 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLM-GNN Integration for Open-World Question Answering over Knowledge Graphs
Apr 15, 2026Open-world Question Answering (OW-QA) over knowledge graphs (KGs) aims to answer questions over incomplete or evolving KGs. Traditional KGQA assumes a closed world where answers must exist in the KG, limiting real-world applicability. In contrast, open-world QA requires inferring missing knowledge based on graph structure and context. Large language models (LLMs) excel at language understanding but lack structured reasoning. Graph neural networks (GNNs) model graph topology but struggle with semantic interpretation. Existing systems integrate LLMs with GNNs or graph retrievers. Some support open-world QA but rely on structural embeddings without semantic grounding. Most assume observed paths or complete graphs, making them unreliable under missing links or multi-hop reasoning. We present GLOW, a hybrid system that combines a pre-trained GNN and an LLM for open-world KGQA. The GNN predicts top-k candidate answers from the graph structure. These, along with relevant KG facts, are serialized into a structured prompt (e.g., triples and candidates) to guide the LLM's reasoning. This enables joint reasoning over symbolic and semantic signals, without relying on retrieval or fine-tuning. To evaluate generalization, we introduce GLOW-BENCH, a 1,000-question benchmark over incomplete KGs across diverse domains. GLOW outperforms existing LLM-GNN systems on standard benchmarks and GLOW-BENCH, achieving up to 53.3% and an average 38% improvement. GitHub code and data are available.
CHESS: Context-aware Hierarchical Efficient Semantic Selection for Long-Context LLM Inference
Feb 24, 2026Long-context LLMs demand accurate inference at low latency, yet decoding becomes primarily constrained by KV cache as context grows. Prior pruning methods are largely context-agnostic: their token selection ignores step-wise relevance and local semantics, which undermines quality. Moreover, their irregular accesses and selection overheads yield only limited wall-clock speedups. To address this, we propose \textbf{CHESS}, an \textit{algorithm-system co-design} KV-cache management system. Algorithmically, CHESS introduces a context-aware, hierarchical selection policy that dynamically reconstructs a coherent context for the current decoding. System-wise, coarse granularity selection eliminates expensive data movement, fully realizing practical acceleration from theoretical sparsity. Extensive evaluations demonstrate that CHESS surpasses Full-KV quality using only \textbf{1\%} of the KV cache, delivers low-latency stable inference with up to \textbf{4.56$\times$} higher throughput, and consistently outperforms other strong baselines. Code is available at \href{https://anonymous.4open.science/r/CHESS-9958/}{https://anonymous.4open.science/r/CHESS/}.
GraphComp: Extreme Error-bounded Compression of Scientific Data via Temporal Graph Autoencoders
May 08, 2025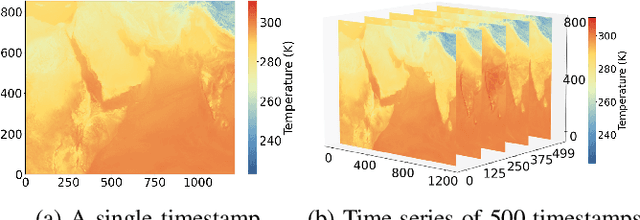
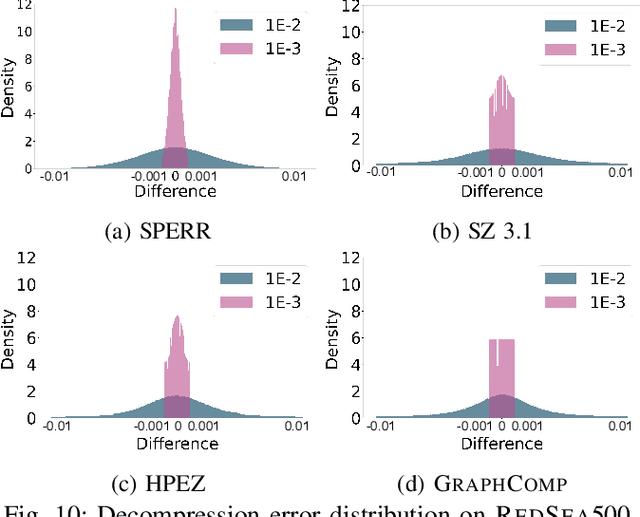
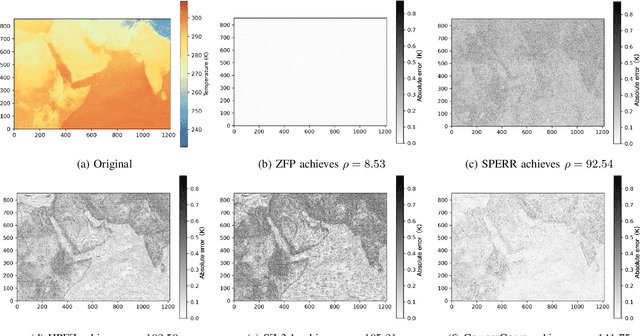
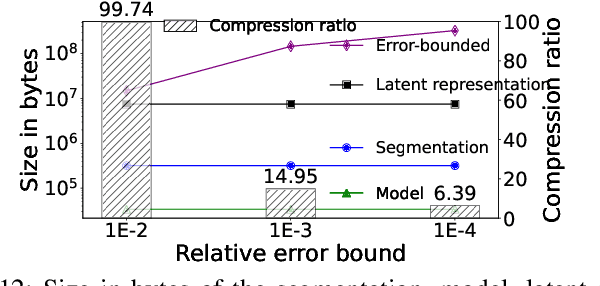
The generation of voluminous scientific data poses significant challenges for efficient storage, transfer, and analysis. Recently, error-bounded lossy compression methods emerged due to their ability to achieve high compression ratios while controlling data distortion. However, they often overlook the inherent spatial and temporal correlations within scientific data, thus missing opportunities for higher compression. In this paper we propose GRAPHCOMP, a novel graph-based method for error-bounded lossy compression of scientific data. We perform irregular segmentation of the original grid data and generate a graph representation that preserves the spatial and temporal correlations. Inspired by Graph Neural Networks (GNNs), we then propose a temporal graph autoencoder to learn latent representations that significantly reduce the size of the graph, effectively compressing the original data. Decompression reverses the process and utilizes the learnt graph model together with the latent representation to reconstruct an approximation of the original data. The decompressed data are guaranteed to satisfy a user-defined point-wise error bound. We compare our method against the state-of-the-art error-bounded lossy methods (i.e., HPEZ, SZ3.1, SPERR, and ZFP) on large-scale real and synthetic data. GRAPHCOMP consistently achieves the highest compression ratio across most datasets, outperforming the second-best method by margins ranging from 22% to 50%.
RED: Effective Trajectory Representation Learning with Comprehensive Information
Nov 22, 2024



Trajectory representation learning (TRL) maps trajectories to vectors that can then be used for various downstream tasks, including trajectory similarity computation, trajectory classification, and travel-time estimation. However, existing TRL methods often produce vectors that, when used in downstream tasks, yield insufficiently accurate results. A key reason is that they fail to utilize the comprehensive information encompassed by trajectories. We propose a self-supervised TRL framework, called RED, which effectively exploits multiple types of trajectory information. Overall, RED adopts the Transformer as the backbone model and masks the constituting paths in trajectories to train a masked autoencoder (MAE). In particular, RED considers the moving patterns of trajectories by employing a Road-aware masking strategy} that retains key paths of trajectories during masking, thereby preserving crucial information of the trajectories. RED also adopts a spatial-temporal-user joint Embedding scheme to encode comprehensive information when preparing the trajectories as model inputs. To conduct training, RED adopts Dual-objective task learning}: the Transformer encoder predicts the next segment in a trajectory, and the Transformer decoder reconstructs the entire trajectory. RED also considers the spatial-temporal correlations of trajectories by modifying the attention mechanism of the Transformer. We compare RED with 9 state-of-the-art TRL methods for 4 downstream tasks on 3 real-world datasets, finding that RED can usually improve the accuracy of the best-performing baseline by over 5%.
Task-Oriented GNNs Training on Large Knowledge Graphs for Accurate and Efficient Modeling
Mar 09, 2024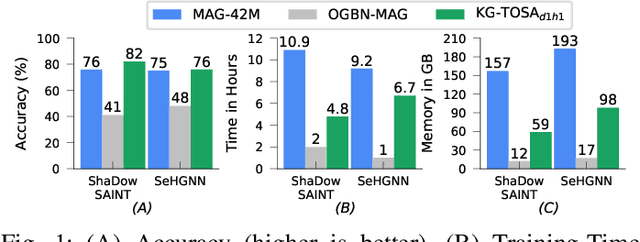
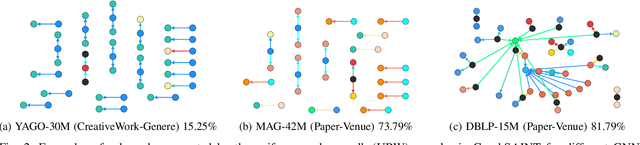
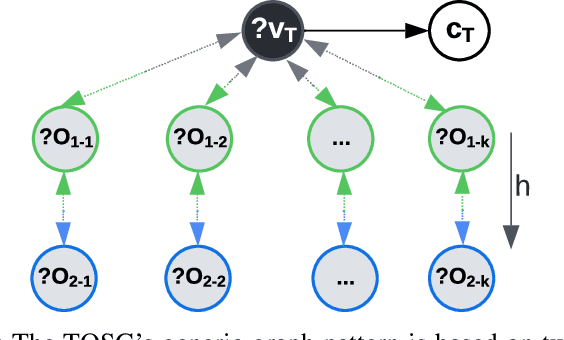
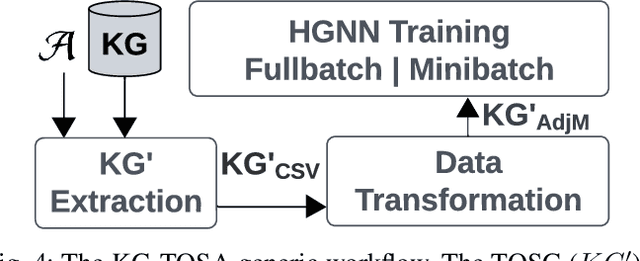
A Knowledge Graph (KG) is a heterogeneous graph encompassing a diverse range of node and edge types. Heterogeneous Graph Neural Networks (HGNNs) are popular for training machine learning tasks like node classification and link prediction on KGs. However, HGNN methods exhibit excessive complexity influenced by the KG's size, density, and the number of node and edge types. AI practitioners handcraft a subgraph of a KG G relevant to a specific task. We refer to this subgraph as a task-oriented subgraph (TOSG), which contains a subset of task-related node and edge types in G. Training the task using TOSG instead of G alleviates the excessive computation required for a large KG. Crafting the TOSG demands a deep understanding of the KG's structure and the task's objectives. Hence, it is challenging and time-consuming. This paper proposes KG-TOSA, an approach to automate the TOSG extraction for task-oriented HGNN training on a large KG. In KG-TOSA, we define a generic graph pattern that captures the KG's local and global structure relevant to a specific task. We explore different techniques to extract subgraphs matching our graph pattern: namely (i) two techniques sampling around targeted nodes using biased random walk or influence scores, and (ii) a SPARQL-based extraction method leveraging RDF engines' built-in indices. Hence, it achieves negligible preprocessing overhead compared to the sampling techniques. We develop a benchmark of real KGs of large sizes and various tasks for node classification and link prediction. Our experiments show that KG-TOSA helps state-of-the-art HGNN methods reduce training time and memory usage by up to 70% while improving the model performance, e.g., accuracy and inference time.
A Universal Question-Answering Platform for Knowledge Graphs
Mar 01, 2023



Knowledge from diverse application domains is organized as knowledge graphs (KGs) that are stored in RDF engines accessible in the web via SPARQL endpoints. Expressing a well-formed SPARQL query requires information about the graph structure and the exact URIs of its components, which is impractical for the average user. Question answering (QA) systems assist by translating natural language questions to SPARQL. Existing QA systems are typically based on application-specific human-curated rules, or require prior information, expensive pre-processing and model adaptation for each targeted KG. Therefore, they are hard to generalize to a broad set of applications and KGs. In this paper, we propose KGQAn, a universal QA system that does not need to be tailored to each target KG. Instead of curated rules, KGQAn introduces a novel formalization of question understanding as a text generation problem to convert a question into an intermediate abstract representation via a neural sequence-to-sequence model. We also develop a just-in-time linker that maps at query time the abstract representation to a SPARQL query for a specific KG, using only the publicly accessible APIs and the existing indices of the RDF store, without requiring any pre-processing. Our experiments with several real KGs demonstrate that KGQAn is easily deployed and outperforms by a large margin the state-of-the-art in terms of quality of answers and processing time, especially for arbitrary KGs, unseen during the training.
ChatGPT versus Traditional Question Answering for Knowledge Graphs: Current Status and Future Directions Towards Knowledge Graph Chatbots
Feb 08, 2023


Conversational AI and Question-Answering systems (QASs) for knowledge graphs (KGs) are both emerging research areas: they empower users with natural language interfaces for extracting information easily and effectively. Conversational AI simulates conversations with humans; however, it is limited by the data captured in the training datasets. In contrast, QASs retrieve the most recent information from a KG by understanding and translating the natural language question into a formal query supported by the database engine. In this paper, we present a comprehensive study of the characteristics of the existing alternatives towards combining both worlds into novel KG chatbots. Our framework compares two representative conversational models, ChatGPT and Galactica, against KGQAN, the current state-of-the-art QAS. We conduct a thorough evaluation using four real KGs across various application domains to identify the current limitations of each category of systems. Based on our findings, we propose open research opportunities to empower QASs with chatbot capabilities for KGs. All benchmarks and all raw results are available1 for further analysis.
Rethinking gradient sparsification as total error minimization
Aug 02, 2021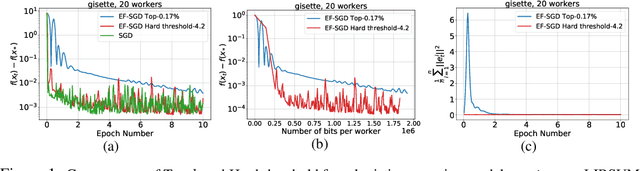

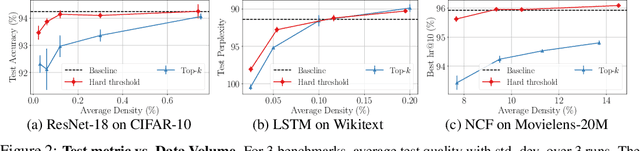
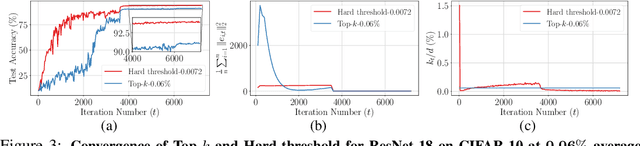
Gradient compression is a widely-established remedy to tackle the communication bottleneck in distributed training of large deep neural networks (DNNs). Under the error-feedback framework, Top-$k$ sparsification, sometimes with $k$ as little as $0.1\%$ of the gradient size, enables training to the same model quality as the uncompressed case for a similar iteration count. From the optimization perspective, we find that Top-$k$ is the communication-optimal sparsifier given a per-iteration $k$ element budget. We argue that to further the benefits of gradient sparsification, especially for DNNs, a different perspective is necessary -- one that moves from per-iteration optimality to consider optimality for the entire training. We identify that the total error -- the sum of the compression errors for all iterations -- encapsulates sparsification throughout training. Then, we propose a communication complexity model that minimizes the total error under a communication budget for the entire training. We find that the hard-threshold sparsifier, a variant of the Top-$k$ sparsifier with $k$ determined by a constant hard-threshold, is the optimal sparsifier for this model. Motivated by this, we provide convex and non-convex convergence analyses for the hard-threshold sparsifier with error-feedback. Unlike with Top-$k$ sparsifier, we show that hard-threshold has the same asymptotic convergence and linear speedup property as SGD in the convex case and has no impact on the data-heterogeneity in the non-convex case. Our diverse experiments on various DNNs and a logistic regression model demonstrated that the hard-threshold sparsifier is more communication-efficient than Top-$k$.
DeepReduce: A Sparse-tensor Communication Framework for Distributed Deep Learning
Feb 05, 2021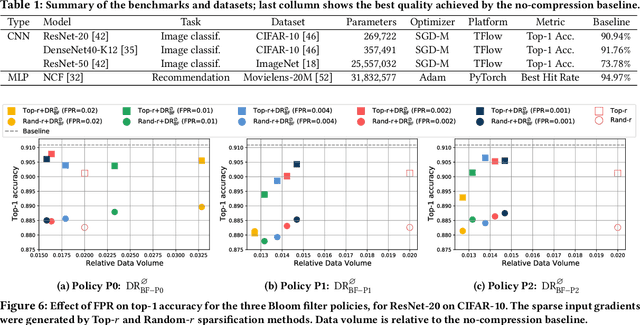
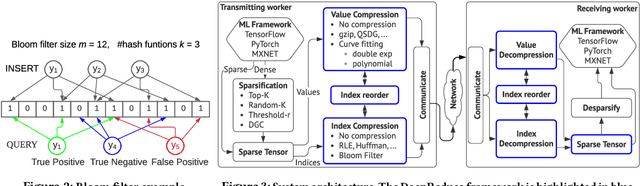
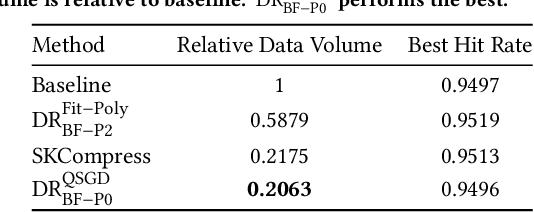
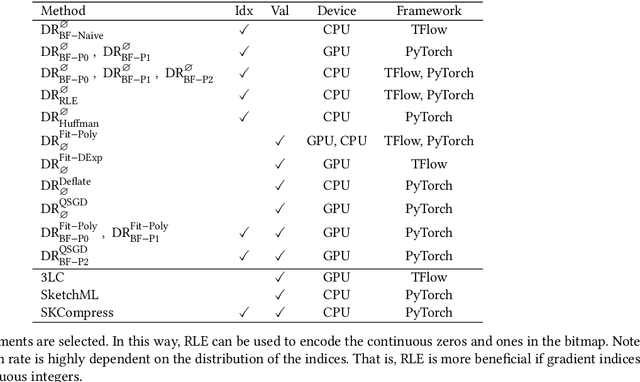
Sparse tensors appear frequently in distributed deep learning, either as a direct artifact of the deep neural network's gradients, or as a result of an explicit sparsification process. Existing communication primitives are agnostic to the peculiarities of deep learning; consequently, they impose unnecessary communication overhead. This paper introduces DeepReduce, a versatile framework for the compressed communication of sparse tensors, tailored for distributed deep learning. DeepReduce decomposes sparse tensors in two sets, values and indices, and allows both independent and combined compression of these sets. We support a variety of common compressors, such as Deflate for values, or run-length encoding for indices. We also propose two novel compression schemes that achieve superior results: curve fitting-based for values and bloom filter-based for indices. DeepReduce is orthogonal to existing gradient sparsifiers and can be applied in conjunction with them, transparently to the end-user, to significantly lower the communication overhead. As proof of concept, we implement our approach on Tensorflow and PyTorch. Our experiments with large real models demonstrate that DeepReduce transmits fewer data and imposes lower computational overhead than existing methods, without affecting the training accuracy.
On the Discrepancy between the Theoretical Analysis and Practical Implementations of Compressed Communication for Distributed Deep Learning
Nov 19, 2019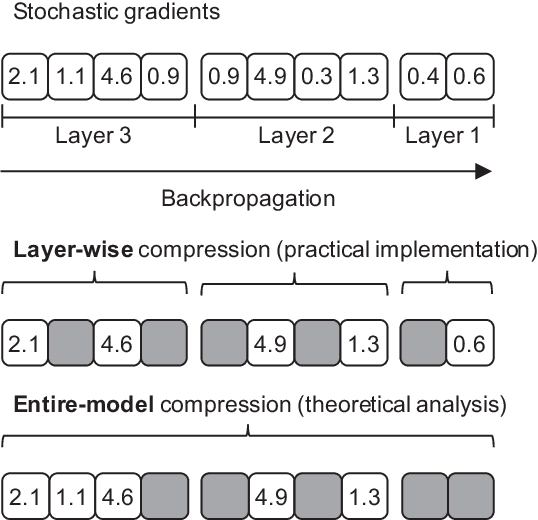
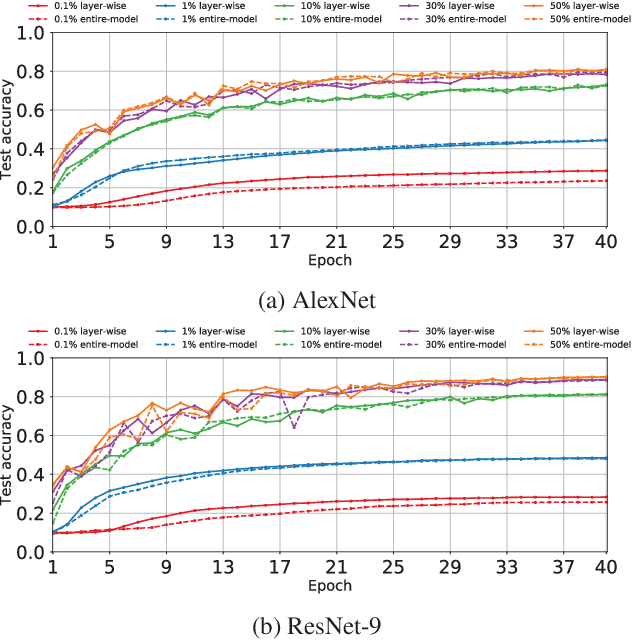
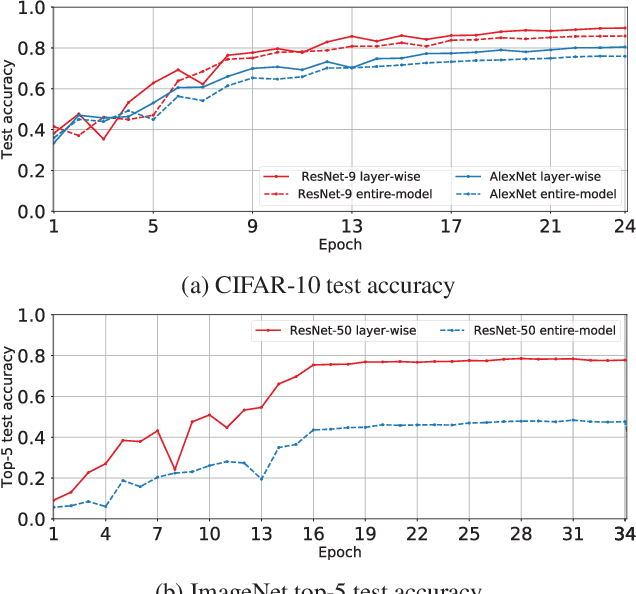
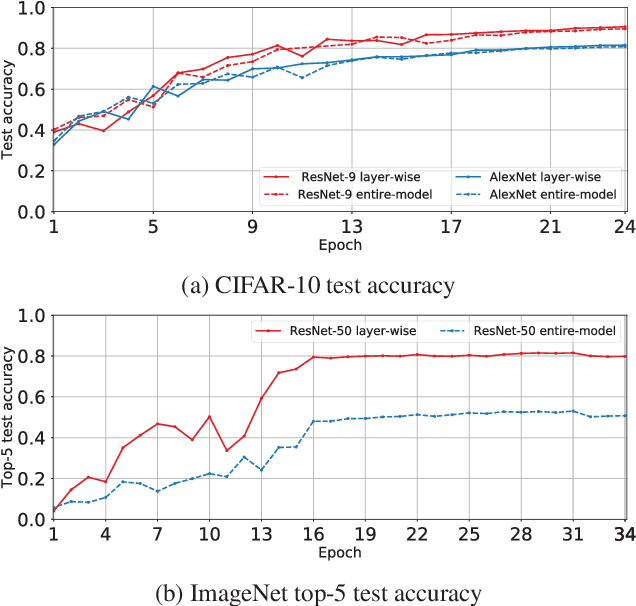
Compressed communication, in the form of sparsification or quantization of stochastic gradients, is employed to reduce communication costs in distributed data-parallel training of deep neural networks. However, there exists a discrepancy between theory and practice: while theoretical analysis of most existing compression methods assumes compression is applied to the gradients of the entire model, many practical implementations operate individually on the gradients of each layer of the model. In this paper, we prove that layer-wise compression is, in theory, better, because the convergence rate is upper bounded by that of entire-model compression for a wide range of biased and unbiased compression methods. However, despite the theoretical bound, our experimental study of six well-known methods shows that convergence, in practice, may or may not be better, depending on the actual trained model and compression ratio. Our findings suggest that it would be advantageous for deep learning frameworks to include support for both layer-wise and entire-model compression.
* To Appear In Proceedings of Thirty-Fourth AAAI Conference on Artificial Intelligence, 2020