLMs) with human preferences and improving their ability to perform complex tasks. However, current approaches either require significant computational resources due to the use of multiple models and extensive online sampling for training (e.g., PPO) or are framed as bandit problems (e.g., DPO, DRO), which often struggle with multi-step reasoning tasks, such as math problem-solving and complex reasoning that involve long chains of thought. To overcome these limitations, we introduce Direct Q-function Optimization (DQO), which formulates the response generation process as a Markov Decision Process (MDP) and utilizes the soft actor-critic (SAC) framework to optimize a Q-function directly parameterized by the language model. The MDP formulation of DQO offers structural advantages over bandit-based methods, enabling more effective process supervision. Experimental results on two math problem-solving datasets, GSM8K and MATH, demonstrate that DQO outperforms previous methods, establishing it as a promising offline reinforcement learning approach for aligning language models.
CrysFormer: Protein Structure Prediction via 3d Patterson Maps and Partial Structure Attention
Oct 05, 2023



Determining the structure of a protein has been a decades-long open question. A protein's three-dimensional structure often poses nontrivial computation costs, when classical simulation algorithms are utilized. Advances in the transformer neural network architecture -- such as AlphaFold2 -- achieve significant improvements for this problem, by learning from a large dataset of sequence information and corresponding protein structures. Yet, such methods only focus on sequence information; other available prior knowledge, such as protein crystallography and partial structure of amino acids, could be potentially utilized. To the best of our knowledge, we propose the first transformer-based model that directly utilizes protein crystallography and partial structure information to predict the electron density maps of proteins. Via two new datasets of peptide fragments (2-residue and 15-residue) , we demonstrate our method, dubbed \texttt{CrysFormer}, can achieve accurate predictions, based on a much smaller dataset size and with reduced computation costs.
Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation
Oct 05, 2023

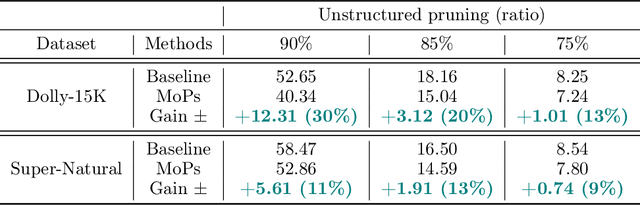
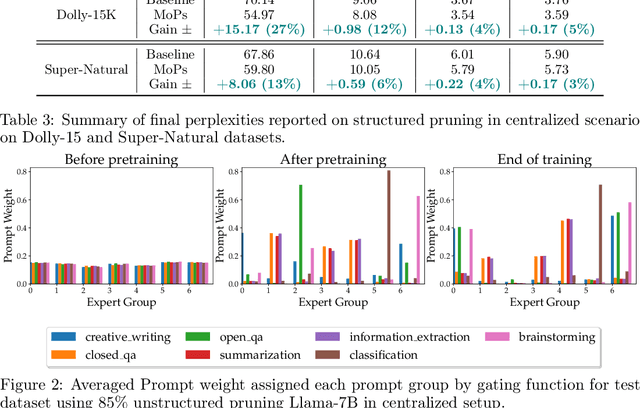
Large Language Models (LLMs) have the ability to solve a variety of tasks, such as text summarization and mathematical questions, just out of the box, but they are often trained with a single task in mind. Due to high computational costs, the current trend is to use prompt instruction tuning to better adjust monolithic, pretrained LLMs for new -- but often individual -- downstream tasks. Thus, how one would expand prompt tuning to handle -- concomitantly -- heterogeneous tasks and data distributions is a widely open question. To address this gap, we suggest the use of \emph{Mixture of Prompts}, or MoPs, associated with smart gating functionality: the latter -- whose design is one of the contributions of this paper -- can identify relevant skills embedded in different groups of prompts and dynamically assign combined experts (i.e., collection of prompts), based on the target task. Additionally, MoPs are empirically agnostic to any model compression technique applied -- for efficiency reasons -- as well as instruction data source and task composition. In practice, MoPs can simultaneously mitigate prompt training "interference" in multi-task, multi-source scenarios (e.g., task and data heterogeneity across sources), as well as possible implications from model approximations. As a highlight, MoPs manage to decrease final perplexity from $\sim20\%$ up to $\sim70\%$, as compared to baselines, in the federated scenario, and from $\sim 3\%$ up to $\sim30\%$ in the centralized scenario.
Fast FixMatch: Faster Semi-Supervised Learning with Curriculum Batch Size
Sep 07, 2023Advances in Semi-Supervised Learning (SSL) have almost entirely closed the gap between SSL and Supervised Learning at a fraction of the number of labels. However, recent performance improvements have often come \textit{at the cost of significantly increased training computation}. To address this, we propose Curriculum Batch Size (CBS), \textit{an unlabeled batch size curriculum which exploits the natural training dynamics of deep neural networks.} A small unlabeled batch size is used in the beginning of training and is gradually increased to the end of training. A fixed curriculum is used regardless of dataset, model or number of epochs, and reduced training computations is demonstrated on all settings. We apply CBS, strong labeled augmentation, Curriculum Pseudo Labeling (CPL) \citep{FlexMatch} to FixMatch \citep{FixMatch} and term the new SSL algorithm Fast FixMatch. We perform an ablation study to show that strong labeled augmentation and/or CPL do not significantly reduce training computations, but, in synergy with CBS, they achieve optimal performance. Fast FixMatch also achieves substantially higher data utilization compared to previous state-of-the-art. Fast FixMatch achieves between $2.1\times$ - $3.4\times$ reduced training computations on CIFAR-10 with all but 40, 250 and 4000 labels removed, compared to vanilla FixMatch, while attaining the same cited state-of-the-art error rate \citep{FixMatch}. Similar results are achieved for CIFAR-100, SVHN and STL-10. Finally, Fast MixMatch achieves between $2.6\times$ - $3.3\times$ reduced training computations in federated SSL tasks and online/streaming learning SSL tasks, which further demonstrate the generializbility of Fast MixMatch to different scenarios and tasks.
Fed-ZERO: Efficient Zero-shot Personalization with Federated Mixture of Experts
Jun 14, 2023



One of the goals in Federated Learning (FL) is to create personalized models that can adapt to the context of each participating client, while utilizing knowledge from a shared global model. Yet, often, personalization requires a fine-tuning step using clients' labeled data in order to achieve good performance. This may not be feasible in scenarios where incoming clients are fresh and/or have privacy concerns. It, then, remains open how one can achieve zero-shot personalization in these scenarios. We propose a novel solution by using a Mixture-of-Experts (MoE) framework within a FL setup. Our method leverages the diversity of the clients to train specialized experts on different subsets of classes, and a gating function to route the input to the most relevant expert(s). Our gating function harnesses the knowledge of a pretrained model common expert to enhance its routing decisions on-the-fly. As a highlight, our approach can improve accuracy up to 18\% in state of the art FL settings, while maintaining competitive zero-shot performance. In practice, our method can handle non-homogeneous data distributions, scale more efficiently, and improve the state-of-the-art performance on common FL benchmarks.
LOFT: Finding Lottery Tickets through Filter-wise Training
Oct 28, 2022
Recent work on the Lottery Ticket Hypothesis (LTH) shows that there exist ``\textit{winning tickets}'' in large neural networks. These tickets represent ``sparse'' versions of the full model that can be trained independently to achieve comparable accuracy with respect to the full model. However, finding the winning tickets requires one to \emph{pretrain} the large model for at least a number of epochs, which can be a burdensome task, especially when the original neural network gets larger. In this paper, we explore how one can efficiently identify the emergence of such winning tickets, and use this observation to design efficient pretraining algorithms. For clarity of exposition, our focus is on convolutional neural networks (CNNs). To identify good filters, we propose a novel filter distance metric that well-represents the model convergence. As our theory dictates, our filter analysis behaves consistently with recent findings of neural network learning dynamics. Motivated by these observations, we present the \emph{LOttery ticket through Filter-wise Training} algorithm, dubbed as \textsc{LoFT}. \textsc{LoFT} is a model-parallel pretraining algorithm that partitions convolutional layers by filters to train them independently in a distributed setting, resulting in reduced memory and communication costs during pretraining. Experiments show that \textsc{LoFT} $i)$ preserves and finds good lottery tickets, while $ii)$ it achieves non-trivial computation and communication savings, and maintains comparable or even better accuracy than other pretraining methods.
Efficient and Light-Weight Federated Learning via Asynchronous Distributed Dropout
Oct 28, 2022


Asynchronous learning protocols have regained attention lately, especially in the Federated Learning (FL) setup, where slower clients can severely impede the learning process. Herein, we propose \texttt{AsyncDrop}, a novel asynchronous FL framework that utilizes dropout regularization to handle device heterogeneity in distributed settings. Overall, \texttt{AsyncDrop} achieves better performance compared to state of the art asynchronous methodologies, while resulting in less communication and training time overheads. The key idea revolves around creating ``submodels'' out of the global model, and distributing their training to workers, based on device heterogeneity. We rigorously justify that such an approach can be theoretically characterized. We implement our approach and compare it against other asynchronous baselines, both by design and by adapting existing synchronous FL algorithms to asynchronous scenarios. Empirically, \texttt{AsyncDrop} reduces the communication cost and training time, while matching or improving the final test accuracy in diverse non-i.i.d. FL scenarios.