 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSynthesizing Collective Communication Algorithms for Heterogeneous Networks with TACCL
Nov 15, 2021
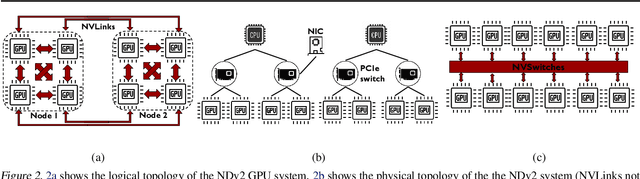
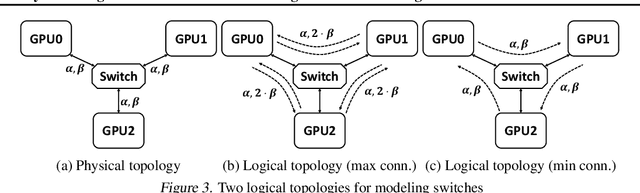
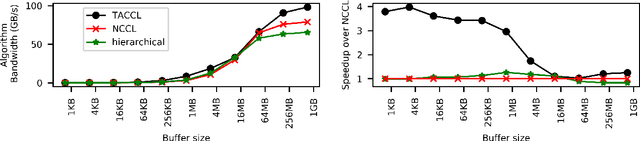
Large ML models and datasets have necessitated the use of multi-GPU systems for distributed model training. To harness the power offered by multi-GPU systems, it is critical to eliminate bottlenecks in inter-GPU communication - a problem made challenging by the heterogeneous nature of interconnects. In this work, we present TACCL, a synthesizer for collective communication primitives for large-scale multi-GPU systems. TACCL encodes a profiled topology and input size into a synthesis problem to generate optimized communication algorithms. TACCL is built on top of the standard NVIDIA Collective Communication Library (NCCL), allowing it to be a drop-in replacement for GPU communication in frameworks like PyTorch with minimal changes. TACCL generates algorithms for communication primitives like Allgather, Alltoall, and Allreduce that are up to $3\times$ faster than NCCL. Using TACCL's algorithms speeds up the end-to-end training of an internal mixture of experts model by $17\%$. By decomposing the optimization problem into parts and leveraging the symmetry in multi-GPU topologies, TACCL synthesizes collectives for up to 80-GPUs in less than 3 minutes, at least two orders of magnitude faster than other synthesis-based state-of-the-art collective communication libraries.
Cloud Collectives: Towards Cloud-aware Collectives forML Workloads with Rank Reordering
May 28, 2021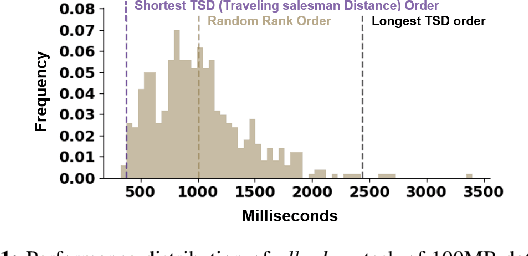


ML workloads are becoming increasingly popular in the cloud. Good cloud training performance is contingent on efficient parameter exchange among VMs. We find that Collectives, the widely used distributed communication algorithms, cannot perform optimally out of the box due to the hierarchical topology of datacenter networks and multi-tenancy nature of the cloudenvironment.In this paper, we present Cloud Collectives , a prototype that accelerates collectives by reordering theranks of participating VMs such that the communication pattern dictated by the selected collectives operation best exploits the locality in the network.Collectives is non-intrusive, requires no code changes nor rebuild of an existing application, and runs without support from cloud providers. Our preliminary application of Cloud Collectives on allreduce operations in public clouds results in a speedup of up to 3.7x in multiple microbenchmarks and 1.3x in real-world workloads of distributed training of deep neural networks and gradient boosted decision trees using state-of-the-art frameworks.
Scaling Distributed Machine Learning with In-Network Aggregation
Feb 22, 2019
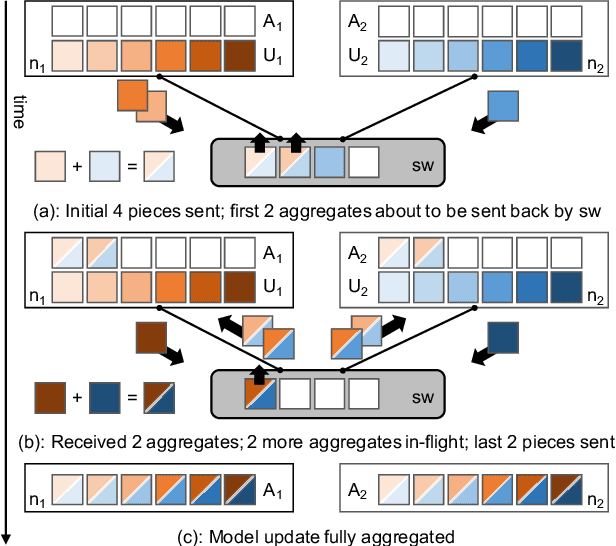
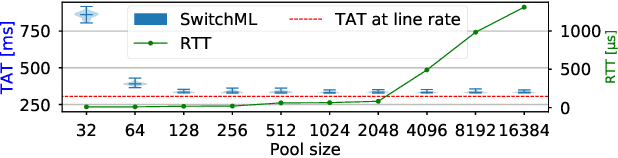
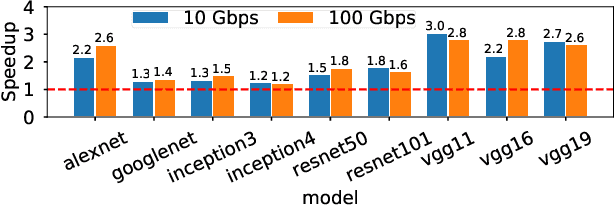
Training complex machine learning models in parallel is an increasingly important workload. We accelerate distributed parallel training by designing a communication primitive that uses a programmable switch dataplane to execute a key step of the training process. Our approach, SwitchML, reduces the volume of exchanged data by aggregating the model updates from multiple workers in the network. We co-design the switch processing with the end-host protocols and ML frameworks to provide a robust, efficient solution that speeds up training by up to 300%, and at least by 20% for a number of real-world benchmark models.
Parameter Hub: a Rack-Scale Parameter Server for Distributed Deep Neural Network Training
May 21, 2018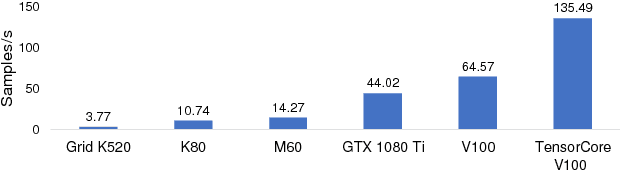

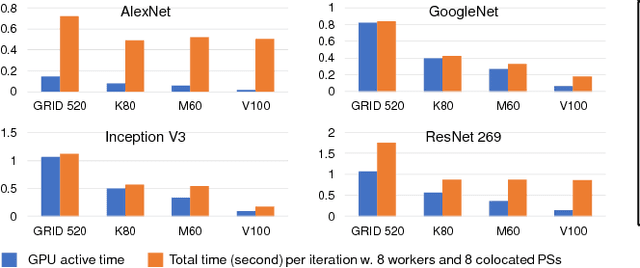
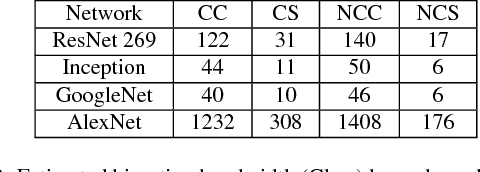
Distributed deep neural network (DDNN) training constitutes an increasingly important workload that frequently runs in the cloud. Larger DNN models and faster compute engines are shifting DDNN training bottlenecks from computation to communication. This paper characterizes DDNN training to precisely pinpoint these bottlenecks. We found that timely training requires high performance parameter servers (PSs) with optimized network stacks and gradient processing pipelines, as well as server and network hardware with balanced computation and communication resources. We therefore propose PHub, a high performance multi-tenant, rack-scale PS design. PHub co-designs the PS software and hardware to accelerate rack-level and hierarchical cross-rack parameter exchange, with an API compatible with many DDNN training frameworks. PHub provides a performance improvement of up to 2.7x compared to state-of-the-art distributed training techniques for cloud-based ImageNet workloads, with 25% better throughput per dollar.