 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation
Paper and Code
Oct 05, 2023

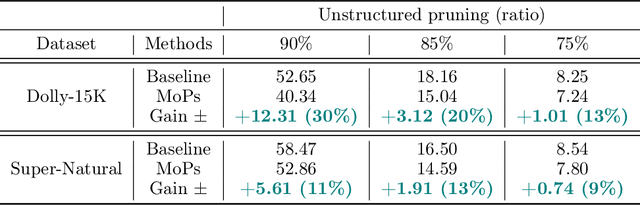
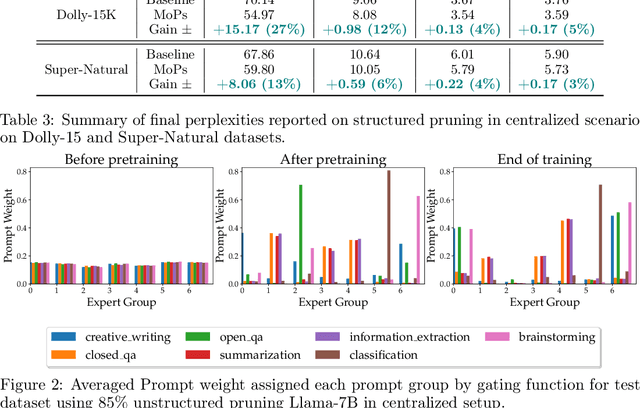
Large Language Models (LLMs) have the ability to solve a variety of tasks, such as text summarization and mathematical questions, just out of the box, but they are often trained with a single task in mind. Due to high computational costs, the current trend is to use prompt instruction tuning to better adjust monolithic, pretrained LLMs for new -- but often individual -- downstream tasks. Thus, how one would expand prompt tuning to handle -- concomitantly -- heterogeneous tasks and data distributions is a widely open question. To address this gap, we suggest the use of \emph{Mixture of Prompts}, or MoPs, associated with smart gating functionality: the latter -- whose design is one of the contributions of this paper -- can identify relevant skills embedded in different groups of prompts and dynamically assign combined experts (i.e., collection of prompts), based on the target task. Additionally, MoPs are empirically agnostic to any model compression technique applied -- for efficiency reasons -- as well as instruction data source and task composition. In practice, MoPs can simultaneously mitigate prompt training "interference" in multi-task, multi-source scenarios (e.g., task and data heterogeneity across sources), as well as possible implications from model approximations. As a highlight, MoPs manage to decrease final perplexity from $\sim20\%$ up to $\sim70\%$, as compared to baselines, in the federated scenario, and from $\sim 3\%$ up to $\sim30\%$ in the centralized scenario.