 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEngineering Robustness into Personal Agents with the AI Workflow Store
May 11, 2026The dominant paradigm for AI agents is an "on-the-fly" loop in which agents synthesize plans and execute actions within seconds or minutes in response to user prompts. We argue that this paradigm short-circuits disciplined software engineering (SE) processes -- iterative design, rigorous testing, adversarial evaluation, staged deployment, and more -- that have delivered the (relatively) reliable and secure systems we use today. By focusing on rapid, real-time synthesis, are AI agents effectively delivering users improvised prototypes rather than systems fit for high-stakes scenarios in which users may unwittingly apply them? This paper argues for the need to integrate rigorous SE processes into the agentic loop to produce production-grade, hardened, and deterministically-constrained agent *workflows* that substantially outperform the potentially brittle and vulnerable results of on-the-fly synthesis. Doing so may require extra compute and time, and if so, we must amortize the cost of rigor through reuse across a broad user community. We envision an *AI Workflow Store* that consists of hardened and reusable workflows that agents can invoke with far greater reliability and security than improvised tool chains. We outline the research challenges of this vision, which stem from a broader flexibility-robustness tension that we argue requires moving beyond the ``on-the-fly'' paradigm to navigate effectively.
Differentially Private Training of Mixture of Experts Models
Feb 11, 2024

This position paper investigates the integration of Differential Privacy (DP) in the training of Mixture of Experts (MoE) models within the field of natural language processing. As Large Language Models (LLMs) scale to billions of parameters, leveraging expansive datasets, they exhibit enhanced linguistic capabilities and emergent abilities. However, this growth raises significant computational and privacy concerns. Our study addresses these issues by exploring the potential of MoE models, known for their computational efficiency, and the application of DP, a standard for privacy preservation. We present the first known attempt to train MoE models under the constraints of DP, addressing the unique challenges posed by their architecture and the complexities of DP integration. Our initial experimental studies demonstrate that MoE models can be effectively trained with DP, achieving performance that is competitive with their non-private counterparts. This initial study aims to provide valuable insights and ignite further research in the domain of privacy-preserving MoE models, softly laying the groundwork for prospective developments in this evolving field.
Packing Privacy Budget Efficiently
Dec 26, 2022



Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
Privacy Budget Scheduling
Jun 29, 2021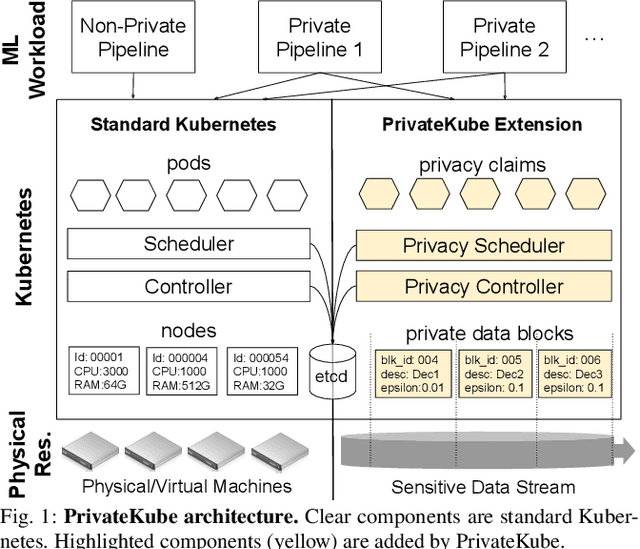
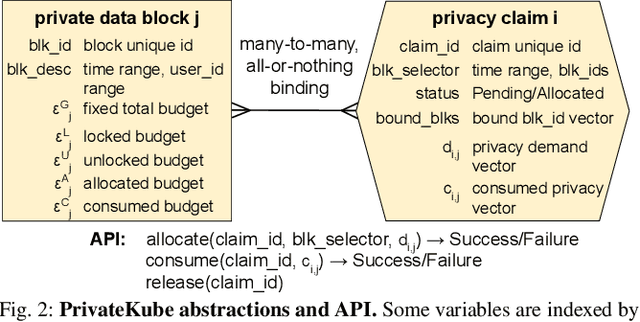
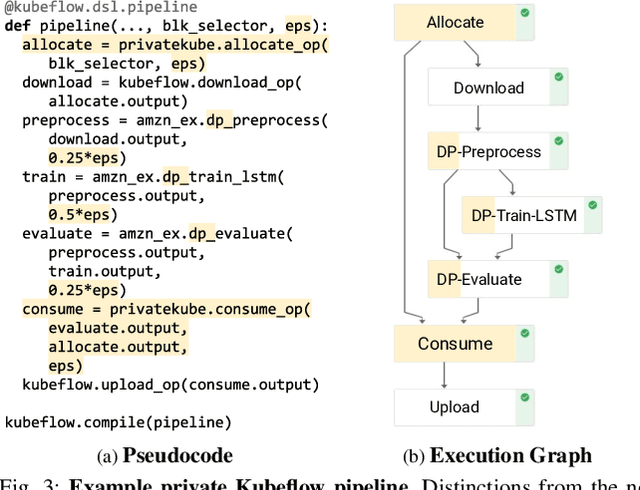
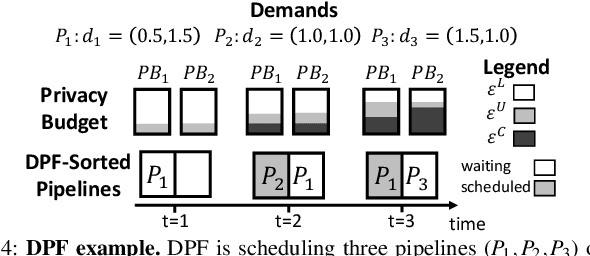
Machine learning (ML) models trained on personal data have been shown to leak information about users. Differential privacy (DP) enables model training with a guaranteed bound on this leakage. Each new model trained with DP increases the bound on data leakage and can be seen as consuming part of a global privacy budget that should not be exceeded. This budget is a scarce resource that must be carefully managed to maximize the number of successfully trained models. We describe PrivateKube, an extension to the popular Kubernetes datacenter orchestrator that adds privacy as a new type of resource to be managed alongside other traditional compute resources, such as CPU, GPU, and memory. The abstractions we design for the privacy resource mirror those defined by Kubernetes for traditional resources, but there are also major differences. For example, traditional compute resources are replenishable while privacy is not: a CPU can be regained after a model finishes execution while privacy budget cannot. This distinction forces a re-design of the scheduler. We present DPF (Dominant Private Block Fairness) -- a variant of the popular Dominant Resource Fairness (DRF) algorithm -- that is geared toward the non-replenishable privacy resource but enjoys similar theoretical properties as DRF. We evaluate PrivateKube and DPF on microbenchmarks and an ML workload on Amazon Reviews data. Compared to existing baselines, DPF allows training more models under the same global privacy guarantee. This is especially true for DPF over R\'enyi DP, a highly composable form of DP.