 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemora: A Harmonic Memory Representation Balancing Abstraction and Specificity
Feb 03, 2026Agent memory systems must accommodate continuously growing information while supporting efficient, context-aware retrieval for downstream tasks. Abstraction is essential for scaling agent memory, yet it often comes at the cost of specificity, obscuring the fine-grained details required for effective reasoning. We introduce Memora, a harmonic memory representation that structurally balances abstraction and specificity. Memora organizes information via its primary abstractions that index concrete memory values and consolidate related updates into unified memory entries, while cue anchors expand retrieval access across diverse aspects of the memory and connect related memories. Building on this structure, we employ a retrieval policy that actively exploits these memory connections to retrieve relevant information beyond direct semantic similarity. Theoretically, we show that standard Retrieval-Augmented Generation (RAG) and Knowledge Graph (KG)-based memory systems emerge as special cases of our framework. Empirically, Memora establishes a new state-of-the-art on the LoCoMo and LongMemEval benchmarks, demonstrating better retrieval relevance and reasoning effectiveness as memory scales.
ACON: Optimizing Context Compression for Long-horizon LLM Agents
Oct 01, 2025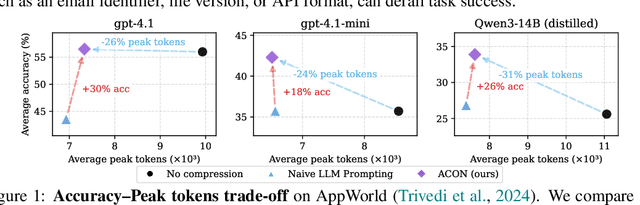
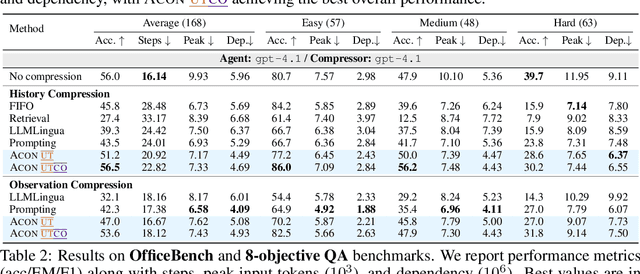
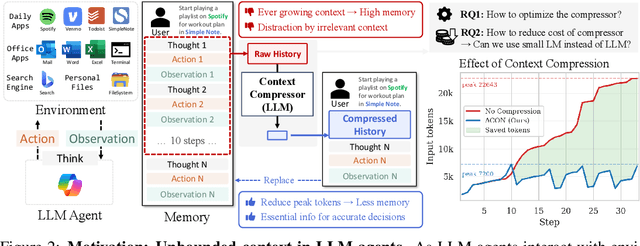
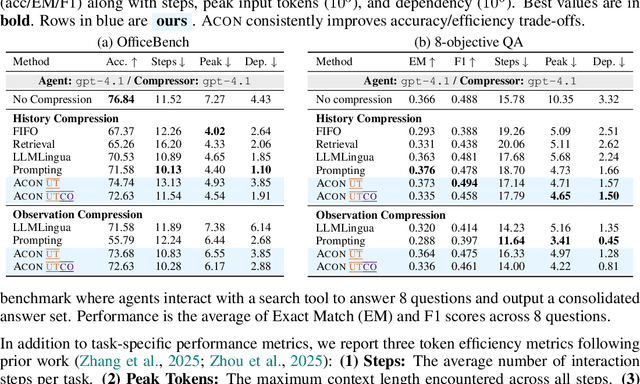
Large language models (LLMs) are increasingly deployed as agents in dynamic, real-world environments, where success requires both reasoning and effective tool use. A central challenge for agentic tasks is the growing context length, as agents must accumulate long histories of actions and observations. This expansion raises costs and reduces efficiency in long-horizon tasks, yet prior work on context compression has mostly focused on single-step tasks or narrow applications. We introduce Agent Context Optimization (ACON), a unified framework that optimally compresses both environment observations and interaction histories into concise yet informative condensations. ACON leverages compression guideline optimization in natural language space: given paired trajectories where full context succeeds but compressed context fails, capable LLMs analyze the causes of failure, and the compression guideline is updated accordingly. Furthermore, we propose distilling the optimized LLM compressor into smaller models to reduce the overhead of the additional module. Experiments on AppWorld, OfficeBench, and Multi-objective QA show that ACON reduces memory usage by 26-54% (peak tokens) while largely preserving task performance, preserves over 95% of accuracy when distilled into smaller compressors, and enhances smaller LMs as long-horizon agents with up to 46% performance improvement.
Exploring How LLMs Capture and Represent Domain-Specific Knowledge
Apr 24, 2025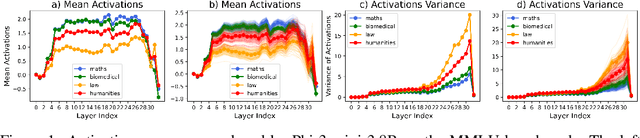

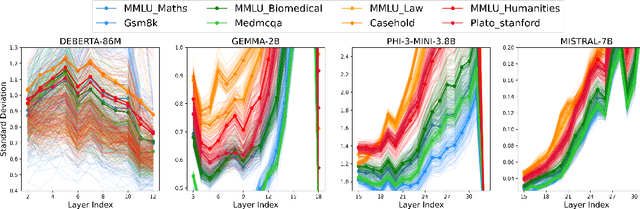

We study whether Large Language Models (LLMs) inherently capture domain-specific nuances in natural language. Our experiments probe the domain sensitivity of LLMs by examining their ability to distinguish queries from different domains using hidden states generated during the prefill phase. We reveal latent domain-related trajectories that indicate the model's internal recognition of query domains. We also study the robustness of these domain representations to variations in prompt styles and sources. Our approach leverages these representations for model selection, mapping the LLM that best matches the domain trace of the input query (i.e., the model with the highest performance on similar traces). Our findings show that LLMs can differentiate queries for related domains, and that the fine-tuned model is not always the most accurate. Unlike previous work, our interpretations apply to both closed and open-ended generative tasks
Controllable Synthetic Clinical Note Generation with Privacy Guarantees
Sep 12, 2024



In the field of machine learning, domain-specific annotated data is an invaluable resource for training effective models. However, in the medical domain, this data often includes Personal Health Information (PHI), raising significant privacy concerns. The stringent regulations surrounding PHI limit the availability and sharing of medical datasets, which poses a substantial challenge for researchers and practitioners aiming to develop advanced machine learning models. In this paper, we introduce a novel method to "clone" datasets containing PHI. Our approach ensures that the cloned datasets retain the essential characteristics and utility of the original data without compromising patient privacy. By leveraging differential-privacy techniques and a novel fine-tuning task, our method produces datasets that are free from identifiable information while preserving the statistical properties necessary for model training. We conduct utility testing to evaluate the performance of machine learning models trained on the cloned datasets. The results demonstrate that our cloned datasets not only uphold privacy standards but also enhance model performance compared to those trained on traditional anonymized datasets. This work offers a viable solution for the ethical and effective utilization of sensitive medical data in machine learning, facilitating progress in medical research and the development of robust predictive models.
Hybrid LLM: Cost-Efficient and Quality-Aware Query Routing
Apr 22, 2024Large language models (LLMs) excel in most NLP tasks but also require expensive cloud servers for deployment due to their size, while smaller models that can be deployed on lower cost (e.g., edge) devices, tend to lag behind in terms of response quality. Therefore in this work we propose a hybrid inference approach which combines their respective strengths to save cost and maintain quality. Our approach uses a router that assigns queries to the small or large model based on the predicted query difficulty and the desired quality level. The desired quality level can be tuned dynamically at test time to seamlessly trade quality for cost as per the scenario requirements. In experiments our approach allows us to make up to 40% fewer calls to the large model, with no drop in response quality.
Differentially Private Training of Mixture of Experts Models
Feb 11, 2024

This position paper investigates the integration of Differential Privacy (DP) in the training of Mixture of Experts (MoE) models within the field of natural language processing. As Large Language Models (LLMs) scale to billions of parameters, leveraging expansive datasets, they exhibit enhanced linguistic capabilities and emergent abilities. However, this growth raises significant computational and privacy concerns. Our study addresses these issues by exploring the potential of MoE models, known for their computational efficiency, and the application of DP, a standard for privacy preservation. We present the first known attempt to train MoE models under the constraints of DP, addressing the unique challenges posed by their architecture and the complexities of DP integration. Our initial experimental studies demonstrate that MoE models can be effectively trained with DP, achieving performance that is competitive with their non-private counterparts. This initial study aims to provide valuable insights and ignite further research in the domain of privacy-preserving MoE models, softly laying the groundwork for prospective developments in this evolving field.
Privately Aligning Language Models with Reinforcement Learning
Oct 25, 2023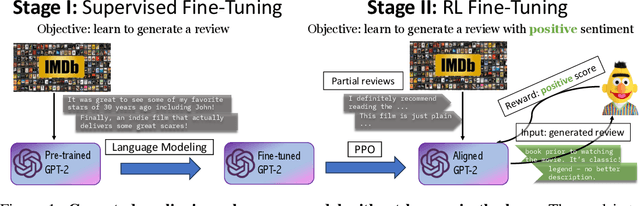
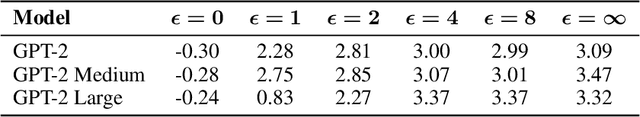

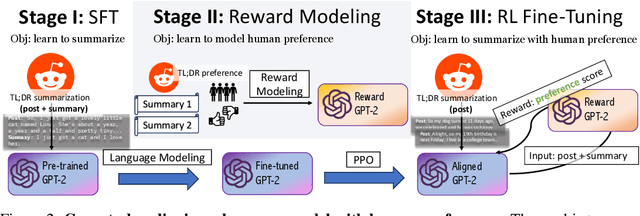
Positioned between pre-training and user deployment, aligning large language models (LLMs) through reinforcement learning (RL) has emerged as a prevailing strategy for training instruction following-models such as ChatGPT. In this work, we initiate the study of privacy-preserving alignment of LLMs through Differential Privacy (DP) in conjunction with RL. Following the influential work of Ziegler et al. (2020), we study two dominant paradigms: (i) alignment via RL without human in the loop (e.g., positive review generation) and (ii) alignment via RL from human feedback (RLHF) (e.g., summarization in a human-preferred way). We give a new DP framework to achieve alignment via RL, and prove its correctness. Our experimental results validate the effectiveness of our approach, offering competitive utility while ensuring strong privacy protections.
Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation
Oct 05, 2023

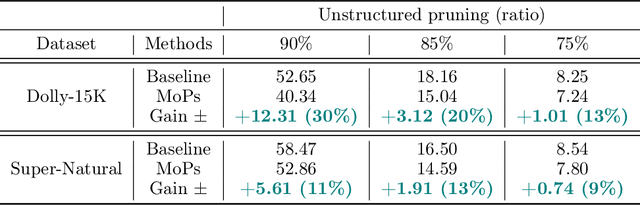
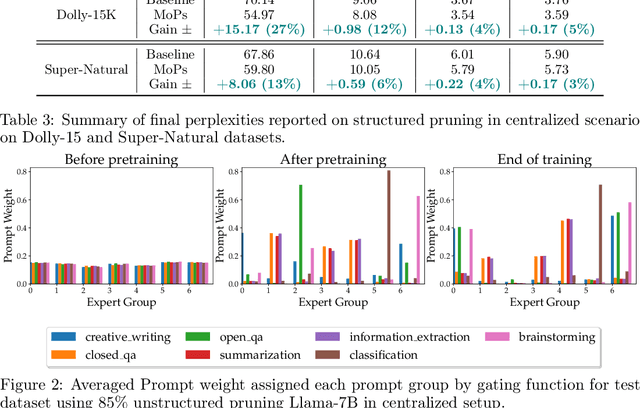
Large Language Models (LLMs) have the ability to solve a variety of tasks, such as text summarization and mathematical questions, just out of the box, but they are often trained with a single task in mind. Due to high computational costs, the current trend is to use prompt instruction tuning to better adjust monolithic, pretrained LLMs for new -- but often individual -- downstream tasks. Thus, how one would expand prompt tuning to handle -- concomitantly -- heterogeneous tasks and data distributions is a widely open question. To address this gap, we suggest the use of \emph{Mixture of Prompts}, or MoPs, associated with smart gating functionality: the latter -- whose design is one of the contributions of this paper -- can identify relevant skills embedded in different groups of prompts and dynamically assign combined experts (i.e., collection of prompts), based on the target task. Additionally, MoPs are empirically agnostic to any model compression technique applied -- for efficiency reasons -- as well as instruction data source and task composition. In practice, MoPs can simultaneously mitigate prompt training "interference" in multi-task, multi-source scenarios (e.g., task and data heterogeneity across sources), as well as possible implications from model approximations. As a highlight, MoPs manage to decrease final perplexity from $\sim20\%$ up to $\sim70\%$, as compared to baselines, in the federated scenario, and from $\sim 3\%$ up to $\sim30\%$ in the centralized scenario.
Privacy-Preserving In-Context Learning with Differentially Private Few-Shot Generation
Sep 21, 2023



We study the problem of in-context learning (ICL) with large language models (LLMs) on private datasets. This scenario poses privacy risks, as LLMs may leak or regurgitate the private examples demonstrated in the prompt. We propose a novel algorithm that generates synthetic few-shot demonstrations from the private dataset with formal differential privacy (DP) guarantees, and show empirically that it can achieve effective ICL. We conduct extensive experiments on standard benchmarks and compare our algorithm with non-private ICL and zero-shot solutions. Our results demonstrate that our algorithm can achieve competitive performance with strong privacy levels. These results open up new possibilities for ICL with privacy protection for a broad range of applications.
Project Florida: Federated Learning Made Easy
Jul 21, 2023
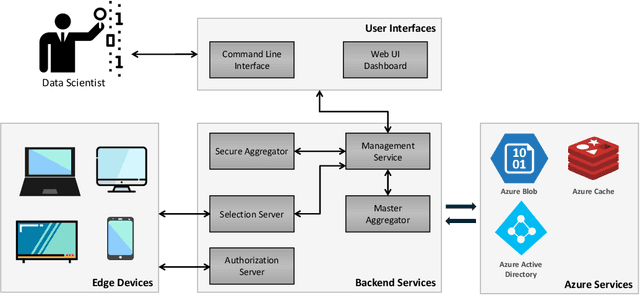

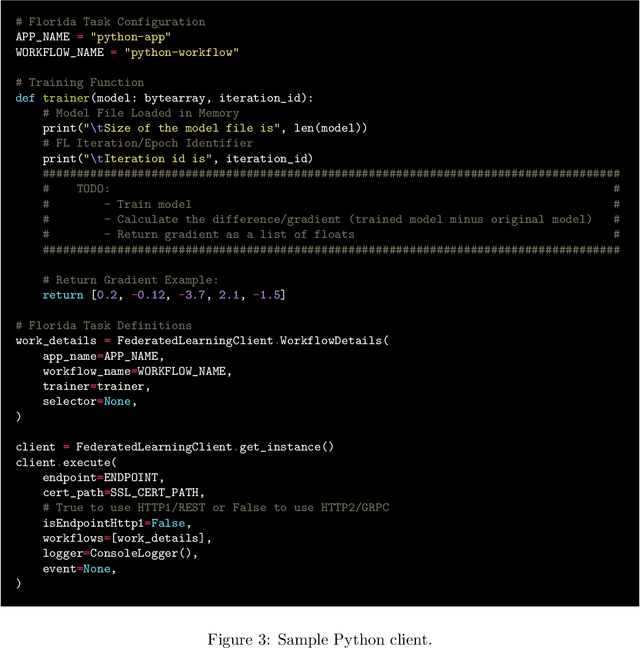
We present Project Florida, a system architecture and software development kit (SDK) enabling deployment of large-scale Federated Learning (FL) solutions across a heterogeneous device ecosystem. Federated learning is an approach to machine learning based on a strong data sovereignty principle, i.e., that privacy and security of data is best enabled by storing it at its origin, whether on end-user devices or in segregated cloud storage silos. Federated learning enables model training across devices and silos while the training data remains within its security boundary, by distributing a model snapshot to a client running inside the boundary, running client code to update the model, and then aggregating updated snapshots across many clients in a central orchestrator. Deploying a FL solution requires implementation of complex privacy and security mechanisms as well as scalable orchestration infrastructure. Scale and performance is a paramount concern, as the model training process benefits from full participation of many client devices, which may have a wide variety of performance characteristics. Project Florida aims to simplify the task of deploying cross-device FL solutions by providing cloud-hosted infrastructure and accompanying task management interfaces, as well as a multi-platform SDK supporting most major programming languages including C++, Java, and Python, enabling FL training across a wide range of operating system (OS) and hardware specifications. The architecture decouples service management from the FL workflow, enabling a cloud service provider to deliver FL-as-a-service (FLaaS) to ML engineers and application developers. We present an overview of Florida, including a description of the architecture, sample code, and illustrative experiments demonstrating system capabilities.