 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
Hybrid Architectures for Language Models: Systematic Analysis and Design Insights
Oct 06, 2025Recent progress in large language models demonstrates that hybrid architectures--combining self-attention mechanisms with structured state space models like Mamba--can achieve a compelling balance between modeling quality and computational efficiency, particularly for long-context tasks. While these hybrid models show promising performance, systematic comparisons of hybridization strategies and analyses on the key factors behind their effectiveness have not been clearly shared to the community. In this work, we present a holistic evaluation of hybrid architectures based on inter-layer (sequential) or intra-layer (parallel) fusion. We evaluate these designs from a variety of perspectives: language modeling performance, long-context capabilities, scaling analysis, and training and inference efficiency. By investigating the core characteristics of their computational primitive, we identify the most critical elements for each hybridization strategy and further propose optimal design recipes for both hybrid models. Our comprehensive analysis provides practical guidance and valuable insights for developing hybrid language models, facilitating the optimization of architectural configurations.
SSG-Dit: A Spatial Signal Guided Framework for Controllable Video Generation
Aug 23, 2025Controllable video generation aims to synthesize video content that aligns precisely with user-provided conditions, such as text descriptions and initial images. However, a significant challenge persists in this domain: existing models often struggle to maintain strong semantic consistency, frequently generating videos that deviate from the nuanced details specified in the prompts. To address this issue, we propose SSG-DiT (Spatial Signal Guided Diffusion Transformer), a novel and efficient framework for high-fidelity controllable video generation. Our approach introduces a decoupled two-stage process. The first stage, Spatial Signal Prompting, generates a spatially aware visual prompt by leveraging the rich internal representations of a pre-trained multi-modal model. This prompt, combined with the original text, forms a joint condition that is then injected into a frozen video DiT backbone via our lightweight and parameter-efficient SSG-Adapter. This unique design, featuring a dual-branch attention mechanism, allows the model to simultaneously harness its powerful generative priors while being precisely steered by external spatial signals. Extensive experiments demonstrate that SSG-DiT achieves state-of-the-art performance, outperforming existing models on multiple key metrics in the VBench benchmark, particularly in spatial relationship control and overall consistency.
Phantora: Live GPU Cluster Simulation for Machine Learning System Performance Estimation
May 02, 2025To accommodate ever-increasing model complexity, modern machine learning (ML) systems have to scale to large GPU clusters. Changes in ML model architecture, ML system implementation, and cluster configuration can significantly affect overall ML system performance. However, quantifying the performance impact before deployment is challenging. Existing performance estimation methods use performance modeling or static workload simulation. These techniques are not general: they requires significant human effort and computation capacity to generate training data or a workload. It is also difficult to adapt ML systems to use these techniques. This paper introduces, Phantora, a live GPU cluster simulator for performance estimation. Phantora runs minimally modified ML models and frameworks, intercepting and simulating GPU-related operations to enable high-fidelity performance estimation. Phantora overcomes several research challenges in integrating an event-driven network simulator with live system execution, and introduces a set of techniques to improve simulation speed, scalability, and accuracy. Our evaluation results show that Phantora can deliver similar estimation accuracy to the state-of-the-art workload simulation approach with only one GPU, while reducing human effort and increasing generalizability.
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Feb 26, 2025



Ads recommendation is a prominent service of online advertising systems and has been actively studied. Recent studies indicate that scaling-up and advanced design of the recommendation model can bring significant performance improvement. However, with a larger model scale, such prior studies have a significantly increasing gap from industry as they often neglect two fundamental challenges in industrial-scale applications. First, training and inference budgets are restricted for the model to be served, exceeding which may incur latency and impair user experience. Second, large-volume data arrive in a streaming mode with data distributions dynamically shifting, as new users/ads join and existing users/ads leave the system. We propose the External Large Foundation Model (ExFM) framework to address the overlooked challenges. Specifically, we develop external distillation and a data augmentation system (DAS) to control the computational cost of training/inference while maintaining high performance. We design the teacher in a way like a foundation model (FM) that can serve multiple students as vertical models (VMs) to amortize its building cost. We propose Auxiliary Head and Student Adapter to mitigate the data distribution gap between FM and VMs caused by the streaming data issue. Comprehensive experiments on internal industrial-scale applications and public datasets demonstrate significant performance gain by ExFM.
The Efficiency vs. Accuracy Trade-off: Optimizing RAG-Enhanced LLM Recommender Systems Using Multi-Head Early Exit
Jan 04, 2025



The deployment of Large Language Models (LLMs) in recommender systems for predicting Click-Through Rates (CTR) necessitates a delicate balance between computational efficiency and predictive accuracy. This paper presents an optimization framework that combines Retrieval-Augmented Generation (RAG) with an innovative multi-head early exit architecture to concurrently enhance both aspects. By integrating Graph Convolutional Networks (GCNs) as efficient retrieval mechanisms, we are able to significantly reduce data retrieval times while maintaining high model performance. The early exit strategy employed allows for dynamic termination of model inference, utilizing real-time predictive confidence assessments across multiple heads. This not only quickens the responsiveness of LLMs but also upholds or improves their accuracy, making it ideal for real-time application scenarios. Our experiments demonstrate how this architecture effectively decreases computation time without sacrificing the accuracy needed for reliable recommendation delivery, establishing a new standard for efficient, real-time LLM deployment in commercial systems.
Mixture-of-Transformers: A Sparse and Scalable Architecture for Multi-Modal Foundation Models
Nov 07, 2024

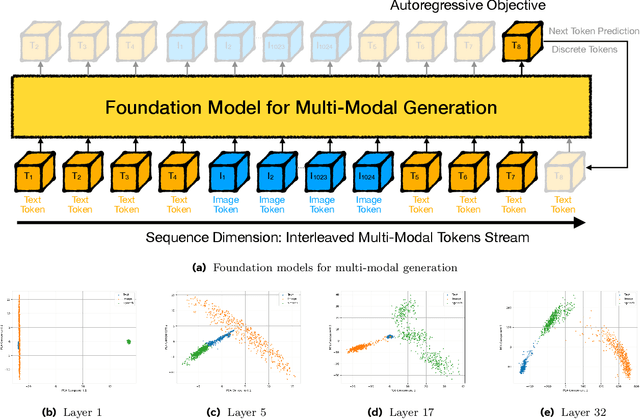

The development of large language models (LLMs) has expanded to multi-modal systems capable of processing text, images, and speech within a unified framework. Training these models demands significantly larger datasets and computational resources compared to text-only LLMs. To address the scaling challenges, we introduce Mixture-of-Transformers (MoT), a sparse multi-modal transformer architecture that significantly reduces pretraining computational costs. MoT decouples non-embedding parameters of the model by modality -- including feed-forward networks, attention matrices, and layer normalization -- enabling modality-specific processing with global self-attention over the full input sequence. We evaluate MoT across multiple settings and model scales. In the Chameleon 7B setting (autoregressive text-and-image generation), MoT matches the dense baseline's performance using only 55.8\% of the FLOPs. When extended to include speech, MoT reaches speech performance comparable to the dense baseline with only 37.2\% of the FLOPs. In the Transfusion setting, where text and image are trained with different objectives, a 7B MoT model matches the image modality performance of the dense baseline with one third of the FLOPs, and a 760M MoT model outperforms a 1.4B dense baseline across key image generation metrics. System profiling further highlights MoT's practical benefits, achieving dense baseline image quality in 47.2\% of the wall-clock time and text quality in 75.6\% of the wall-clock time (measured on AWS p4de.24xlarge instances with NVIDIA A100 GPUs).
MoMa: Efficient Early-Fusion Pre-training with Mixture of Modality-Aware Experts
Jul 31, 2024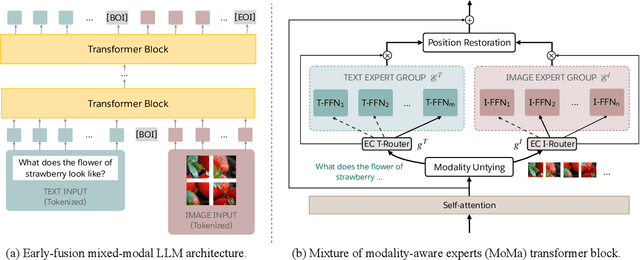

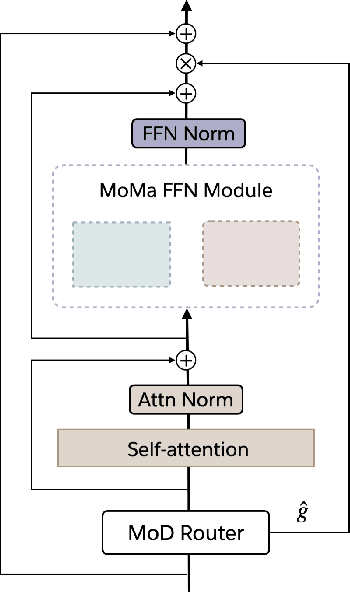
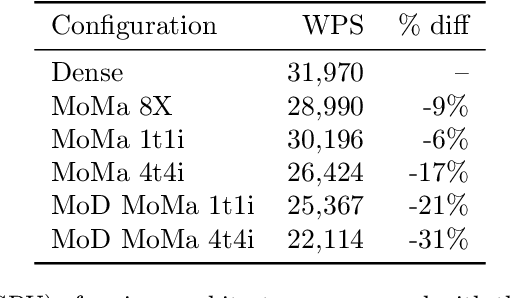
We introduce MoMa, a novel modality-aware mixture-of-experts (MoE) architecture designed for pre-training mixed-modal, early-fusion language models. MoMa processes images and text in arbitrary sequences by dividing expert modules into modality-specific groups. These groups exclusively process designated tokens while employing learned routing within each group to maintain semantically informed adaptivity. Our empirical results reveal substantial pre-training efficiency gains through this modality-specific parameter allocation. Under a 1-trillion-token training budget, the MoMa 1.4B model, featuring 4 text experts and 4 image experts, achieves impressive FLOPs savings: 3.7x overall, with 2.6x for text and 5.2x for image processing compared to a compute-equivalent dense baseline, measured by pre-training loss. This outperforms the standard expert-choice MoE with 8 mixed-modal experts, which achieves 3x overall FLOPs savings (3x for text, 2.8x for image). Combining MoMa with mixture-of-depths (MoD) further improves pre-training FLOPs savings to 4.2x overall (text: 3.4x, image: 5.3x), although this combination hurts performance in causal inference due to increased sensitivity to router accuracy. These results demonstrate MoMa's potential to significantly advance the efficiency of mixed-modal, early-fusion language model pre-training, paving the way for more resource-efficient and capable multimodal AI systems.
Wukong: Towards a Scaling Law for Large-Scale Recommendation
Mar 08, 2024



Scaling laws play an instrumental role in the sustainable improvement in model quality. Unfortunately, recommendation models to date do not exhibit such laws similar to those observed in the domain of large language models, due to the inefficiencies of their upscaling mechanisms. This limitation poses significant challenges in adapting these models to increasingly more complex real-world datasets. In this paper, we propose an effective network architecture based purely on stacked factorization machines, and a synergistic upscaling strategy, collectively dubbed Wukong, to establish a scaling law in the domain of recommendation. Wukong's unique design makes it possible to capture diverse, any-order of interactions simply through taller and wider layers. We conducted extensive evaluations on six public datasets, and our results demonstrate that Wukong consistently outperforms state-of-the-art models quality-wise. Further, we assessed Wukong's scalability on an internal, large-scale dataset. The results show that Wukong retains its superiority in quality over state-of-the-art models, while holding the scaling law across two orders of magnitude in model complexity, extending beyond 100 Gflop or equivalently up to Large Language Model (GPT-3) training compute scale, where prior arts fall short.
Disaggregated Multi-Tower: Topology-aware Modeling Technique for Efficient Large-Scale Recommendation
Mar 07, 2024



We study a mismatch between the deep learning recommendation models' flat architecture, common distributed training paradigm and hierarchical data center topology. To address the associated inefficiencies, we propose Disaggregated Multi-Tower (DMT), a modeling technique that consists of (1) Semantic-preserving Tower Transform (SPTT), a novel training paradigm that decomposes the monolithic global embedding lookup process into disjoint towers to exploit data center locality; (2) Tower Module (TM), a synergistic dense component attached to each tower to reduce model complexity and communication volume through hierarchical feature interaction; and (3) Tower Partitioner (TP), a feature partitioner to systematically create towers with meaningful feature interactions and load balanced assignments to preserve model quality and training throughput via learned embeddings. We show that DMT can achieve up to 1.9x speedup compared to the state-of-the-art baselines without losing accuracy across multiple generations of hardware at large data center scales.