 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecursive Function Definitions in Static Dataflow Graphs and their Implementation in TensorFlow
Oct 26, 2024Modern machine learning systems represent their computations as dataflow graphs. The increasingly complex neural network architectures crave for more powerful yet efficient programming abstractions. In this paper we propose an efficient technique for supporting recursive function definitions in dataflow-based systems such as TensorFlow. The proposed approach transforms the given recursive definitions into a static dataflow graph that is enriched with two simple yet powerful dataflow operations. Since static graphs do not change during execution, they can be easily partitioned and executed efficiently in distributed and heterogeneous environments. The proposed technique makes heavy use of the idea of tagging, which was one of the cornerstones of dataflow systems since their inception. We demonstrate that our technique is compatible with the idea of automatic differentiation, a notion that is crucial for dataflow systems that focus on deep learning applications. We describe the principles of an actual implementation of the technique in the TensorFlow framework, and present experimental results that demonstrate that the use of tagging is of paramount importance for developing efficient high-level abstractions for modern dataflow systems.
Packing Privacy Budget Efficiently
Dec 26, 2022



Machine learning (ML) models can leak information about users, and differential privacy (DP) provides a rigorous way to bound that leakage under a given budget. This DP budget can be regarded as a new type of compute resource in workloads of multiple ML models training on user data. Once it is used, the DP budget is forever consumed. Therefore, it is crucial to allocate it most efficiently to train as many models as possible. This paper presents the scheduler for privacy that optimizes for efficiency. We formulate privacy scheduling as a new type of multidimensional knapsack problem, called privacy knapsack, which maximizes DP budget efficiency. We show that privacy knapsack is NP-hard, hence practical algorithms are necessarily approximate. We develop an approximation algorithm for privacy knapsack, DPK, and evaluate it on microbenchmarks and on a new, synthetic private-ML workload we developed from the Alibaba ML cluster trace. We show that DPK: (1) often approaches the efficiency-optimal schedule, (2) consistently schedules more tasks compared to a state-of-the-art privacy scheduling algorithm that focused on fairness (1.3-1.7x in Alibaba, 1.0-2.6x in microbenchmarks), but (3) sacrifices some level of fairness for efficiency. Therefore, using DPK, DP ML operators should be able to train more models on the same amount of user data while offering the same privacy guarantee to their users.
DeepReduce: A Sparse-tensor Communication Framework for Distributed Deep Learning
Feb 05, 2021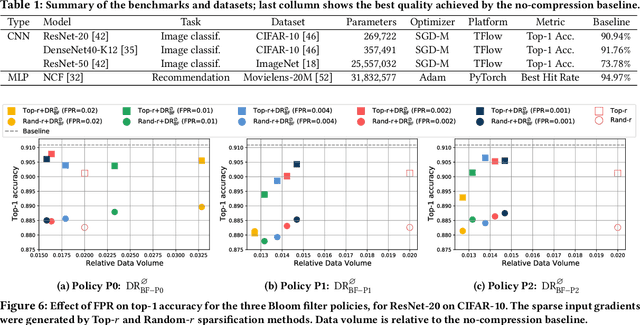
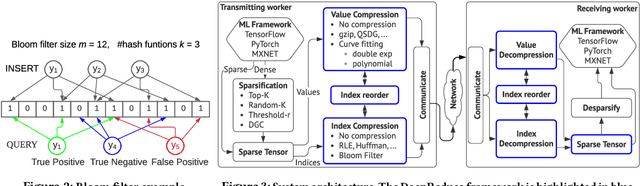
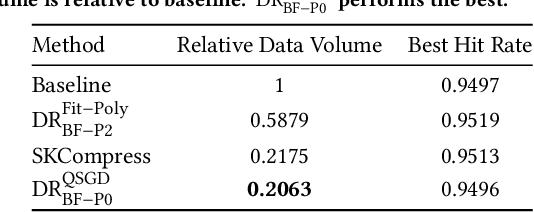
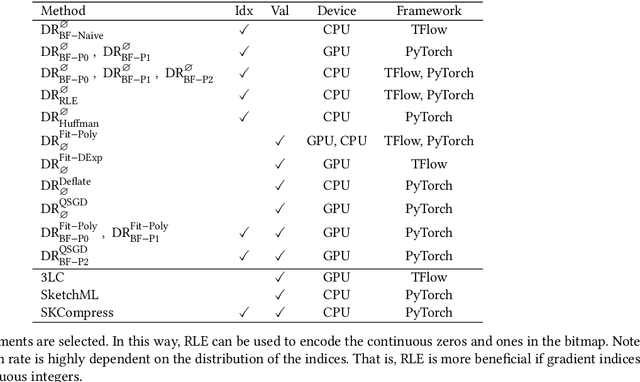
Sparse tensors appear frequently in distributed deep learning, either as a direct artifact of the deep neural network's gradients, or as a result of an explicit sparsification process. Existing communication primitives are agnostic to the peculiarities of deep learning; consequently, they impose unnecessary communication overhead. This paper introduces DeepReduce, a versatile framework for the compressed communication of sparse tensors, tailored for distributed deep learning. DeepReduce decomposes sparse tensors in two sets, values and indices, and allows both independent and combined compression of these sets. We support a variety of common compressors, such as Deflate for values, or run-length encoding for indices. We also propose two novel compression schemes that achieve superior results: curve fitting-based for values and bloom filter-based for indices. DeepReduce is orthogonal to existing gradient sparsifiers and can be applied in conjunction with them, transparently to the end-user, to significantly lower the communication overhead. As proof of concept, we implement our approach on Tensorflow and PyTorch. Our experiments with large real models demonstrate that DeepReduce transmits fewer data and imposes lower computational overhead than existing methods, without affecting the training accuracy.